The reactive-stack web framework, Spring WebFlux, has been added to Spring 5. It is fully non-blocking, supports reactive streams back pressure, and runs on such servers as Netty, Undertow, and Servlet 3.1+ containers. In this spring webflux tutorial, we will learn the basic concepts behind reactive programming, webflux APIs and a fully functional hello world example.
1. Reactive Programming
Reactive programming is a programming paradigm that promotes an asynchronous, non-blocking, event-driven approach to data processing. Reactive programming involves modeling data and events as observable data streams and implementing data processing routines to react to the changes in those streams.
Before digging deeper into the reactive world, let us understand the difference between blocking and non-blocking request processing.
1.1. Blocking vs Non-blocking (Async) Request Processing
Blocking Request Processing
In traditional MVC applications, a new servlet thread is created (or obtained from the thread pool) when a request comes to the server. It delegates the request to worker threads for I/O operations such as database access etc. During the time worker threads are busy, the servlet thread (request thread) remains in waiting status, and thus it is blocked. It is also called synchronous request processing.
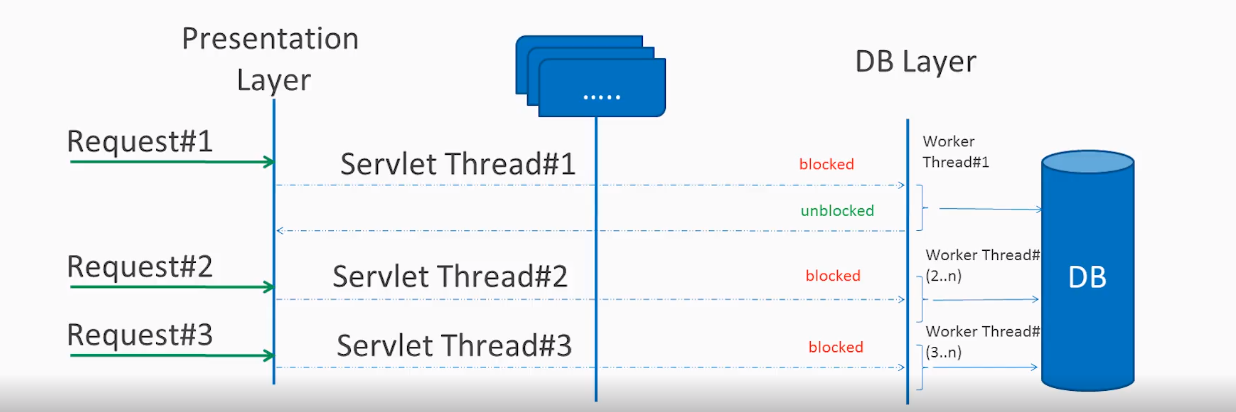
As a server can have some finite number of request threads, it limits the server’s capability to process that number of requests at maximum server load. It may hamper the performance and limit the full utilization of server capability.
Non-blocking Request Processing
In non-blocking or asynchronous request processing, no thread is in waiting state. There is generally only one request thread receiving the request.
All incoming requests come with an event handler and callback information. Request thread delegates the incoming requests to a thread pool (generally a small number of threads) which delegates the request to its handler function and immediately starts processing other incoming requests from the request thread.
When the handler function is complete, one thread from the pool collects the response and passes it to the call back function.
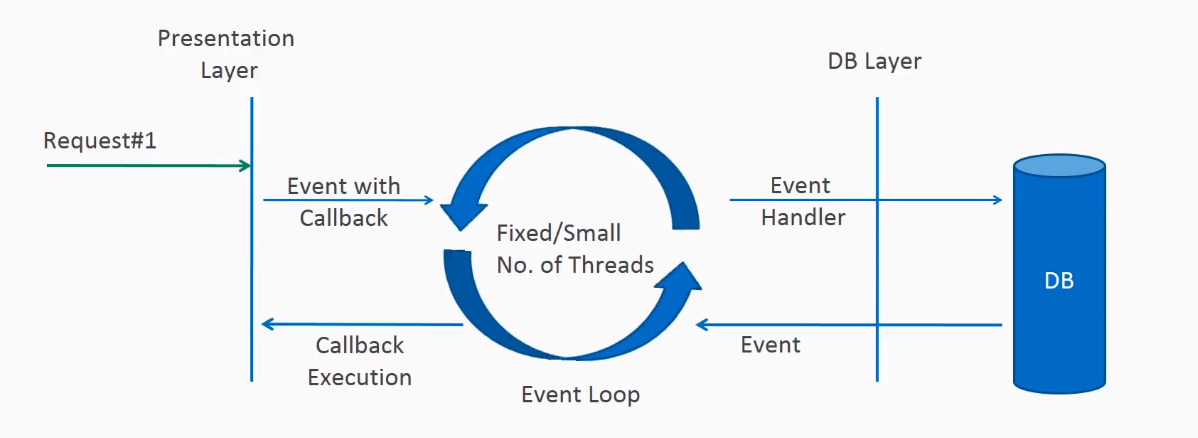
Non-blocking nature of threads helps in scaling the performance of the application. A small number of threads means less memory utilization and less context switching.
