Learn to create a web scrapper application in Java. The web scrapper, developed in this tutorial, does the following actions:
- Reads an Excel file and root URLs from a specified column
- Creates new Runnable Task and submits to thread pool executor
- Creates BlockingThreadPoolExecutor with Semaphore to enable task throttling
- Task fetches the first 20 links from the root URL
- Task hits all 20 URLs and extracts the page Title for each page
- Periodically check the finished URLs and writes the visited URL and its title in an Excel report
This application must not be used in production because there are a lot of improvement areas. Use this code as a conceptual reference for how to build a web scrapper.
Feel free to replace or modify any part of the demo application according to your needs.
1. Maven Dependencies
Start with including the latest version of the following dependencies:
- org.apache.poi:poi : For reading and writing excel files.
- org.apache.poi:poi-ooxml : Supports reading the excel file using SAX parser.
- io.rest-assured:rest-assured : For invoking URLs and capturing outputs.
- org.jsoup:jsoup : For parsing and extracting the information from HTML document.
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>2. Reading Input and Submit for Processing
The scrapper reads the root URLs from the excel file and creates a UrlRecord instance. For each UrlRecord, a new ScrapTask thread is created and handed over to BlockingThreadPoolExecutor for invoking the URLs and extracting titles.
2.1. Reading Input from Excel
The application uses SAX parser API to read the excel, so if the excel file is too big, we do not get OutOfMemory errors. We are only listing the relevant code snippets. For complete listing, visit the Github repository.
public class WebScrappingApp {
public static void main(String[] args) throws Exception {
...
RowHandler handler = new RowHandler();
handler.readExcelFile("C:\\temp\\webscrapping-root-urls.xlsx");
...
}
}public class RowHandler extends SheetHandler {
protected Map<String, String> headerRowMapping = new HashedMap<>();
...
@Override
protected void processRow() throws ExecutionException, InterruptedException {
//Assuming that first row is column names
if (rowNumber > 1 && !rowValues.isEmpty()) {
String url = rowValues.get("B");
if(url != null && !url.trim().equals("")) {
UrlRecord entity = new UrlRecord();
entity.setRownum((int) rowNumber);
entity.setRootUrl(url.trim()); //root URL
JobSubmitter.submitTask(entity);
}
}
}
}public class SheetHandler extends DefaultHandler {
...
public void readExcelFile(String filename) throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
try (OPCPackage opcPackage = OPCPackage.open(filename)) {
XSSFReader xssfReader = new XSSFReader(opcPackage);
sharedStringsTable = (SharedStringsTable) xssfReader.getSharedStringsTable();
stylesTable = xssfReader.getStylesTable();
ContentHandler handler = this;
Iterator<InputStream> sheets = xssfReader.getSheetsData();
if (sheets instanceof XSSFReader.SheetIterator) {
XSSFReader.SheetIterator sheetIterator = (XSSFReader.SheetIterator) sheets;
while (sheetIterator.hasNext()) {
try (InputStream sheet = sheetIterator.next()) {
sheetName = sheetIterator.getSheetName();
sheetNumber++;
startSheet();
saxParser.parse(sheet, (DefaultHandler) handler);
endSheet();
}
}
}
}
}
}2.2. Submitting for Execution
Notice the JobSubmitter.submitTask() statement in RowHandler‘s processRow() method. The JobSubmitter is responsible for submitting the task to the BlockingThreadPoolExecutor.
public class JobSubmitter {
public static List<Future<?>> futures = new ArrayList<Future<?>>();
static BlockingQueue<Runnable> blockingQueue = new LinkedBlockingQueue<Runnable>(25000);
static BlockingThreadPoolExecutor executor
= new BlockingThreadPoolExecutor(5,10, 10000, TimeUnit.MILLISECONDS, blockingQueue);
static {
executor.setRejectedExecutionHandler(new RejectedExecutionHandler()
{
...
});
// Let start all core threads initially
executor.prestartAllCoreThreads();
}
public static void submitTask(UrlRecord entity) {
Future<?> f = executor.submit(new ScrapTask(entity));
futures.add(f);
}
}BlockingThreadPoolExecutor is a custom implementation of ThreadPoolExecutor that supports task throttling, so we do not overrun the number of available resources such as HTTP connections.
