Java HashMap is a member of the Collections framework and stores key-value pairs. Each key is mapped to a single value, and duplicate keys are not allowed. In this tutorial, we will learn how HashMap internally stores the key-value pairs and how it prevents duplicate keys.
1. A Quick Recap of HashMap
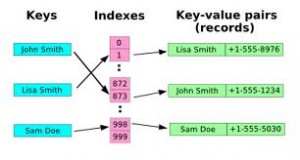
The HashMap stores the key-value pairs. It associates the supplied key with the value, so later we can retrieve the value using the key.
HashMap<String, String> map = new HashMap<>();
map.put("key", "value"); //Storage
map.get("key"); // returns "value"Internally, the key-value pairs are stored as an instance of Map.entry instances represented by Node. Each instance of Node class contains the supplied, key, value, the hash of the key object, and a reference to the next Node, if any, as in the LinkedList.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//...
}The generated hash of the Key object is also stored to avoid calculating hash every time during comparisons, to improve the overall performance.
2. Internal Implementation of HashMap
The HashMap is a HashTable based implementation of the Map interface. It internally maintains an array, also called a “bucket array”. The size of the bucket array is determined by the initial capacity of the HashMap, the default is 16.
transient Node<K,V>[] table;Each index position in the array is a bucket that can hold multiple Node objects using a LinkedList.

As shown above, it is possible that multiple keys may produce the hash that maps them into a single bucket. This is why, the Map entries are stored as LinkedList.
But when entries in a single bucket reach a threshold (TREEIFY_THRESHOLD, default value 8) then Map converts the bucket’s internal structure from the linked list to a RedBlackTree (JEP 180). All Entry instances are converted to TreeNode instances.
Basically, when a bucket becomes too big, HashMap dynamically replaces it with an ad-hoc implementation of TreeMap. This way, rather than having a pessimistic O(n) performance, we get a much better O(log n).
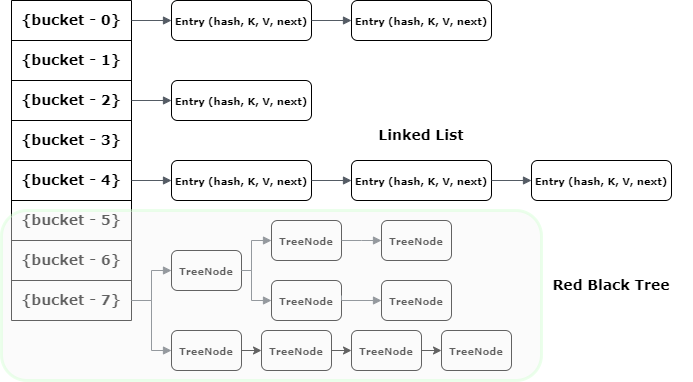
Note that when nodes in a bucket reduce less than UNTREEIFY_THRESHOLD the Tree again converts to LinkedList. This helps balance performance with memory usage because TreeNodes takes more memory than Map.Entry instances. So Map uses Tree only when there is a considerable performance gain in exchange for memory wastage.
3. How Hashing is used to Locate Buckets?
Hashing, in its simplest form, is a way to assign a unique code for any object after applying a formula/algorithm to its properties. A true hash function should return the same hash code every time the function is applied to the same or equal objects. In other words, two equal objects must consistently produce the same hash code.
In Java, all objects inherit a default implementation of hashCode() function defined in Object class. It produces the hash code by typically converting the internal address of the object into an integer, thus producing different hash codes for all different objects.
public class Object {
public native int hashCode();
}Java designers understood that end-user-created objects may not produce evenly distributed hash codes, so Map class internally applies another round of hashing function on the key’s hashcode() to make them reasonably distributed.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}This is the final hash, generated from the initial hash of the Key object, that is the index of the array where Node should be searched.
4. HashMap.put() Operation
So far, we understood that each Java object has a unique hashcode associated with it, and this hashcode is used to decide the bucket location in the HashMap where the key-value pair will be stored.
Before going into put() method’s implementation, it is very important to learn that instances of Node class are stored in an array. Each index location in the array is treated as a bucket:
transient Node<K,V>[] table;To store a key-value pair, we invoke the put() API as follows:
V put(K key, V value);The put() API, internally, first calculates the initial hash using the key.hashcode() method and then calculates the final hash using the hash() method discussed in the previous section.
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}This final hash value is ultimately used to compute an index in the array or bucket location.
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}Once the bucket is located, HashMap stores the Node in it.
5. How are Collisions Resolved in the Same Bucket?
Here comes the main part now, as we know that two unequal objects can have the same hash code value, how two different objects will be stored in the same array location called a bucket.
If you remember, Node class had an attribute "next". This attribute always points to the next object in the chain. So, all the nodes with equal keys are stored in the same array index in the form of a LinkedList.
When an Node object needs to be stored at a particular index, HashMap checks whether there is already a Node present in the array index?? If there is no Node already present, the current Node object is stored in this location. If an object is already sitting on the calculated index, its next attribute is checked. If it is null, and current Node object becomes next node in LinkedList. If next variable is not null, the process is followed until next is evaluated as null.
Note that while iterating over nodes, if the keys of the existing node and new node are equal then the value of the existing node is replaced by the value of the new node.
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
break;
} Note that if the first node in the bucket is of type TreeNode then TreeNode.putTreeVal() is used to insert a new node in the red-black tree.
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); In summary, we can say that:
- If the bucket is empty, the Node is stored directly in the array at the calculated index.
