Are you planning to learn core Java? Or is an interview scheduled in the coming days? Do not worry and read all the Java interview questions given below to refresh your concepts and possibly have some new ones added to the list.
1. How to Create an Immutable Object in Java? What are the Benefits?
An immutable class is one whose state can not be changed once created. Here, the state of the object essentially means the values stored in the instance variable in class whether they are primitive types or reference types.
To make a class immutable, the below steps need to be followed:
- Don’t provide “setter” methods or methods that modify fields or objects referred to by fields. Setter methods are meant to change the state of the object, and this is what we want to prevent here.
- Make all fields
finalandprivate. Fields declaredprivatewill not be accessible outside the class and making themfinalwill ensure that even accidentally you can not change them. - Don’t allow subclasses to override methods. The simplest way to do this is to declare the class as
final. Final classes in Java can not be overridden. - Always remember that your instance variables will be either mutable or immutable. Identify them and return new objects with copied content for all mutable objects (object references). Immutable variables (primitive types) can be returned safely without extra effort.
Also, you should memorize the following benefits of the immutable class. You might need them during the interview.
The immutable classes –
- are simple to construct, test, and use
- are automatically thread-safe and have no synchronization issues
- do not need a copy constructor
- do not need an implementation of a clone
- allow hashCode to use lazy initialization, and to cache its return value
- do not need to be copied defensively when used as a field
- make good
Mapkeys andSetelements (these objects must not change state while in the collection) - have their class invariant established once upon construction, and it never needs to be checked again
- always have “failure atomicity” (a term used by Joshua Bloch) : if an immutable object throws an exception, it’s never left in an undesirable or indeterminate state.
2. Is Java Pass by Reference or Pass by Value?
The Java Spec says that everything in Java is pass-by-value. There is no such thing as “pass-by-reference” in Java.
These terms are associated with method calling and passing variables as method parameters. Well, primitive types are always passed by value without any confusion. But, the concept should be understood in the context of method parameters of complex types.
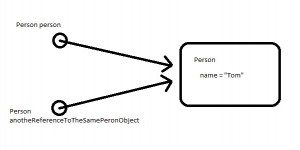
In java, when we pass a reference of complex types as any method parameters, always the memory address is copied to a new reference variable bit by bit. See in below picture:
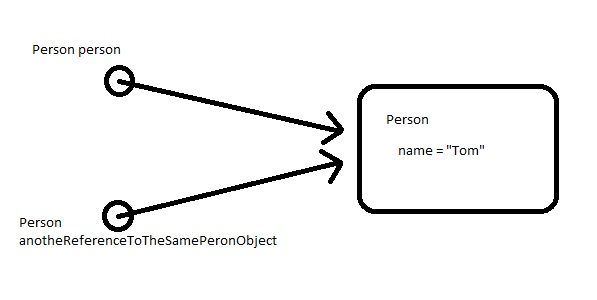
In the above example, address bits of the first instance are copied to another reference variable, thus resulting in both references to point to a single memory location where the actual object is stored. Remember, making another reference to null will not make the first reference also null. But, changing state from either reference variable has an impact seen in other references also.
Read More: Java Pass by Value or Reference?
3. What is the use of the finally block? Is finally block guaranteed to be called? When finally block is not called?
The finally block always executes when the try block exits. This ensures that the finally block is executed even if an unexpected exception occurs. But finally is useful for more than just exception handling — it allows having cleanup code accidentally bypassed by a return, continue, or break. Putting cleanup code in a finally block is always a good practice, even when no exceptions are anticipated.
If the JVM exits while the try or catch code is being executed, then the finally block may not execute.
Likewise, if the thread executing the try or catch code is interrupted or killed, the finally block may not execute even though the application as a whole continues.
4. Why are there two Date classes, One in java.util and another in java.sql?
A java.util.Date represents date and time of day, a java.sql.Date only represents a date.
The complement of java.sql.Date is java.sql.Time, which only represents a time of day.
