
Learn to improve the performance of ConcurrentHashMap by optimizing the constructor arguments in a sensible manner.
1. ConcurrentHashMap class
The ConcurrentHashMap is very similar to the HashMap class, except that ConcurrentHashMap offers internally maintained concurrency. It means we do not need to have synchronized blocks when accessing its key-value pairs in a multithreaded application.
//Initialize ConcurrentHashMap instance
ConcurrentHashMap<String, Integer> m = new ConcurrentHashMap<>();
//Print all values stored in ConcurrentHashMap instance
for each (Entry<String, Integer> e : m.entrySet())
{
system.out.println(e.getKey()+"="+e.getValue());
}Above code is reasonably valid in a multi-threaded environment in an application. The reason, I am saying “reasonably valid” is that the above code provides thread safety, but still it can decrease the performance of the application. And ConcurrentHashMap was introduced to improve the performance while ensuring thread safety, right??
So, what is that we are missing here??
2. The Default Constructor and Arguments
To understand that we need to understand the internal working of ConcurrentHashMap class. And the best way to start is to look at the constructor arguments. A fully parametrized constructor of ConcurrentHashMap takes 3 parameters:
initialCapacityloadFactorconcurrencyLevel
The first two arguments are fairly simple as their name implies but the last one is tricky. The concurrencyLevel denotes the number of shards. It is used to divide the ConcurrentHashMap internally into this number of partitions, and an equal number of threads are created to maintain thread safety maintained at the shard level.
The default value of “concurrencyLevel” is 16.
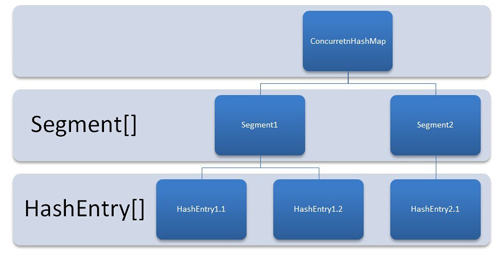
- It means 16 shards whenever we create an instance of ConcurrentHashMap using the default constructor, before even adding first key-value pair.
- It also means the creation of instances for various inner classes like ConcurrentHashMap$Segment, ConcurrentHashMap$HashEntry[] and ReentrantLock$NonfairSync.
In most cases in normal applications, a single shard is able to handle multiple threads with a reasonable count of key-value pairs. And performance will also be optimal. Having multiple shards just makes things complex internally and introduces a lot of unnecessary objects for garbage collection, and all this for no performance improvement.
The extra objects created per concurrent hashmap using the default constructor are normally in the ratio of 1 to 50 i.e. for 100 such instances of ConcurrentHashMap, there will be 5000 extra objects created.
3. Recommended Initialization
Based on the above analysis, I will suggest to use the constructor parameters wisely to reduce the number of unnecessary objects and improve the map’s performance.
A good approach can be having initialization like this:
ConcurrentHashMap<String, Integer> instance = new ConcurrentHashMap<String, Integer>(16, 0.9f, 1);- An initial capacity of 16 ensures a reasonably good number of elements before resizing happens.
- A load factor of 0.9 ensures a dense packaging inside ConcurrentHashMap which will optimize memory use.
- And concurrency level set to 1 will ensure that only one shard is created and maintained.
Please note that if you are working on a very high concurrent application with a very high frequency of updates in ConcurrentHashMap, you should consider increasing the concurrency level by more than 1, but again it should be a well-calculated number to get the best results.
Happy Learning !!
Hi ,
Can you explain internal working if it is possible
?
My question is suppose a iteration is going on the list as its read there is no lock. In between a write is done. Now control comes back to iteration so i think now concurrentModification will be thrown. Could you please explain how above scenario is handled. Is there any way to replicate such scenario?
Modification is being done on the copy of original map so the user will be able to see the original map that was present before current iteration. As soon as iteration completes the new map will be available for read purpose.
Hi lokesh,
Nice articles. Thanks for sharing n making our work easier. Could you please explain what is meaning of volatile read and what is its internal working?
Irrelevant?
When looking at the constructors of ConcurrentHashMap, the concurrencyLevel parameter does not do much, only to adjust the initialcapacity parameter if it is smaller than concurlevel.
Knowing these things become relevant when you go for performance improvement of application/ or avoid future performance issues, specially in high volume application.
Hi,
Thanks for this amazing blog, concepts are very well explained. When you get a chance could you please answer my question –
1. Say for example I have multiple threads (count = 8) that would add or update my Hashmap. What would be concurrencyLevel you would recommend?
2.
Won’t they have almost same performance since ConcurrentHashMap has only 1 Segment and all Threads will have to wait while updating HashEntry?
+1, also HashTable would give the same performance.
Article contains important details which are rarely explained on this subject. Thanks Lokesh really helped.