- If the bucket is not empty i.e. a Node exists already, the current Node is traversed in LinkedList style until the
nextnode is empty or the keys match. Once we find the next to be empty, we store the current Node at the last of the LinkedList.
6. HashMap.get() Operation
The Map.get() API takes the key object ar method argument and returns the associated value, if it is found in the Map.
String val = map.get("key");Similar to the put() API, the logic to find the bucket location is similar to the get() API. Once the bucket is located using the final hash value, the first node at the index location is checked.
If the first node is TreeNode type then TreeNode.getTreeNode(hash, key) API is used to search for the equal key object. If such a TreeNode is found, the value is returned.
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);If the first node is not TreeNode then the search happens in the LinkedList fashion and the next attribute is checked in each iteration until the matching key object is found of a Node.
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null); 7. Conclusion
This Java tutorial discussed the internal working of the HashMap class. It discussed how the hash is calculated in two steps, and how the final hash is then used to find the bucket location in an array of Nodes. We also learned how the collisions are resolved in case of duplicate key objects.
Happy Learning !!
I believe you missed one scenario: when putting new entry into Hashmap, then the entry with the same key may already be in. In such case the value gets replaced for given key. So following statement might need be adjusted, since it is not always true:
“If an object is already sitting on the calculated index, its
nextattribute is checked. If it isnull, and current Node object becomes next node in LinkedList. Ifnextvariable is notnull, the process is followed untilnextis evaluated asnull.”Thanks for the feedback. I added the additional information.
The bigger the table (initial capacity HashMap constructor parameter), the lesser will index collision occurs (more collisions equals slower HashMap performance). The default is only 16 and the recommended value is x2 of expected total size (bigger is better). I think for performance, it’s better to set the initial capacity to x4 of expected size and load factor of 0.3. Note rehashing (when current size > initial capacity * load factor) also slows down performance.
“Tree bins (i.e., bins whose elements are all TreeNodes) are ordered primarily by hashCode” … since the elements have collided already, don’t they have the same hashcode?
One more thing is since it relies on the ordering provided by the comparable interface in case of ties, what if the interface was not implemented?
““Tree bins (i.e., bins whose elements are all TreeNodes) are ordered primarily by hashCode” … since the elements have collided already, don’t they have the same hashcode?” Not necessarily. Since the put() function calls another internal hash() function on the hash of the key to ensure the entry falls within the array indices (for keys’ hash values that are too big), you can end up with keys with different hashcodes in the same bucket.
Hope that helps.
Excellent article. I have one question.
HashMap hm = new HashMap();
hm.put(“Suyog”, “yes”);
hm.put(“SUYOG”, “yes1”);
hm.put(“SuyoG”, “ye2”);
System.out.println(hm.size());
The above code will print 3. But if I want to have hashMap size 1 then how can we override the hashCode() and equals() methods. And in which class we should override them.
Looking forward for reply from you.
-Suyog
@Suyog, In order to achieve what you want you should add all String values (“yes”, “yes2″…) under an equal key. In this case you should override the String’s equals/hashCode which is not possible ;) So the second option would be to pack your String keys in something like MyStringKeyWrapper which treats Strings as equal ignoring the case
In that way only the last value would be present in the HashMap (1st would be replaced with the 2nd and the 2nd one with 3rd).
You would have to override String hashcode and equals methods which is not possible since String class is final.
If you want to achieve such behaviour, better solution would be to make String key uppercase or lowercase BEFORE putting into (and before getting from) the map.
hi Lokesh,
really awesome article, I have one doubt. As you said The HashMap is internally based on LinkedList. And the Entry in Entry class is pointing to the link of the next Node or we say Entry. how objects with the same bucket value(index), I understood here that the map will check for the next node and put the new but equal hashcode entry to the next link. so doesn’t it changes the index position? how it is managed.
like if I have a object A with hashcode 50 and B also with hashcode 50 this is how it will be?
[n]–[A]–[B]–[G] or [n]–[A]–[G]
|–[B]– –|
I mean to say does N points to A and B both or just A and A points to B.
Thanks Lokesh for the nice explanation. I have a small query.
I have a class
package com.test.demo; public class Employee { @Override public int hashCode() { return 20; } @Override public boolean equals(Object obj) { return false; } } package com.test.demo; import java.util.HashMap; import java.util.Set; public class HashMapTest { public static void main(String[] args) { Employee employee = new Employee(); Employee employee1 = new Employee(); HashMap<Employee, String> hashMap = new HashMap<Employee, String>(); hashMap.put(employee, "employee1"); hashMap.put(employee1, "employee2"); hashMap.put(employee, "employee3"); System.out.println(hashMap.size() + " size of hashmap"); Set<Employee> keySet = hashMap.keySet(); for (Employee employee2 : keySet) { System.out.println(hashMap.get(employee2)); } } }So, what I am doing is creating a class (Employee) and only implementing the hashCode and equals method. The equals method is returning false, but the hashcode is same.
In another class I create 2 different instances of Employee
and I am inserting the records in hashmap
Ideally what should happen is the size of the hashmap should be 3 as hashcode is same and equals method is returning false. But I see the size as two and the last two entries in hahmap.
Can you please advise
Thanks
Shubh
HashMap uses below condition for presence of existing key:
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))You returning fixed hash so e.hash == hash will be true. Similarily, you are inserting same object as key in first and 3rd statement so e.key==key is also true. It makes whole if statement true, so first entry is replaced with third entry.
Hmm… once encountered similar question at interview.