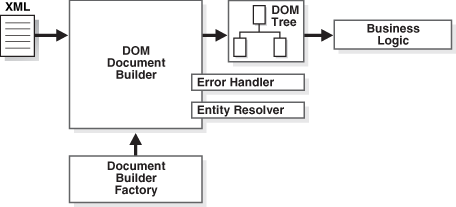
In this Java xml parser tutorial, learn to read XML using DOM parser. DOM parser is intended for working with XML as an object graph (a tree-like structure) in memory – the so-called “Document Object Model (DOM)“.
At first, the parser traverses the input XML file and creates DOM objects corresponding to the nodes in the XML file. These DOM objects are linked together in a tree-like structure. Once the parser is done with the parsing process, we get this tree-like DOM object structure back from it. Now we can traverse the DOM structure back and forth as we want – to get/update/delete data from it.
The other possible ways to read an XML file are using the SAX parser and StAX parser as well.
1. Setup
For demo purposes, we will be parsing the below XML file in all code examples.
<employees>
<employee id="111">
<firstName>Lokesh</firstName>
<lastName>Gupta</lastName>
<location>India</location>
</employee>
<employee id="222">
<firstName>Alex</firstName>
<lastName>Gussin</lastName>
<location>Russia</location>
</employee>
<employee id="333">
<firstName>David</firstName>
<lastName>Feezor</lastName>
<location>USA</location>
</employee>
</employees>2. DOM Parser API
Let’s note down some broad steps to create and use a DOM parser to parse an XML file in java.
1.1. Import dom Parser Packages
We will need to import dom parser packages first in our application.
import org.w3c.dom.*;
import javax.xml.parsers.*;
import java.io.*;1.2. Create DocumentBuilder
The next step is to create the DocumentBuilder object.
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();1.3. Create Document object from XML file
Read the XML file to Document object.
Document document = builder.parse(new File( file ));1.4. Validate Document Structure
XML validation is optional but good to have it before starting parsing.
Schema schema = null;
try {
String language = XMLConstants.W3C_XML_SCHEMA_NS_URI;
SchemaFactory factory = SchemaFactory.newInstance(language);
schema = factory.newSchema(new File(name));
} catch (Exception e) {
e.printStackStrace();
}
Validator validator = schema.newValidator();
validator.validate(new DOMSource(document));1.5. Extract the Root Element
We can get the root element from the XML document using the below code.
Element root = document.getDocumentElement();1.6. Examine Attributes
We can examine the XML element attributes using the below methods.
element.getAttribute("attributeName") ; //returns specific attribute
element.getAttributes(); //returns a Map (table) of names/values1.7. Examine Child-Elements
Child elements for a specified Node can be inquired about in the below manner.
node.getElementsByTagName("subElementName"); //returns a list of sub-elements of specified name
node.getChildNodes(); //returns a list of all child nodes2. Read XML File with DOM parser
In the below example code, we are assuming that the user is already aware of the structure of employees.xml file (its nodes and attributes). So example directly starts fetching information and starts printing it in the console. In a real-life application, we will use this information for some real purpose rather than just printing it on the console and leaving.
public static Document readXMLDocumentFromFile(String fileNameWithPath) throws Exception {
//Get Document Builder
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
//Build Document
Document document = builder.parse(new File(fileNameWithPath));
//Normalize the XML Structure; It's just too important !!
document.getDocumentElement().normalize();
return document;
}Now we can use this method to parse the XML file and verify the content.
public static void main(String[] args) throws Exception {
Document document = readXMLDocumentFromFile("c:/temp/employees.xml");
//Verify XML Content
//Here comes the root node
Element root = document.getDocumentElement();
System.out.println(root.getNodeName());
//Get all employees
NodeList nList = document.getElementsByTagName("employee");
System.out.println("============================");
for (int temp = 0; temp < nList.getLength(); temp++) {
Node node = nList.item(temp);
if (node.getNodeType() == Node.ELEMENT_NODE) {
//Print each employee's detail
Element eElement = (Element) node;
System.out.println("\nEmployee id : " + eElement.getAttribute("id"));
System.out.println("First Name : " + eElement.getElementsByTagName("firstName").item(0).getTextContent());
System.out.println("Last Name : " + eElement.getElementsByTagName("lastName").item(0).getTextContent());
System.out.println("Location : " + eElement.getElementsByTagName("location").item(0).getTextContent());
}
}
}Program Output:
employees
============================
Employee id : 111
First Name : Lokesh
Last Name : Gupta
Location : India
Employee id : 222
First Name : Alex
Last Name : Gussin
Location : Russia
Employee id : 333
First Name : David
Last Name : Feezor
Location : USA3. Read XML into POJO
Another real-life application’s requirement might be populating the DTO objects with information fetched in the above example code. I wrote a simple program to help us understand how it can be done easily.
