In “How HashMap works in Java“, we learned the internals of HashMap or ConcurrentHashMap class and how they fit into the whole concept. But when the interviewer asks you about HashMap related concepts, he does not stop only on the core concept. The discussion usually goes in multiple directions to understand whether you really understand the concept or not.
In this post, we will try to cover some related interview questions on HashMap and ConcurrentHashMap.
1. How to Design a Good Key for HashMap
The very basic need for designing a good key is that “we should be able to retrieve the value object back from the map without failure“, right?? Otherwise no matter how fancy the data structure you build, it will be of no use.
Key’s hashcode() is used primarily in conjunction with its equals() method, for putting a key in the Map and then searching it back from Map. So if the hashcode of the key object changes after we have put a key-value pair in the Map, then it is almost impossible to fetch the value object back from the Map. It will also cause a memory leak. To avoid this, map keys should be immutable. These are a few things to create an immutable class.
This is the main reason why immutable classes like String, Integer or other wrapper classes are good candidates for creating the Map Keys.
But remember that immutability is recommended but not mandatory. If we want to make a mutable object as a key in a Map, then we have to make sure that the state change for the key object does not change the hashcode of object. This can be done by overriding the hashCode() method. Also, key class must honor the hashCode() and equals() methods contract to avoid the undesired and surprising behavior on run time.
More detailed information is available here.
2. Difference between HashMap and ConcurrentHashMap?
To better visualize the ConcurrentHashMap, let it consider as a group of HashMap instances. To get and put key-value pairs from hashmap, we have to calculate the hashcode and look for correct bucket location in array of Collection.Entry.
In ConcurrentHashMap, the difference lies in the internal structure to store these key-value pairs. ConcurrentHashMap has an additional concept of segments.
It will be easier to understand it you think of one segment equal to one HashMap [conceptually]. A concurrentHashMap is divided into number of segments [default 16] on initialization. ConcurrentHashMap allows similar number (16) of threads to access these segments concurrently so that each thread work on a specific segment during high concurrency.
This way, if when your key-value pair is stored in segment 10; code does not need to block other 15 segments additionally. This structure provides a very high level of concurrency.
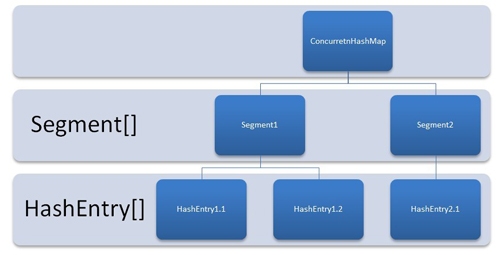
In other words, ConcurrentHashMap uses a multitude of locks, each lock controls one segment of the map. When setting data in a particular segment, the lock for that segment is obtained. So essentially update operations are synchronized.
When getting data, a volatile read is used without any synchronization. If the volatile read results in a miss, then the lock for that segment is obtained and entry is again searched in synchronized block.
3. Difference between HashMap and Collections.synchronizedMap()?
HashMap is non-synchronized and Collections.synchronizedMap() returns a wrapped instance of HashMap which has all get, put methods synchronized.
Essentially, Collections.synchronizedMap() returns the reference of internally created inner-class “SynchronizedMap”, which contains key-value pairs of input HashMap, passed as argument.
This instance of inner class has nothing to do with original parameter HashMap instance and is completely independent.
4. Difference between ConcurrentHashMap and Collections.synchronizedMap()?
This one is a slightly complex question. Both are synchronized version of HashMap, with difference in their core functionality and internal structure.
As stated above, ConcurrentHashMap is consist of internal segments which can be viewed as independent HashMap instances, conceptually. All such segments can be locked by separate threads in high concurrent executions. In this way, multiple threads can get/put key-value pairs from ConcurrentHashMap without blocking/waiting for each other.
In Collections.synchronizedMap(), we get a synchronized version of HashMap and it is accessed in blocking manner. This means if multiple threads try to access synchronizedMap at same time, they will be allowed to get/put key-value pairs one at a time in synchronized manner.
5. Difference between HashMap and HashTable
It is also very easy question. The major difference is that HashTable is synchronized and HashMap is not.
If asked for other reasons, tell them, HashTable is legacy class (part of JDK 1.0) which was promoted into collections framework by implementing Map interface later. It still has some extra features like Enumerator with it, which HashMap lacks.
Another minor reason can be: HashMap supports null key (mapped to zero bucket), HashTable does not support null keys and throws NullPointerException on such attempt.