1.2. What is Reactive Programming?
The term, “reactive,” refers to programming models that are built around reacting to changes. It is built around the publisher-subscriber pattern (observer pattern). In the reactive style of programming, we make a request for resources and start performing other things. When the data is available, we get the notification along with data in the callback function. The callback function handles the response as per application/user needs.
One important thing to remember is back pressure. In non-blocking code, back-pressure controls the rate of events so that a fast producer does not overwhelm its destination.
Reactive web programming is well-suited for applications that involve streaming data and real-time interactions. By using non-blocking and event-driven mechanisms, we can design excellent solutions for these applications.
However, reactive programming can also benefit traditional CRUD applications, it is worth mentioning that while reactive APIs offload tasks to non-blocking threads, they also require proper thread management. Incorrect handling of threads or blocking operations within a reactive context can lead to thread contention and performance issues.
Also, reactive programming adds more unnecessary complexity without substantial gains in low concurrent traditional applications. For such applications, a traditional synchronous approach may be more straightforward and suitable.
If you are developing the next Facebook or Twitter with lots of data, real-time analytics applications, chat applications, or live update websites, a reactive API might be just what you are looking for.
2. Reactive Streams API
The new Reactive Streams API was created by engineers from Netflix, Pivotal, Lightbend, RedHat, Twitter, and Oracle, among others and is now part of Java 9. It defines four interfaces:
Publisher
The publisher emits a sequence of events to subscribers according to the demand received from its subscribers. A publisher can serve multiple subscribers.
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}Subscriber
Receives and processes events emitted by a Publisher. Please note that no notifications will be received until Subscription#request(long) is called to signal the demand. It has four methods to handle various kinds of responses received.
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}Subscription
Defines a one-to-one relationship between a Publisher and a Subscriber. It can only be used once by a single Subscriber. It is used to both signal desire for data and cancels demand (and allow resource cleanup).
public interface Subscription<T> {
public void request(long n);
public void cancel();
}Processor
Represents a processing stage consisting of both a Subscriber and a Publisher and obeys both contracts.
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> {
}Two popular implementations of reactive streams are RxJava (https://github.com/ReactiveX/RxJava) and Project Reactor (https://projectreactor.io/).
3. What is Spring WebFlux?
Spring WebFlux is a parallel version of Spring MVC and supports fully non-blocking reactive streams. It supports the back pressure concept and uses Netty as the inbuilt server to run reactive applications. If you are familiar with the Spring MVC programming style, you can easily work on webflux also.
Spring webflux uses project reactor as the reactive library. Reactor is a Reactive Streams library; therefore, all of its operators support non-blocking back pressure. It is developed in close collaboration with Spring.
Spring WebFlux heavily uses two publishers :
- Mono: Returns 0 or 1 element.
Mono<String> mono = Mono.just("Alex");
Mono<String> mono = Mono.empty();- Flux: Returns 0…N elements. A Flux can be endless, meaning that it can keep emitting elements forever. Also it can return a sequence of elements and then send a completion notification when it has returned all of its elements.
Flux<String> flux = Flux.just("A", "B", "C");
Flux<String> flux = Flux.fromArray(new String[]{"A", "B", "C"});
Flux<String> flux = Flux.fromIterable(Arrays.asList("A", "B", "C"));
//To subscribe call method
flux.subscribe();In Spring WebFlux, we call reactive APIs/functions that return Monos and Fluxes, and your controllers will return monos and fluxes. When you invoke an API that returns a mono or a flux, it will return immediately. The function call results will be delivered to you through the mono or flux when they become available.