Let’s say we have to populate Employee objects which are defined as below.
public class Employee {
private Integer id;
private String firstName;
private String lastName;
private String location;
//Setters, Getters and toString()
}Now, look at the example code to populate the Employee objects list. It is just as simple as inserting a few lines in between the code, and then copying the values in DTOs instead of the console.
public static List<Employee> parseXmlToPOJO(String fileName) throws Exception {
List<Employee> employees = new ArrayList<Employee>();
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File(fileName));
document.getDocumentElement().normalize();
NodeList nList = document.getElementsByTagName("employee");
for (int temp = 0; temp < nList.getLength(); temp++) {
Node node = nList.item(temp);
if (node.getNodeType() == Node.ELEMENT_NODE) {
Element eElement = (Element) node;
Employee employee = new Employee();
employee.setId(Integer.parseInt(eElement.getAttribute("id")));
employee.setFirstName(eElement.getElementsByTagName("firstName").item(0).getTextContent());
employee.setLastName(eElement.getElementsByTagName("lastName").item(0).getTextContent());
employee.setLocation(eElement.getElementsByTagName("location").item(0).getTextContent());
//Add Employee to list
employees.add(employee);
}
}
return employees;
}4. Parse “unknown” XML using NamedNodeMap
The previous example shows how we can iterate over an XML document parsed with known or little know structure to you, while you are writing the code. In some cases, we may have to write the code in such a way that even if there are some differences in the assumed XML structure while coding, the program must work without failure.
Here we are iterating over all elements present in the XML document tree. we can add our knowledge and modify the code such that as soon as we get the required information while traversing the tree, we just use it.
private static void visitChildNodes(NodeList nList) {
for (int temp = 0; temp < nList.getLength(); temp++) {
Node node = nList.item(temp);
if (node.getNodeType() == Node.ELEMENT_NODE) {
System.out.println("Node Name = " + node.getNodeName() + "; Value = " + node.getTextContent());
//Check all attributes
if (node.hasAttributes()) {
// get attributes names and values
NamedNodeMap nodeMap = node.getAttributes();
for (int i = 0; i < nodeMap.getLength(); i++) {
Node tempNode = nodeMap.item(i);
System.out.println("Attr name : " + tempNode.getNodeName() + "; Value = " + tempNode.getNodeValue());
}
if (node.hasChildNodes()) {
//We got more children; Let's visit them as well
visitChildNodes(node.getChildNodes());
}
}
}
}
}Program Output.
employees
============================
Node Name = employee; Value =
Lokesh
Gupta
India
Attr name : id; Value = 111
Node Name = firstName; Value = Lokesh
Node Name = lastName; Value = Gupta
Node Name = location; Value = India
Node Name = employee; Value =
Alex
Gussin
Russia
Attr name : id; Value = 222
Node Name = firstName; Value = Alex
Node Name = lastName; Value = Gussin
Node Name = location; Value = Russia
Node Name = employee; Value =
David
Feezor
USA
Attr name : id; Value = 333
Node Name = firstName; Value = David
Node Name = lastName; Value = Feezor
Node Name = location; Value = USAThat’s all for this good-to-know concept around Java XML DOM Parser. Drop me a comment if something is not clear OR needs more explanation.
Happy Learning !!
I have a task to transform xml and xsl file to html. The problem is, the xml and xsl files are uploaded through file upload so i dont have the file object. I have xml and xsl code file contents.
Please help me as to how to transform the contents only.
it will read white spaces also
Hi
I tried to run your code,
while executing and examining node.hasChildNode() always return true and getChildNode().getLength() always return integer values even if there are no child node present.
for ex . Node Lastname in your xml doesnt contain any child node but hasChildNode returns true for the same, it should return false in order for me to do some coding for my project need.
im using the sample xml used here.
Thanks,
Rohini Rangaswany
My requirement is the Write a new corn job to export all users in an XML format. Use the
DOM java class to export to xml. This job should run at 5 pm IST in Hybris
I want to parse html file.
Tried by
but getting error.
It needs xml file only.
How I can parse html file?
hi,
i dont know how i get data if the XML is little more complex and every employee look like that:
David
Feezor
USA
NY
NY
how can i get to the data in city ?
thanks!
I have a XML file. I want to get a XML from the same XML as a subset. How to do it in java please give an code example.