public class BlockingThreadPoolExecutor extends ThreadPoolExecutor {
private final Semaphore semaphore;
public BlockingThreadPoolExecutor(int corePoolSize, int maximumPoolSize,
long keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
semaphore = new Semaphore(10);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
}
@Override
public void execute(final Runnable task) {
boolean acquired = false;
do {
try {
Thread.sleep(1000);
semaphore.acquire();
acquired = true;
} catch (final InterruptedException e) {
System.out.println("InterruptedException whilst aquiring semaphore" + e);
}
} while (!acquired);
try {
super.execute(task);
} catch (final RejectedExecutionException e) {
System.out.println("Task Rejected");
semaphore.release();
throw e;
}
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
if (t != null) {
t.printStackTrace();
}
semaphore.release();
}
}3. Scrapping the URLs
The actual processing happens in the ScrapTask class which is a thread and executed by the executor. ScrapTask invokes the URLs and scraps the content. All custom logic for scrapping resides here.
public class ScrapTask implements Runnable {
public ScrapTask(UrlRecord entity) {
this.entity = entity;
}
private UrlRecord entity;
public UrlRecord getEntity() {
return entity;
}
public void setEntity(UrlRecord entity) {
this.entity = entity;
}
static String[] tokens = new String[]{" private", "pvt.", " pvt",
" limited", "ltd.", " ltd"};
static RestAssuredConfig config = RestAssured.config()
.httpClient(HttpClientConfig.httpClientConfig()
.setParam(CoreConnectionPNames.CONNECTION_TIMEOUT, 30000)
.setParam(CoreConnectionPNames.SO_TIMEOUT, 30000));
@Override
public void run() {
try {
loadPagesAndGetTitles(entity.getRootUrl());
} catch (Exception e) {
e.printStackTrace();
}
}
private void loadPagesAndGetTitles(String rootUrl) {
try{
Response response = given()
.config(config)
.when()
.get(rootUrl)
.then()
.log().ifError()
.contentType(ContentType.HTML).
extract().response();
Document document = Jsoup.parse(response.getBody().asString());
Elements anchors = document.getElementsByTag("a");
if (anchors != null && anchors.size() > 0) {
for (int i = 0; i < anchors.size() && i < 20; i++) {
String visitedUrl = anchors.get(i).attributes().get("href");
if(visitedUrl.startsWith("/")) {
String title = getTitle(rootUrl + visitedUrl);
UrlRecord newEntity = new UrlRecord();
newEntity.setRownum(WebScrappingApp.rowCounter++);
newEntity.setRootUrl(entity.getRootUrl());
newEntity.setVisitedUrl(rootUrl + visitedUrl);
newEntity.setTitle(title);
System.out.println("Fetched Record: " + newEntity);
WebScrappingApp.processedRecords.add(newEntity);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
private String getTitle(String url) {
try {
Response response = given()
.config(config)
.when()
.get(url)
.then()
.log().ifError()
.contentType(ContentType.HTML).
extract().response();
Document document = Jsoup.parse(response.getBody().asString());
Elements titles = document.getElementsByTag("title");
if (titles != null && titles.size() > 0) {
return titles.get(0).text();
}
}
catch (Exception e) {
e.printStackTrace();
}
return "Not Found";
}
}4. Writing the Scrapped Record to Output
The ScrapTask creates new instances of UrlRecord per URL and puts them in a BlockingQueue. A new thread keeps watching this queue and drains all the records from the queue, every 30 seconds. Then the report writer thread keeps appending the new records in the output excel file.
Writing the records, periodically, helps in case of failures and keeps the JVM memory free.
public class WebScrappingApp {
public static void main(String[] args) throws Exception {
...
File outFile = new File("C:\\temp\\webscrapping-output-"+ random.nextLong() +".xlsx");
Map<Integer, Object[]> columns = new HashMap<Integer, Object[]>();
columns.put(rowCounter++, new Object[] {"URL", "Title"});
ReportWriter.createReportFile(columns, outFile); //Create report one time
//periodically, append rows to report
ScheduledExecutorService es = Executors.newScheduledThreadPool(1);
es.scheduleAtFixedRate(runAppendRecords(outFile), 30000, 30000, TimeUnit.MILLISECONDS);
...