To build a truly non-blocking application, we must aim to create/use all of its components as non-blocking i.e. client, controller, middle services and even the database. If one of them is blocking the requests, our aim will be defeated.
4. Spring Boot WebFlux Example
In this Spring Boot application, I am creating an employee management system. I chose it because, while learning, you can compare it with a traditional MVC-style application. To make it fully non-blocking, I am using MongoDB as the backend database.
4.1. Maven
Include spring-boot-starter-webflux, spring-boot-starter-data-mongodb-reactive, spring-boot-starter-test and reactor-test dependencies.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb-reactive</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>4.2. Configurations
Webflux Configuration
The @EnableWebFlux imports the Spring WebFlux configuration from WebFluxConfigurationSupport that enables the use of annotated controllers and functional endpoints. It is similar to @EnableWebMvc annotation for Spring MVC applications.
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableWebFlux
public class WebFluxConfig implements WebFluxConfigurer {
}MongoDB Configuration
We are using MongoDB ad backend database so let’s configure the persistence layer.
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.mongodb.config.AbstractReactiveMongoConfiguration;
import org.springframework.data.mongodb.core.ReactiveMongoTemplate;
import org.springframework.data.mongodb.repository.config.EnableReactiveMongoRepositories;
import com.mongodb.reactivestreams.client.MongoClient;
import com.mongodb.reactivestreams.client.MongoClients;
@Configuration
@EnableReactiveMongoRepositories(basePackages = "com.howtodoinjava.demo.dao")
public class MongoConfig extends AbstractReactiveMongoConfiguration {
@Value("${port}")
private String port;
@Value("${dbname}")
private String dbName;
@Override
public MongoClient reactiveMongoClient() {
return MongoClients.create();
}
@Override
protected String getDatabaseName() {
return dbName;
}
@Bean
public ReactiveMongoTemplate reactiveMongoTemplate() {
return new ReactiveMongoTemplate(reactiveMongoClient(), getDatabaseName());
}
}Properties file
The properties used in the Mongo config can be defined in application.properties file.
port=27017
dbname=testdb4.3. REST Controller with CRUD APIs
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseStatus;
import org.springframework.web.bind.annotation.RestController;
import com.howtodoinjava.demo.model.Employee;
import com.howtodoinjava.demo.service.EmployeeService;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@RestController
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
@RequestMapping(value = { "/create", "/" }, method = RequestMethod.POST)
@ResponseStatus(HttpStatus.CREATED)
public void create(@RequestBody Employee e) {
employeeService.create(e);
}
@RequestMapping(value = “/{id}”, method = RequestMethod.GET)
public Mono<ResponseEntity<Employee>> findById(@PathVariable(“id”) Integer id) {
return employeeService.findById(id)
.map(employee -> ResponseEntity.ok(employee))
.defaultIfEmpty(ResponseEntity.notFound().build());
}
@RequestMapping(value = "/name/{name}", method = RequestMethod.GET)
public Flux<Employee> findByName(@PathVariable("name") String name) {
return employeeService.findByName(name);
}
@RequestMapping(method = RequestMethod.GET, produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<Employee> findAll() {
Flux<Employee> emps = employeeService.findAll();
return emps;
}
@RequestMapping(value = "/update", method = RequestMethod.PUT)
@ResponseStatus(HttpStatus.OK)
public Mono<Employee> update(@RequestBody Employee e) {
return employeeService.update(e);
}
@RequestMapping(value = "/delete/{id}", method = RequestMethod.DELETE)
@ResponseStatus(HttpStatus.OK)
public void delete(@PathVariable("id") Integer id) {
employeeService.delete(id).subscribe();
}
}4.4. Service
import com.howtodoinjava.demo.model.Employee;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
public interface IEmployeeService
{
void create(Employee e);
Mono<Employee> findById(Integer id);
Flux<Employee> findByName(String name);
Flux<Employee> findAll();
Mono<Employee> update(Employee e);
Mono<Void> delete(Integer id);
}import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.howtodoinjava.demo.dao.EmployeeRepository;
import com.howtodoinjava.demo.model.Employee;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@Service
public class EmployeeService implements IEmployeeService {
@Autowired
EmployeeRepository employeeRepo;
public void create(Employee e) {
employeeRepo.save(e).subscribe();
}
public Mono<Employee> findById(Integer id) {
return employeeRepo.findById(id);
}
public Flux<Employee> findByName(String name) {
return employeeRepo.findByName(name);
}
public Flux<Employee> findAll() {
return employeeRepo.findAll();
}
public Mono<Employee> update(Employee e) {
return employeeRepo.save(e);
}
public Mono<Void> delete(Integer id) {
return employeeRepo.deleteById(id);
}
}4.5. DAO
import org.springframework.data.mongodb.repository.Query;
import org.springframework.data.mongodb.repository.ReactiveMongoRepository;
import com.howtodoinjava.demo.model.Employee;
import reactor.core.publisher.Flux;
public interface EmployeeRepository extends ReactiveMongoRepository<Employee, Integer> {
@Query("{ 'name': ?0 }")
Flux<Employee> findByName(final String name);
}4.6. Model
The model is a Mongo Document.
