
1. Introduction
The HashMap, part of the Java Collections framework, is used to store key-value pairs for quick and efficient storage and retrieval operations. In the key-value pair (also referred to as an entry) to be stored in HashMap, the key must be a unique object whereas values can be duplicated.
The keys are used to perform fast lookups. When retrieving a value, we must pass the associated key. If the key is found in the HashMap, it returns the value, else returns null.
HashMap<String, String> map = new HashMap<>();
map.put("+1", "USA");
map.put("+91", "India");
map.get("+1"); // returns "USA"
map.get("+2"); // returns nullNote that HashMap is an unordered collection, and doesn’t guarantee the insertion order of key-value pairs. The internal ordering may change during the resize operation.
Also, HashMap does not provide thread safety, so using it in a concurrent program may result in an inconsistent state of key-value pairs stored in the HashMap.
2. Creating a HashMap
2.1. Using Default Constructor
We can create HashMap using different ways, specific to the requirements. For example, we can create an empty HashMap containing no key-value pairs initially. Later, we can add the key-value pairs in this empty HashMap.
HashMap<String, String> map = new HashMap<>();Additionally, we can specify the initial load capacity and load factor for performance reasons discussed later in this article. Note that the initial capacity must be a power of two, and the load factor should be between 0 and 1.
HashMap<String, String> map = new HashMap<>(64, 0.90f);2.2. Using HashMap.newHashMap()
The newHashMap() is a static method that was introduced in Java 19. It creates a new, empty HashMap suitable for the expected number of mappings.
The returned map uses the default load factor of 0.75. The initial capacity (calculated with calculateHashMapCapacity()) is generally large enough to store the expected number of mappings without resizing the map.
HashMap<String, String> map = HashMap.newHashMap(6);2.3. Using Copy Constructor
Alternatively, we can also initialize a HashMap with an existing Map. In the following code, the entries from the map will be copied into the copiedMap.
HashMap<String, String> copiedMap = new HashMap<>(map);We can modify the entries in a map, without affecting the entries in the other map. Note that after copying the entries, the key and value objects, from both maps, refer to the same objects in the memory. So it is important to understand that making changes to a value object will be reflected in both maps.
HashMap<Integer, Item> map = new HashMap<>();
map.put(1, new Item(1, "Name"));
// New map with copied entries
HashMap<Integer, Item> copiedMap = new HashMap<>(map);
// Changing the value object in one map
copiedMap.get(1).setName("Modified Name");
// Change is visible in both maps
System.out.println(map.get(1)); // Item(id=1, name=Modified Name)
System.out.println(copiedMap.get(1)); // Item(id=1, name=Modified Name)3. Common HashMap Operations
Let us explore the common operations performed on the HashMap entries in any application.
3.1. Adding Key-Value Pairs (put)
The HashMap.put() method stores the specified value and associates it with a specified key. If the map previously contained a mapping for the key, the old value is replaced with the new value.
HashMap<String, String> hashmap = new HashMap<>();
hashmap.put("+1", "USA"); // stores USA and associates with key +1
hashmap.put("+1", "United States"); // Overwrites USA with United States
hashmap.get("+1"); //returns United States3.2. Retrieving Values by Key (get)
The HashMap.get() method returns the value to which the specified key is mapped, or null if the map contains no mapping for the key.
hashmap.put("+1", "USA");
hashmap.get("+1"); // returns USA
hashmap.get("+2"); // returns nullIf the application allows us to put null values in the map, then we may verify if the key is absent or the mapped value is null using the method containsKey().