6. Difference between HashTable and Collections.synchronized(Map)?
Both are synchronized version of collection. Both have synchronized methods inside class. Both are blocking in nature i.e. multiple threads will need to wait for getting the lock on instance before putting/getting anything out of it.
So what is the difference. Well, NO major difference for above said reasons. Performance is also same for both collections.
Only thing which separates them is the fact HashTable is legacy class promoted into collection framework. It got its own extra features like enumerators.
7. Impact of Random or Fixed hashcode()?
The impact of both cases (fixed hashcode or random hashcode for keys) will have same result and that is “unexpected behavior“. The very basic need of hashcode in HashMap is to identify the bucket location where to put the key-value pair, and from where it has to be retrieved.
If the hashcode of key object changes every time, the exact location of key-value pair will be calculated different, every time. This way, one object stored in HashMap will be lost forever and there will be very minimum possibility to get it back from map.
If hashcode() is a fixed value for all objects, then all the objects will be stored in a single bucket that will degrade the Map performance.
For this same reason, key are suggested to be immutable, so that they return a unique and same hashcode each time requested on the same key object.
8. Can we use HashMap in Concurrent Application?
In normal cases, concurrent accesses can leave the hashmap in inconsistent state where key-value pairs added and retrieved can be different. Apart from this, other surprising behavior like NullPointerException can come into picture.
In worst case, It can cause infinite loop. YES. You got it right. It can cause infinite loop. What did you asked, How?? Well, here is the reason.
HashMap has the concept of rehashing when it reaches to its upper limit of size. This rehashing is the process of creating a new memory area, and copying all the already present key-value pairs in new memory are.
Let’s say thread A tried to put a key-value pair in map and then rehashing started. At the same time, thread B came and started manipulating the buckets using put() operation.
Here while rehashing process, there are chances to generate the cyclic dependency where one element in linked list [in any bucket] can point to any previous node in same bucket. This will result in infinite loop, because rehashing code contains a “while(true) { //get next node; }” block and in cyclic dependency it will run infinite.
To watch closely, look at source code of transfer method which is used in rehashing:
public Object get(Object key) {
Object k = maskNull(key);
int hash = hash(k);
int i = indexFor(hash, table.length);
Entry e = table[i];
//While true is always a bad practice and cause infinite loops
while (true) {
if (e == null)
return e;
if (e.hash == hash & eq(k, e.key))
return e.value;
e = e.next;
}
}I hope I was able to put some more items on your knowledge bucket for hashmap interview questions and ConcurrentHashMap interview questions. If you find this article helpful, please consider it sharing with your friends.
Happy Learning !!
Thank you very much Lokesh. The explanation indeed answered my query.
I am now bit more confused on hashcodes of objects and the hashcode of the keys.
I have read the post of hashmap internal working and am quite clear of it’s working now.
But at the same time am little bit confused.
Could you kindly make your time to explain me the following:
1. How to relate hashcode of objects, hashcode of keys and the array location/bucket concept.
2. As Entry is a nested class of the Map and the usage of Entry object is again a key, value pair.
If I have understood properly, Entry has ‘next’ attribute which helps in pointing to next object in the linked list structure.
But how the key, value pair are internally shown here in the bucket.
And what exactly does Entry object mean.
Is it simply a view of mapping of key, value pair as in ‘entry Set view’ or different.
Sorry that seems to be basic or silly question, but am confused and need a little help here.
You all questions has been answered here : https://howtodoinjava.com/java/collections/hashmap/how-hashmap-works-in-java/
Hi Lokesh,
Can you kindly please brief on this. I had completely drifted away by the explanation of random/fixed hashcode() value for key.
————————————————————————————————————————
If the hashcode of key object changes every time, the exact location of key-value pair will be calculated different, every time. This way, one object stored in HashMap will be lost forever and there will be very minimum possibility to get it back from map.
For this same reason, key are suggested to be immutable, so that they return a unique and same hashcode each time requested on same key object.
————————————————————————————————————————
When hashcodes for different objects are recommended to be different, how does the above comment justifies the recommendation.
Kindly explain!
Let’s look at below example:
import java.util.HashMap; import java.util.Random; public class HashCodeTest { public static void main(String[] args) { HashMap<Key, String> map = new HashMap<Key, String>(); map.put(new Key(1), "One"); System.out.println(map.get(new Key(1))); } } class Key { public Key(Integer k){ this.i = k; } private Integer i; public Integer getI() { return i; } public void setI(Integer i) { this.i = i; } @Override public int hashCode() { return new Random().nextInt(); } @Override public boolean equals(Object anotherKey) { return this.i == ((Key)anotherKey).getI(); } } Output (if you execute above program n times) : nullYou are not able to get the value back which you set for key(1). Try something you think logical and get back the value “One” from map. You will not be able to. Why? because hashcode generated for key(1) was random and you cannot produce same hashcode again with this code (if you do not try it million times).