import org.springframework.context.annotation.Scope;
import org.springframework.context.annotation.ScopedProxyMode;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
@Scope(scopeName = "request", proxyMode = ScopedProxyMode.TARGET_CLASS)
@Document
public class Employee {
@Id
int id;
String name;
long salary;
//Getters and setters
@Override
public String toString() {
return "Employee [id=" + id + ", name=" + name + ", salary=" + salary + "]";
}
}5. Demo
Start the application, perform CRUD operations and check requests and responses.
- HTTP POST http://localhost:8080/create
{
"id":1,
"name":"user_1",
"salary":101
}{
"id":2,
"name":"user_2",
"salary":102
}- HTTP PUT http://localhost:8080/update
{
"id":2,
"name":"user_2",
"salary":103
}- HTTP GET http://localhost:8080/
data:{"id":1,"name":"user_1","salary":101}
data:{"id":2,"name":"user_2","salary":102}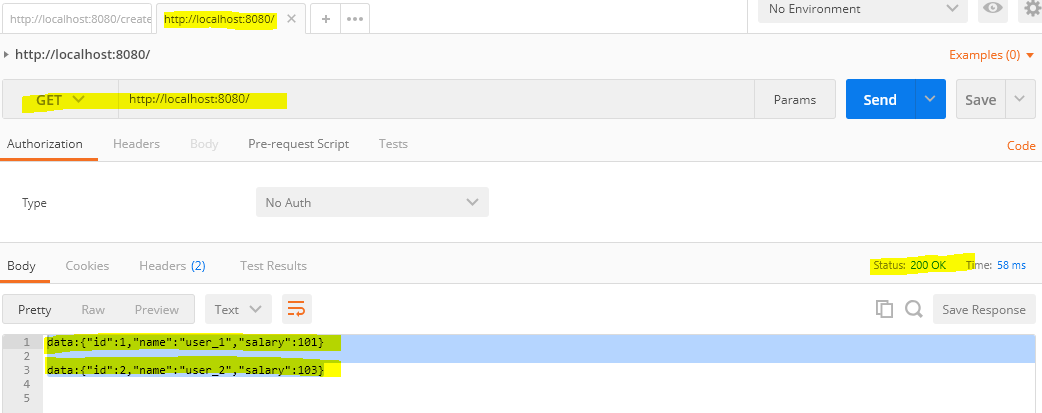
Notice that I am testing the API with Postman chrome browser extension which is a blocking client. It will display the result only when It has collected both employees’ responses.
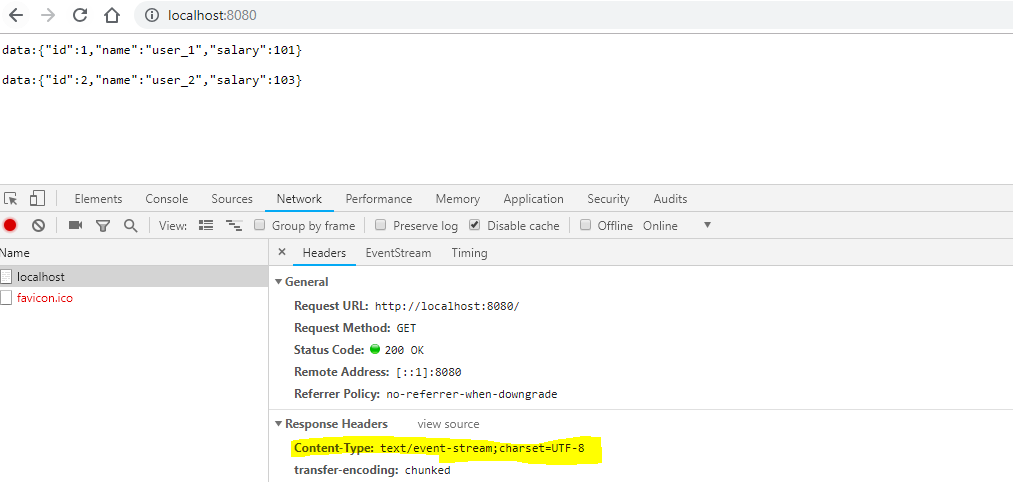
To verify the non-blocking response feature, hit the URL in the chrome browser directly. The results will appear one by one, as and when they are available in form of events (text/event-stream). To better view the result, consider adding a delay to the controller API.