3.3. Removing Entries by Key (remove)
The HashMap.remove() method removes the key-value pair for the specified key, if present.
hashmap.remove("+1");3.4. Checking for Key/Value Existence (containsKey, containsValue)
The containsKey() method returns true if the hashmap contains a mapping for the specified key. Otherwise, it returns false.
hashmap.put("+1", "USA");
hashmap.containsKey("+1"); //return true
hashmap.containsKey("+2"); //return falseSimilarly, the containsValue() method returns true if the hashmap contains one or more key-value pairs with the specified value. Otherwise, it returns false.
hashmap.put("+1", "USA");
hashmap.containsValue("USA"); //return true
hashmap.containsValue("Canada"); //return false3.5. Iterating through a HashMap
We can iterate over the keys, values or entries of a HashMap using the different collection views returned from the following methods:
keySet()to iterate over keys and access valuesentrySet()to iterate over key-value pairs
for (String key : hashmap.keySet()) {
System.out.println("Key: " + key);
System.out.println("Value: " + hashmap.get(key));
}
for (Map.Entry<String, String> entry : hashmap.entrySet()) {
System.out.println("Key: " + entry.getKey());
System.out.println("Value: " + entry.getValue());
}We can also use the forEach() method to iterate over the entries in a more clear way.
hashmap.forEach((key, value) -> System.out.println(key + ": " + value));3.6. Using Java 8 Streams with HashMap
Java Stream API provides a concise way to process a collection of objects in a fluent manner. We can use the streams with HashMap class, primarily, for collecting an existing stream into HashMap.
To collect Stream elements in the HashMap, we can use the Stream.collect() method along with the Collectors.toMap() collector.
Stream<Item> stream = Stream.of(new Item(1, "Item 1"), new Item(2, "Item 2"));
Map<Long, String> itemMap = stream.collect(
Collectors.toMap(Item::getId, Item::getName, (oldValue, newValue) -> oldValue, HashMap::new)
);
System.out.println(itemMap); // {1=Item 1, 2=Item 2}Just to mention, we can use the Stream APIs for sorting the map entries and store them in another map that maintains the insertion order such as LinkedHashMap.
LinkedHashMap<Long, String> sortedMap = stream.entrySet().stream()
.sorted(Map.Entry.comparingByKey())
.collect(
Collectors.toMap(Map.Entry::getKey,
Map.Entry::getValue,
(oldValue, newValue) -> oldValue,
LinkedHashMap::new)
);4. HashMap Implementation in Java
Although it is not mandatory to know the internals of HashMap class to use it effectively, still understanding “how HashMap works” will expand your knowledge in this topic as well as your overall understanding of Map data structure.
The HashMap internally uses a HashTable to store the entries. A HashTable stores the key-value pairs in an array-based structure, and it uses a hashing function to map keys to specific indices in the array. The array is referred to as a bucket array, too.
Since Java 8, the bucket is implemented as a LinkedList. By using the LinkedList, we can store multiple entries in a single bucket.

To improve the performance, when the number of nodes reaches a threshold (default is 8), the LinkedList is converted to RedBlack Tree.
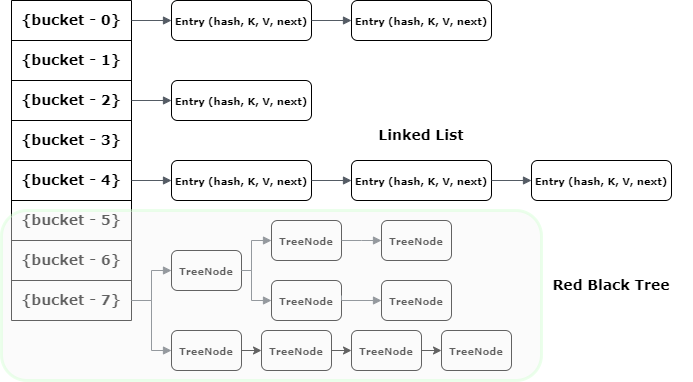
When the number of nodes decreases below a threshold (default 6), the tree is converted back to LinkedList.
You can read this article to understand the internal implementation of HashMap in depth.
5. HashMap Performance and Optimizations
In most real-life applications, we will be storing only a few entries (perhaps less than 100) in the HashMap. In such cases, any performance optimization makes little impact and is often not required.
In other cases, when we want to store hundreds or millions of entries in a HashMap, we should do a review of the following.
5.1. Time Complexity Analysis
During insertion, deletion and retrieval operations, the complexity of operations in the HashMap is generally constant on average (O(1)). Note that the complexity is highly dependent on the well-distributed hash function and an appropriate load factor.
In worst cases, all keys end up in the same bucket due to hash collisions, causing the bucket to form a linked list or a tree, thus leading to linear time complexity (O(n)).