Thanks, nice post
what is meant by dense packaging inside ConcurrentHashMap ?
Load factor is the ratio between the number of “buckets” in the map and the number of expected elements. A value of 0.75 will suggest that if the buckets are more than 75% full, the Map should be resized. Similarly, 0.90 will suggest that if the buckets are more than 90% full, the Map should be resized.
This clarified my doubt, Thanks Lokesh,Vishal for asking it.
I think you are wrong regarding your load factor explanation.
If hashCode always returns 1, which means all entries will go to 1 bucket only. Do you mean the map will never resize?
You are right. Rehashing may never occur in such if load factor
>=1. But it will lead to very high number of collisions, badly impacting the performance.So the correct definition of load factor should be
the ratio between
1) the number of “Entries”
2) initialCapacity
not as you said
1) the number of “buckets” in the map
2) the number of expected elements.
Please be really cautious with basic knowledge of HashMap.
Thanks for clarification.
Nice article. But I would suggest one small correction
“First two are fairly simple as their name implies but last one is tricky part. This denotes the number of shards. ”
The parameter concurrencyLevel isn’t always equal to the number of segments created. It will only be true if it is a power of 2.
True. This parameter should be in power of two.
What is the bucket in HashMap ?
is it the Entry Array ? I am looking for collision condition solution when we have same hash code for 2 objcets.
In case of collision , objects are stored in same bucket and retrieved using equals function to get exact object.
Yes. Bucket is single index location in Entry array. If entry array is of size 10, the there are 10 buckets. Regarding conflict, I have written about internal working of HashMap. Please refer to linked post.
Hi,
I have doubt over the concurrencyLevel parameter.
Suppose I have initialized my ConcurrentHashMap with concurrencyLevel of 2.
I have 2 threads trying to update the first shard elements @ same time.
How this situation will be handled?
Do we need to apply extra care and synchronization for such cases ? Or it is handled internally by ConcurrentHashMap itself ?
No need to add extra synchronization. ConcurrentHashMap uses locks in put method.
https://github.com/openjdk/jdk/blob/master/src/java.base/share/classes/java/util/concurrent/ConcurrentHashMap.java
Hi,
No doubt it’s a wonderfull post. But I have two questions.
1) Is Shards and Segments are same?
2) What is the use of Segment
1) Yes, both are same.
2) Segments are to create different “groups of key-value pairs” so that different groups can be used used concurrently by different threads.
Is that means that each segments contains same key-value pair? Secondly if I create 20 shards then it means that 20 threads can do concurrent transaction on my map. Correct me if I am wrong.
Is that possible for you to explain that if I enter a key value pair in the concurrent hash map how it’s getting updated in multiple segments.
NO. A key-value pair inserted in ConcurrentHashMap will be stored in one-and-only-one segment. Let say you store 200 key-value pairs in ConcurrentHashMap having 20 segments, and if they are distributed equally the each segment will have 10 key-value pairs. Now these 20 shards are available to be concurrently accessed by 20 different threads.
If you try to lookup for value for any key, then first suitable segment is located and then suitable entry is located inside segment.
As I understand from the above one that each shard will serve one thread. If I create 100 shard then concurrently 100 threads can access the values. Now, suppose I have a Key =”A” and it’s stored in the Segment 1. Now if two threads are concurrently wants to access the values with the Key “A” then will the second thread will wait till the first thread leaves the lock of the Shard?
Do you know the logic to choose the Shard to store the key value?
Suppose a value with the Key “A” inserted in to #5 segment. Now two threads wants to read the value with the key “A”. Then what would happens will the second thread will wait for the first thread to complete it’s task.
Secondly, Could you explain that how Concurrent Hashmap choose segment to store the data or to retrieve.
To me, its some complex mathematics for locating the segment.
int hash = hash(key.hashCode());int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
To read value, it used UNSAFE.getObjectVolatile();
Refer: https://github.com/openjdk/jdk/blob/master/src/jdk.unsupported/share/classes/sun/misc/Unsafe.java
https://en.wikipedia.org/wiki/Volatile_variable
And
https://howtodoinjava.com/java-examples/usage-of-class-sun-misc-unsafe/
Nice article..Thanks for that..Suppose I am having a concurrent hashmap with Concurrency level as 2 and i need to read/write values in it by using multiple threads .In the scenario, if one thread has locked up one segment and checking the value and if another thread comes in will it bypass that segment or wait ?
In case of bypass, how come it will check the locked up segment..(because my scenario is to check whole map for a particular count).
You will have more clear picture after reading this post:
https://howtodoinjava.com/interview-questions/hashmap-concurrenthashmap-interview-questions/
“When getting data, a volatile read is used without any synchronization. If the volatile read results in a miss, then the lock for that segment is obtained and entry is again searched in synchronized block.”