}
private static Runnable runAppendRecords(File file) {
return new Runnable() {
@Override
public void run() {
if(processedRecords.size() > 0) {
List<UrlRecord> recordsToWrite = new ArrayList<>();
processedRecords.drainTo(recordsToWrite);
Map<Integer, Object[]> data = new HashMap<>();
for(UrlRecord entity : recordsToWrite) {
data.put(rowCounter++, new Object[] {entity.getVisitedUrl(), entity.getTitle()});
}
System.out.println("###########Writing "+data.size()+" records to excel file############################");
try {
ReportWriter.appendRows(data, file);
} catch (IOException e) {
e.printStackTrace();
} catch (InvalidFormatException e) {
e.printStackTrace();
}
} else {
System.out.println("===========Nothing to write. Waiting.============================");
}
}
};
}
}
public class ReportWriter {
public static void createReportFile(Map<Integer, Object[]> columns, File file){
XSSFWorkbook workbook = new XSSFWorkbook();
XSSFSheet sheet = workbook.createSheet("URL Titles");
Set<Integer> keyset = columns.keySet();
int rownum = 0;
for (Integer key : keyset)
{
Row row = sheet.createRow(rownum++);
Object [] objArr = columns.get(key);
int cellnum = 0;
for (Object obj : objArr)
{
Cell cell = row.createCell(cellnum++);
if(obj instanceof String)
cell.setCellValue((String)obj);
else if(obj instanceof Integer)
cell.setCellValue((Integer)obj);
}
}
try
{
//Write the workbook in file system
FileOutputStream out = new FileOutputStream(file);
workbook.write(out);
out.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
public static void appendRows(Map<Integer, Object[]> data, File file) throws IOException, InvalidFormatException {
XSSFWorkbook workbook = new XSSFWorkbook(new FileInputStream(file));
Sheet sheet = workbook.getSheetAt(0);
int rownum = sheet.getLastRowNum() + 1;
Set<Integer> keyset = data.keySet();
for (Integer key : keyset)
{
Row row = sheet.createRow(rownum++);
Object [] objArr = data.get(key);
int cellnum = 0;
for (Object obj : objArr)
{
Cell cell = row.createCell(cellnum++);
if(obj instanceof String)
cell.setCellValue((String)obj);
else if(obj instanceof Integer)
cell.setCellValue((Integer)obj);
}
}
try
{
FileOutputStream out = new FileOutputStream(file);
workbook.write(out);
out.close();
}
catch (Exception e)
{
e.printStackTrace();
}
}
}5. Demo
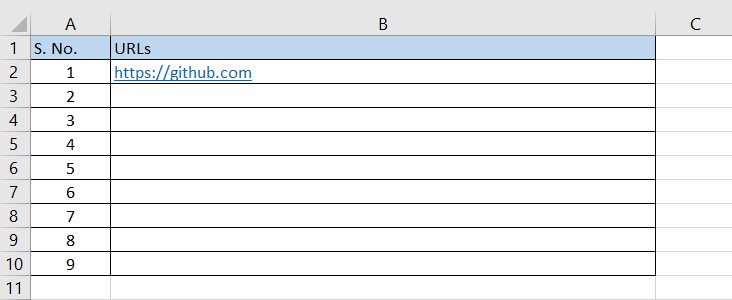
For the demo, create an input excel file in the temp directory as follows.
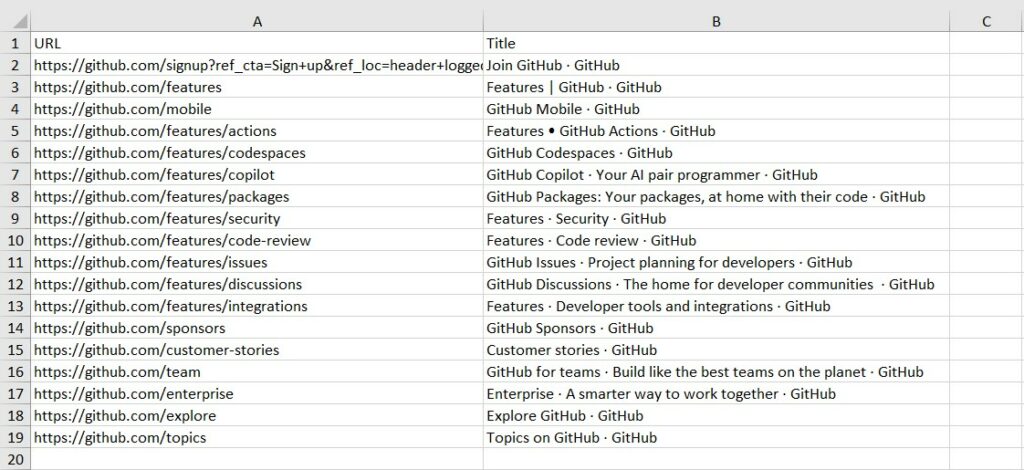
Now run the application and watch out for a generated report in the temp folder.
6. Conclusion
In this Java tutorial, we learned to create a web scrapper. We learned to build various components needed to build a working web scrapper, though it is far from perfect. You can use this case as a starting point and customize it to suit your needs.
Happy Learning !!