6. Conclusion
Both Spring MVC and Spring WebFlux support client-server architecture but there is a key difference in the concurrency model and the default behavior for blocking nature and threads. In Spring MVC, it is assumed that applications can block the current thread while in webflux, threads are non-blocking by default. It is the main difference between spring webflux vs mvc.
Reactive and non-blocking generally do not make applications run faster. The expected benefit of reactive and non-blocking is the ability to scale the application with a small, fixed number of threads and lesser memory requirements. It makes applications more resilient under load because they scale in a more predictable manner.
Drop me your questions related to this spring boot webflux tutorial.
Happy Learning !!
I am getting a MongoDB an exception while connecting to MongoDB. is a separate installation of MongoDB required for this example or does it work like a in memory database by SpringBoot?
Please refer to this.
I don’t get the part where you said: Reactive web programming is great for applications that have streaming data, and not great for traditional CRUD applications, why is that?
CRUD applications also have IO operations (besides CPU-intensive operations), and according to the definition: In the reactive style of programming, we make a request for resources and start performing other things; so if we let the IO operation run async and continue to serve other requests, it’s still a big benefit
Hi, Thanks for the comment. Perhaps, the words I chose are confusing. I will fix the article. I meant to say that, generally, there is very little benefit of using reactive programming in traditional CRUD applications where the backend database is transactional, and client must wait to get the response before triggering another request.
I agree that, even though benefits are less in comparison to reactive/streaming applications, still there is a lot to offer in traditional CRUD application if they are designed carefully.
The examples contain a major flaw in findById. The repo always returns a mono, as the retrieval is async. So you do not know immediately if you need to return a 404. Instead, you should use to mono to determine the response code.
Thanks for the feedback. Yes, it makes sense to return the Mono and let the client decide what to do if the content is not available.
Or await the mono, and return a Mono<ServerResponse<T>>. If the mono resolves you can set the proper return code and body.
In async communication, I will prefer not to return 404. Anyways, thanks for sharing your ideas.
The current findById method always returns HttpStatus.OK even if the employee is not found, because Mono<Employee> is never null.
A better approach is to use Mono.flatMap and Mono.defaultIfEmpty to return 404 NOT_FOUND if the employee does not exist.
@RequestMapping(value = “/{id}”, method = RequestMethod.GET)
@ResponseBody
public Mono<ResponseEntity<Employee>> findById(@PathVariable(“id”) Integer id) {
return employeeService.findById(id)
.map(employee -> ResponseEntity.ok(employee))
.defaultIfEmpty(ResponseEntity.notFound().build());
}
Nice Article.
If you want to see visually how FLUX works – then add this method & create bulk of records first, by calling the endpoint
http://localhost:8080/callme@RequestMapping(value = { "/callme" }, method = RequestMethod.GET) @ResponseStatus(HttpStatus.CREATED) @ResponseBody public void callMe() { for (int i=1;i<1000000; i++) { Employee emp = new Employee(); emp.setId(i); emp.setName("user_" + i); emp.setSalary(100 + 1); employeeService.create(emp); } }Post successful execution of above endpoint, call http://localhost:8080 and see how information renders on browser.
Also, the processing stops the moment you close the browser window or click 'X' (i.e. stop loading) on browser address bar. You will see below message on server console –
19:27:13.464 [reactor-http-nio-3] DEBUG o.s.w.s.DisconnectedClient – [4003e220] Client went away: java.io.IOException: Broken pipe (stacktrace at TRACE level for 'org.springframework.web.server.DisconnectedClient')