In “How HashMap works in Java“, we learned the internals of HashMap or ConcurrentHashMap class and how they fit into the whole concept. But when the interviewer asks you about HashMap related concepts, he does not stop only on the core concept. The discussion usually goes in multiple directions to understand whether you really understand the concept or not.
In this post, we will try to cover some related interview questions on HashMap and ConcurrentHashMap.
1. How to Design a Good Key for HashMap
The very basic need for designing a good key is that “we should be able to retrieve the value object back from the map without failure“, right?? Otherwise no matter how fancy the data structure you build, it will be of no use.
Key’s hashcode() is used primarily in conjunction with its equals() method, for putting a key in the Map and then searching it back from Map. So if the hashcode of the key object changes after we have put a key-value pair in the Map, then it is almost impossible to fetch the value object back from the Map. It will also cause a memory leak. To avoid this, map keys should be immutable. These are a few things to create an immutable class.
This is the main reason why immutable classes like String, Integer or other wrapper classes are good candidates for creating the Map Keys.
But remember that immutability is recommended but not mandatory. If we want to make a mutable object as a key in a Map, then we have to make sure that the state change for the key object does not change the hashcode of object. This can be done by overriding the hashCode() method. Also, key class must honor the hashCode() and equals() methods contract to avoid the undesired and surprising behavior on run time.
More detailed information is available here.
2. Difference between HashMap and ConcurrentHashMap?
To better visualize the ConcurrentHashMap, let it consider as a group of HashMap instances. To get and put key-value pairs from hashmap, we have to calculate the hashcode and look for correct bucket location in array of Collection.Entry.
In ConcurrentHashMap, the difference lies in the internal structure to store these key-value pairs. ConcurrentHashMap has an additional concept of segments.
It will be easier to understand it you think of one segment equal to one HashMap [conceptually]. A concurrentHashMap is divided into number of segments [default 16] on initialization. ConcurrentHashMap allows similar number (16) of threads to access these segments concurrently so that each thread work on a specific segment during high concurrency.
This way, if when your key-value pair is stored in segment 10; code does not need to block other 15 segments additionally. This structure provides a very high level of concurrency.
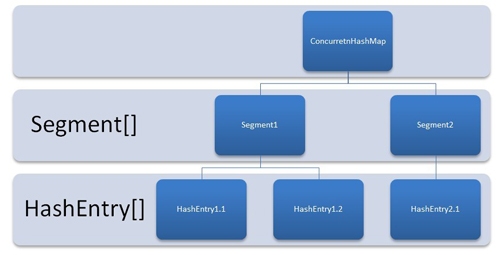
In other words, ConcurrentHashMap uses a multitude of locks, each lock controls one segment of the map. When setting data in a particular segment, the lock for that segment is obtained. So essentially update operations are synchronized.
When getting data, a volatile read is used without any synchronization. If the volatile read results in a miss, then the lock for that segment is obtained and entry is again searched in synchronized block.
3. Difference between HashMap and Collections.synchronizedMap()?
HashMap is non-synchronized and Collections.synchronizedMap() returns a wrapped instance of HashMap which has all get, put methods synchronized.
Essentially, Collections.synchronizedMap() returns the reference of internally created inner-class “SynchronizedMap”, which contains key-value pairs of input HashMap, passed as argument.
This instance of inner class has nothing to do with original parameter HashMap instance and is completely independent.
4. Difference between ConcurrentHashMap and Collections.synchronizedMap()?
This one is a slightly complex question. Both are synchronized version of HashMap, with difference in their core functionality and internal structure.
As stated above, ConcurrentHashMap is consist of internal segments which can be viewed as independent HashMap instances, conceptually. All such segments can be locked by separate threads in high concurrent executions. In this way, multiple threads can get/put key-value pairs from ConcurrentHashMap without blocking/waiting for each other.
In Collections.synchronizedMap(), we get a synchronized version of HashMap and it is accessed in blocking manner. This means if multiple threads try to access synchronizedMap at same time, they will be allowed to get/put key-value pairs one at a time in synchronized manner.
5. Difference between HashMap and HashTable
It is also very easy question. The major difference is that HashTable is synchronized and HashMap is not.
If asked for other reasons, tell them, HashTable is legacy class (part of JDK 1.0) which was promoted into collections framework by implementing Map interface later. It still has some extra features like Enumerator with it, which HashMap lacks.
Another minor reason can be: HashMap supports null key (mapped to zero bucket), HashTable does not support null keys and throws NullPointerException on such attempt.
6. Difference between HashTable and Collections.synchronized(Map)?
Both are synchronized version of collection. Both have synchronized methods inside class. Both are blocking in nature i.e. multiple threads will need to wait for getting the lock on instance before putting/getting anything out of it.
So what is the difference. Well, NO major difference for above said reasons. Performance is also same for both collections.
Only thing which separates them is the fact HashTable is legacy class promoted into collection framework. It got its own extra features like enumerators.
7. Impact of Random or Fixed hashcode()?
The impact of both cases (fixed hashcode or random hashcode for keys) will have same result and that is “unexpected behavior“. The very basic need of hashcode in HashMap is to identify the bucket location where to put the key-value pair, and from where it has to be retrieved.
If the hashcode of key object changes every time, the exact location of key-value pair will be calculated different, every time. This way, one object stored in HashMap will be lost forever and there will be very minimum possibility to get it back from map.
If hashcode() is a fixed value for all objects, then all the objects will be stored in a single bucket that will degrade the Map performance.
For this same reason, key are suggested to be immutable, so that they return a unique and same hashcode each time requested on the same key object.
8. Can we use HashMap in Concurrent Application?
In normal cases, concurrent accesses can leave the hashmap in inconsistent state where key-value pairs added and retrieved can be different. Apart from this, other surprising behavior like NullPointerException can come into picture.
In worst case, It can cause infinite loop. YES. You got it right. It can cause infinite loop. What did you asked, How?? Well, here is the reason.
HashMap has the concept of rehashing when it reaches to its upper limit of size. This rehashing is the process of creating a new memory area, and copying all the already present key-value pairs in new memory are.
Let’s say thread A tried to put a key-value pair in map and then rehashing started. At the same time, thread B came and started manipulating the buckets using put() operation.
Here while rehashing process, there are chances to generate the cyclic dependency where one element in linked list [in any bucket] can point to any previous node in same bucket. This will result in infinite loop, because rehashing code contains a “while(true) { //get next node; }” block and in cyclic dependency it will run infinite.
To watch closely, look at source code of transfer method which is used in rehashing:
public Object get(Object key) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
Entry e = table[i];
//While true is always a bad practice and cause infinite loops
while (true) {
if (e == null)
return e;
if (e.hash == hash & eq(k, e.key))
return e.value;
e = e.next;
}
}I hope I was able to put some more items on your knowledge bucket for hashmap interview questions and ConcurrentHashMap interview questions. If you find this article helpful, please consider it sharing with your friends.
Happy Learning !!
Comments