Now change the hashCode as below:
@Override public int hashCode() { return this.i * 31; }Now you will be able to get value “One” back everytime, because hashcode for key(1) is fixed to be 1*31. Similarly, hash code for key(2) will be 2*32. All different objects will produce different hashcodes; and same key will have same hashcode everytime. In this way only you can guarantee that you will be able to get value back from hashmap.
I hope I answered your query. If not then please let me know.
Hi Lokesh,
Thankyou for your over Hopefully site, Its really amaging and usefull for us, I m new to java and trying learning concept and obviously i found very greatful by your given theme. Thankyou so much.
Lokesh – Here i m unable to understand by one of your given comment in post, plz clear to me.
1) How to design a good key for HashMap
Key’s hash code is used primarily in conjunction to its equals() method, for putting a key in map and then searching it back from map.
What does conjunction means here.?
can u plz clear to me?
Thanks in advance.
Devesh A
I mean here that hash code and equals method work together.
good way to explain the hash map
Thanks Lokesh!!! I read your post – “How Hashmap works”. It helped me understand how it finds the right bucket to place/fetch element. I am wondering how does ConcurrentHashmap find the right Segment(Hashmap) to put/get element. Can you please help?
what is the Legacy class? why they are not supposed to use in new versions of JDK ?
Legacy means available from very starting. OR “anything handed down from the past”. It’s not meant any particular class.
Thanks lokesh. but why they are not supposed to use in new versions of JDK ?
Where I have written that they are not present in latest JDKs? ALL JDK releases were/are backward compatible. None of the class ever got removed.
it eems java 1.7 does not ha whie (true) case that cause infinite loop..correct if its wrong
public V put(K paramK, V paramV)
{
if (paramK == null)
return putForNullKey(paramV);
int i = hash(paramK.hashCode());
int j = indexFor(i, this.table.length);
for (Entry localEntry = this.table[j]; localEntry != null; localEntry = localEntry.next)
{
Object localObject1;
if ((localEntry.hash == i) && (((localObject1 = localEntry.key) == paramK) || (paramK.equals(localObject1))))
{
Object localObject2 = localEntry.value;
localEntry.value = paramV;
localEntry.recordAccess(this);
return localObject2;
}
}
this.modCount += 1;
addEntry(i, paramK, paramV, j);
return null;
}
you are right. they corrected it.
The infinite loop is also removed from java 1.6
Thanks for the nice post. But I have a question.
In #2 you have mentioned something “When getting data, a volatile read is used”. Could you explain a bit that what you want to describe as Volatile Read.
Hi,
In question #2 you have mentioned the concurrentHashMap reads the data through “volatile read”. What you actually means by Volatile read.
thanks for sharing this post this post clear all my concept about hash map and hash table
Lokesh,
Very useful article. Thanks for providing such a detailed explanation. It would be very helpful if you could elaborate the race condition issue with HashMap in multi threaded environment with example.
Unless and Until some one is doing research or some one is developing new data structures going into the internals of data structures is merely a waste of valuable time. SUN / oracle has provided us these data structures after much research, so just keep use this appropriately,
Western Interviewers are interested to know only the correct usage and also upto their project. Indians tend to deviate this and spends time un necessarily.
Respectfully disagree. I believe that to use something better, one needs to understand how it works. At least, I can expect good APIs only from those who know how things function internally. If you know the rules better, you will play better.
Very mature response Lokesh. And Good article.
I don’t think there is difference between ‘western’ and ‘eastern’ interviewers. You will find all types, everywhere. Knowledge of internals always makes things better.
What the ****!! Are you ****ing insane?? You guys ask such crazy questions during interviews and expect to people to shit about it…
Why did Sun/Oracle ever expose API’s??? There is a reason behind it.
Any CS graduate/Software Developer will advise you to “RE-USE”. Don’t reinvent the wheel..
Hey Mike, You seems to be so angry for no reason. If everybody follow your advice, then there will never be any new improvement in JDK releases and eventually there will never be any performance improvement. Sorry for the hard words, if they offend you. But I am and I like the guys who just go deep inside every concept and develop their own thought process. If CS grads are like what you are saying, thank god I am not one of them.