Its urgent please provide your input.
Lots of thanks.
Unmarshal the XML into java objects, and then marshal desired java object into XML.
Hi Lokesh,
I need to transform XHTML span tags with certain style to another (similar) XML structure.
For example, this element should be converted:
This simple example, I could implement by renaming nodes and attributes.
But there are style attributes that I can’t match. In this case I need to ignore/remove the element node but keep its content:
Eg. I can’t map span element when their style attribute is “text-decoration: underline;” :
The element “span style=”text-decoration: underline” should be ignored/removed but the content (child nodes) should remain (text and span elements that can be mapped).
Do you know how this could be implemented? I appreciate any help.
So the expected result should be:
Thanks Benjamin!
I am stuck up with this!!! I want to fetch the value of ns1:uri based on the choices for SMS, MMS…
true
tel:+46123456758
E164
mmsChannel
MMS
00
true
tel:+46123456758
E164
SMS Dummy
SMS
00
true
tel:+464611223344
E164
faxChannel
FAX
true
tel:+46123456758
E164
CCS MWI
MWI
Could you please help me with some sort of hint to read this value. TIA
Please wrap the XML inside [xml] … [/xml].
Hi Lokesh,
If there is one more tag named department inside , then how can we do it in unknown xml structure. to get bith employee as well as department details
what if the nodes have furthur node like
<launch> <announced>23 march 2011</announced> <status>available</status> </launch>now when i give launch in getElementByTagName then it prints the data as 23 march 2011available without any space among them … how to put the space between these node’s contents…
Following is the code used and below element contents are changed which is not desired by replacing the escape character,
Below is the code used,
Document xmlDocument = DocumentBuilderFactory.newInstance()
.newDocumentBuilder().parse(SourceXMLFile);
XPath xPath = XPathFactory.newInstance().newXPath();
XPathExpression exprPre = xPath
.compile(“/SPIRITConfiguration/@Version”);
NodeList list = (NodeList) exprPre.evaluate(xmlDocument,
XPathConstants.NODESET);
for (int i = 0; i < list.getLength(); i++) {
list.item(i).setTextContent(ModelVersion.getValue());
}
// write the content back into new renamed xml file
TransformerFactory transformerFactory = TransformerFactory
.newInstance();
Transformer transformer = transformerFactory.newTransformer();
DOMSource source = new DOMSource(xmlDocument);
StreamResult result = new StreamResult(new File(DestxmlFile));
transformer.transform(source, result);
Kindly help me on this. Thank you in advance.
Hello Sir,
I got a requirement that I have to map my xml to java object without parsing it, but the problem is like that in xml tag names would be same, for example,
Sharique
24
India</name
and class would be like this
public class Employee{
private String empName;
private int age;
private String country;
//getters and setters
}
Please help
You forgot to put your code in [xml] … [/xml] tags.
I don’t know why xml tags are not appearing though I’m providind it in comments
You are not using [xml] your XML here [/xml] tags. Anyway, send me your problem in howtodoinjava@gmail.com. I will reply later in evening.
Hi Lokesh,
I’m struggling with a problem like I have xml which have repeated child node with same name so when I’m trying to fetch all child node values DOM parser returns only first child value.My xml looks like …
Lokesh
Gupta
India
A
B
C
P
K
S
How can I parse it using dom parser to get all repeated values?Please respond.
Please XML java java sourcecodes inside [java] … [/java] OR [xml] … [/xml] tags.
Thanks for the tutorial, it really helped me, but i was wondering…Is there a way to “format” the output?
I mean, you get the info like this :
Node Name = employee; Value =
Lokesh
Gupta
India
Attr name : id; Value = 111
Node Name = firstName; Value = Lokesh
Node Name = lastName; Value = Gupta
Node Name = location; Value = India
But is there a way to just print :
Name : Lokesh
Last Name : Gupta
Location : India
###########
// And so on for every other Employee
Thank you!
I seriously doubt that there is any API support. Reason is simple that you are expected to store the values in some java objects and not directly print them anywhere.
Here after populating the java objects, you can override toString() method to print the content the way you like.
thnx sir
Thanks Lokesh. It cleared my doubt.
what is difference between xml parsing and JAXB. I think both serve the same purpose.
In broader sense, yes, they are somehow same. But if you look closely, they are different things. Parsers are used to generate/populate java objects or simply analyzing the XML data. Java POJOs object’s are optional here.
In JAXB, java POJOs are mandatory. JAXB acts as a bridge between XML and java POJOs. What’s parsers do is just a small portion of JAXB. JAXB is much more than that.