- Average Case: O(1)
- Best Case: O(1)
- Worst Case: O(n)
5.2. Reducing Collisions and Resizing Overhead
As discussed above, it is very important to create a good hashing function that can distribute keys evenly across the available buckets, reducing the likelihood of collisions.
The default hashCode() function in inbuilt Java types (such as String, Integer, Long etc) does an excellent job in most cases. So it is highly advisable to use Java String or wrapper classes as the keys in the HashMap.
Still, if we require to create a custom key class, the following guide will help us in designing a good custom Key for HashMap.
For example, in the following Account class, we have overridden the hashcode and equals method and used only the account number to verify the uniqueness of the Account instance. All other possible attributes of the Account class can be changed on runtime.
public class Account {
private int accountNumber;
private String holderName;
//constructors, setters, getters
//Depends only on account number
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + accountNumber;
return result;
}
//Compare only account numbers
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Account other = (Account) obj;
if (accountNumber != other.accountNumber)
return false;
return true;
}
}You can change the above implementation based on your requirements.
5.3. Memory Efficiency and Garbage Collection
Generally, memory efficiency is a result of setting the appropriate initial capacity and load factor based on the expected number of entries to store. It can help in reducing the number of resizing operations and, thus, minimize temporary memory overhead during put() operations.
Estimating the ideal initial capacity is important because overestimating can lead to wasted memory, and underestimating can lead to increased resize operations.
To further avoid memory issues, we should clean up the entries appropriately when not required anymore. Removing unnecessary entries or clearing the HashMap can help free up memory.
In some cases, objects stored as keys or values may have finalizers. Such objects have a more complex lifecycle and can potentially affect garbage collection efficiency.
6. Common Pitfalls and How to Avoid Them
6.1. ConcurrentModificationException
The ConcurrentModificationException occurs when a collection is modified concurrently while it is being iterated. In case of HashMap, if we are iterating using its collection views (keySet, valueSet, entrySet) and modify the HashMap during iteration, we will get the ConcurrentModificationException.
for (Map.Entry<String, Integer> entry : nameMap.entrySet()) {
if (entry.getKey().startsWith("Temp-")) {
nameMap.remove(entry.getKey()); // throws ConcurrentModificationException
}
}In such cases, we can iterate and modify the collection using the Iterator.
Iterator<Entry<String, Integer>> iterator = nameMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
if (entry.getKey().equals("Temp-")) {
iterator.remove(); // Safely remove the element
}
}6.2. Using Mutable Keys
It is also a very common issue often seen. It is very important to understand that hashcode of an object, used as the key, should not change else the previously stored entry will be lost. It will lead to memory leakage.
User user = new User(1, "Name");
map.put(user, new Account(...));
user.setname("New Name"); //It changes the hashcode
//Returns null and causes memory leak as Account object is non-reachable
map.get(user);To prevent such leakages, we should use immutable objects as Map keys. An immutable object, once created, cannot be changed so its hashcode also never changes. For this reason, Java wrapper classes and Strings are best suitable to be used as Map keys.
map.put(user.getId(), new Account(...)); //User id cannot be changed7. HashMap Variations and Alternatives
The HashMap is a general-purpose class and does not cater the specific scenarios such as ordering and sorting. In such cases, we should consider using the other Map classes created for specific purposes.
7.1. Maintain Insertion Order with LinkedHashMap
The LinkedHashMap stores the entries in the order they are added. As a result, it provides a predictable iteration order. Note that insertion order is not affected if a key is re-inserted into the map.
Map<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("key1", "value1");
linkedHashMap.put("key2", "value2");7.2. Sorted Keys with TreeMap
If we want to sort the Map entries by the keys, TreeMap will help. The TreeMap is sorted according to the natural ordering of its keys, or by a Comparator provided at map creation time.
Note that maintaining the sorting order puts an additional cost on insertion and resizing operations.