Unfortunately Mike is quite right although his way of expressing himself is not appropriate. I have been in this business for a very long time and it is typical of some culture to prepare themselves with such 1-million dollar questions so that they seem to know everything and be so good and then are just not even more than an average, IN AVERAGE of course. There are good and bad everywhere. There are people who knows software better and there are people who knows better how to have a good interview . I am quite annoyed about this way of doing it and I certainly do not perform any interview with such questions. I rather go for problem solving. It is up to the candidate to come up with the solution whatever he achieved this by digging in the API which is by the way a good way to learn, studying, or his IQ. To me does not matter.
I would like to add something I forgot to my own comment below: by looking at the internals API you also expose yourself to the implementation changes of the API which might have the exact opposite effect of what you were looking for in first place. An object is free to change its implementation, hopefully in better!, without changing the API. The API should be clear in how it should be used and what performance are achieved. To know a hash has performance close to K-constant, or rehashing impact is more important than other details.
a RE-USE is an important aspect of software development which should be known and more popular than some details. I mean details are optional, OOP concepts like RE-USE I don’t consider them optional.
So I don’t understand what you have to be so proud to say that you are not one of the CS grads, in that particular aspect.I think in reality you don’t but you have been aggravated by Mike posting! I hope so at least.
The performance improvement should be found in the implementation of the object itself , not in the underlying object. I improve my code not the code of all the software APIs I use or directly through it. I must know which are the best performing API and I will choose that one I like the most.
These sometime maniacal form of looking to details which takes you closer to a hacker than a software developer I think in my personal opinion is coming from software (like Microsoft) which on purpose is not well documented and hiding details (see the billions of fines they got for not releasing information to allow a free competition, fine issues by both the US and even more Europe). That’s why I like open source software, which is correctly a Development Model not a business model as many think.
Hey Fabrizio, that’s real big comment and it can be a separate article in itself (seriously). I do agree with more of what you said in between both comments and also about “aggravated” part. Further, I would like to close this discussion being mostly agree with you and a little disagree. Thanks for your views here, I really appreciate it.
I Disagree. Unless and until you know the internals, you can’t use the API’s efficiently.
If the API is properly documented you don’t need to know the internals and this should be always the case. Unfortunately it is not. Otherwise you break the concept of OOD/OOP where the object is opaque and you don’t need to look at it (for me an API is the interface to an object). OOD/OOP is necessary to decompose a bigger problem in a collection of smaller ones ignoring the details of the smaller ones that becomes your building blocks. People can’t hold any given size-problem. Somone is looking at one of the smaller problem ignoring the others and will know the details and in turn will use the API of other underlying objects and the cycle repeats.. Otherwise whatever size is the project, you will have to dig and know everything and you never end. At this point why not to know one more lawyer and how the JVM works and the differences on different OSs. I think knowing the internals is a necessity step (only a step) in the learning process of a person. It is an opportunity to understand what are the issues and how have been solved. At any level of abstractions most likely the problem solving method is the same and you must exercise. For that reason I disagree more with your statement than what I disagree with who you replied to, with all due respect to both of you.
Nice. But Need to Mention this:
NOT “HashTable”. The proper one is “Hashtable”, small t.
But your site and content is good.
can we do sorting without using java API?
Definitely.. for example: bubble sort is like this:
public void bubbleSort(int[] array) {
boolean swapped = true;
int j = 0;
int tmp;
while (swapped) {
swapped = false;
j++;
for (int i = 0; i < array.length - j; i++) { if (array[i] > array[i + 1]) {
tmp = array[i];
array[i] = array[i + 1];
array[i + 1] = tmp;
swapped = true;
}
}
}
}
if I override hashCode() method and always return 1000, then what will be the impact on storing and retrieving in HashMap.
As I know all the map.Entry will be stored at single index with a large linkedlist.
Please validate and provide your view.
Yes you are correct. All the key-value pairs will be stored at single bucket in form of large linked list. Now, whole behavior of map comes down on nature of equals() method.
1) If you have not overridden equals() method then you will be able to get value objects back from map, for all different key objects stored. Obviously, similar keys will override the value object. Since, default equals() method in Object class compares reference equality, there are rare chances to get any unexpected result from above said. (Almost impossible)
2) If you have overridden the equals() method, then result of equality from this overridden method will decide that value objects will be replaced or not.
In any case, the only factor is definite is performance hit. You are likely to get performance of O(n) in stead of O(1).