Map<String, String> treeMap = new TreeMap<>();
TreeMap<Integer, String> reversedMap = new TreeMap<>(Collections.reverseOrder());7.3. Thread-Safety with ConcurrentHashMap
The ConcurrentHashMap is very similar to the HashMap class, except that ConcurrentHashMap offers internally maintained concurrency. It means we do not need to have synchronized blocks when accessing its key-value pairs in a multithreaded application.
ConcurrentHashMap<String, String> concurrentMap = new ConcurrentHashMap<>();7.4. Meory Efficiency with WeakHashMap
If we are not able to keep track of entries added to the Map, we should consider using WeakHashMap. An entry in a WeakHashMap will automatically be removed when its key is no longer in ordinary use.
This class is intended primarily for use with key objects whose equals() methods test for object identity using the == operator. Once such a key is discarded it can never be recreated, so it is impossible to do a lookup of that key in a WeakHashMap.
Map<String, String> weakMap = new WeakHashMap<>(); 7.5. Interoperability and Conversion Between Map Types
We can create the instance of another map type, from an existing HashMap, using the Map constructors. Each Map class contains a constructor that accepts another Map type, and initializes the current map with entries of specified map.
In the following example, we are creating a ConcurrentHashMap with the entries stored in an existing HashMap. This technique can be used for any kind of Map conversion.
HashMap<String, String> hashMap = new HashMap<>();
//add few entries
// create ConcurrentHashMap with entries from HashMap
ConcurrentHashMap<String, String> concurrentMap = new ConcurrentHashMap<>(hashMap);8. Real-world Use Cases of HashMap
HashMaps are widely used in various real-world scenarios due to their efficient key-value pairs storage and retrieval. Let us see a few popular usages:
8.1. Caching with HashMap
HashMaps are used to implement temporary caching mechanisms in small applications where configuring and using a full-fledged caching solution will be overdone.
It also helps in improving performance by reducing the extra interactions with the cache system or database. It can be an alternative to an in-memory database also for a small dataset.
8.2. Frequency Counting and Word Occurrence
HashMaps can be used to count occurrences of items or elements in a dataset, making them valuable for frequency analysis-related jobs. It is very helpful in natural language processing and text processing.
String[] items = {"apple", "banana", "orange", "apple", "grape", "banana", "apple"};
HashMap<String, Integer> itemOccurrences = new HashMap<>();
for (String item : items) {
itemOccurrences.put(item, itemOccurrences.getOrDefault(item, 0) + 1);
}
System.out.println(itemOccurrences); // {banana=2, orange=1, apple=3, grape=1}8.3. Graph Algorithms
In graph algorithms (such as graph traversal and shortest path algorithm), HashMap is commonly used to store graph nodes and their properties. It can also efficiently represent an adjacency list representation.
Using HashMap makes these algorithms efficient and easy to implement.
10. Conclusion
The HashMap class is an integral part of Java Collections and is used as an important pillar in many critical designs. Finally, to conclude the article, let us reiterate what we learned in this article:
- HashMap stores key-value pairs (also called entries).
- HashMap cannot contain duplicate keys.
- HashMap allows multiple null values but only one null key.
- HashMap is an unordered collection. It does not guarantee any specific order of the elements.
- HashMap is not thread-safe. You must explicitly synchronize concurrent modifications to the HashMap. Or you can use Collections.synchronizedMap(hashMap) to get the synchronized version of HashMap.
- A value can be retrieved only using the associated key.
- HashMap stores only object references. So use a wrapper class or String to create the Map keys.
- HashMap implements Cloneable and Serializable interfaces.
11. HashMap Examples
- How HashMap works in Java
- Performance Comparison of Different Ways to Iterate over HashMap
- How to design a good custom key object for HashMap
- Difference between HashMap and Hashtable in Java
- Java sort Map by keys (ascending and descending orders)
- Java sort Map by values (ascending and descending orders)
- Java hashCode() and equals() – Contract, rules and best practices
- HashMap and ConcurrentHashMap Interview Questions
- Java ConcurrentHashMap Best Practices
- Convert JSON to Map and Map to JSON
- Marshal and Unmarshal HashMap in Java
- How to Find Duplicate Words in String using HashMap
- Compare two hashmaps
- Synchronize HashMap
- Merge two HashMaps
- How to clone a HashMap
Happy Learning !!