The java.sql.Date is a subclass (an extension) of java.util.Date. So, what changed in java.sql.Date:
- The
toString()generates a different string representation i.e. yyyy-MM-dd - A
static valueOf(String)methods to create a date from a string with the above representation - The getters and setters for hours, minutes and seconds are deprecated
The java.sql.Date class is used with JDBC, and it was intended not to have a time part, that is, hours, minutes, seconds, and milliseconds should be zero… but this is not enforced by the class.
5. Explain Marker Interfaces?
The marker interface pattern is a design pattern in computer science, used with languages that provide run-time type information about objects. It provides a means to associate metadata with a class where the language does not have explicit support for such metadata. In Java, it is used as an interface with no method specified.
A good example of the use of a marker interface in Java is the Serializable interface. A class Data implementing the Serializable interface indicates that its non-transient data members can be written to byte stream or file system.
A major problem with marker interfaces is that the interface defines a contract for implementing classes, and that contract is inherited by all subclasses. This means that we cannot “un-implement” a marker in child classes.
In the example given, if you create a subclass of Data that we do not want to serialize (perhaps because it depends on the transient state), we must resort to explicitly throwing NotSerializableException.
6. Why main() Method is Declared as public static void?
Why public? the main() method is public so that it can be accessible everywhere and to every object which may desire to use it for launching the application. Here, I am not saying that JDK/JRE had similar reasons because java.exe or javaw.exe (for windows) use Java Native Interface (JNI) calls to invoke method, so they can have invoked it, either way, irrespective of any access modifier.
Why static? Let us suppose we do not have main() method as static. Now, to invoke any method you need an instance of it. Right? Java can have overloaded constructors, we all know. Now, which one should be used and from where the parameters for overloaded constructors will come.
Why void? Then there is no use of returning any value to JVM, who actually invokes this method. The only thing application would like to communicate to invoking process is normal or abnormal termination. This is already possible using System.exit(int). A non-zero value means abnormal termination otherwise everything was fine.
7. What is the difference between a String Object and a Literal?
When we create String with new() it is created in the heap and also added into string pool, while String created using literal are created in String pool area only.
String str1 = new String("test"); //String Object
String str2 = "test"; //String LiteralWell, you really need to know the concept of string pool very deeply to answer this question or similar questions.
8. How does String’s substring() Method Works?
A string in Java is, like any other programming language, a sequence of characters. This is more like a utility class to work on that char sequence. This char sequence is maintained in the following variable:
/** The value is used for character storage. */
private final char value[];To access this array in different scenarios, the following variables are used:
/** The offset is the first index of the storage that is used. */
private final int offset;
/** The count is the number of characters in the String. */
private final int count;Whenever we create a substring from any existing string instance, substring() method only set’s the new values of offset and count variables. The internal char array is unchanged. This is a possible source of a memory leak if substring() method is used without care.
9. Explain the Internal Working of HashMap. How is duplicate collision resolved?
Most of you will agree that HashMap is a most favorite topic for discussion in interviews nowadays. If anybody asks me to describe “How HashMap works?“, I simply answer: “On principles of Hashing“. As simple as it is.
Now, Hashing in its simplest form is a way to assign a unique code for any variable/object after applying any formula/ algorithm to its properties.
A map by definition is : “An object that maps keys to values”. Very easy.. right? So, HashMap has an inner class Entry, which looks like this:
static class Entry<k ,V> implements Map.Entry<k ,V>
{
final K key;
V value;
Entry<k ,V> next;
final int hash;
...//More code goes here
}When someone tries to store a key-value pair in a HashMap, following things happen:
- First of all, key object is checked for null. If key is null, value is stored in
table[0]position. Because the hashcode for null is always 0. - Then on the next step, a hash value is calculated using key hashcode by calling its
hashCode()method. This hash value is used to calculate index in the array for storingEntryobject. JDK designers well assumed that there might be some poorly writtenhashCode()functions that can return very high or low hash code value. To solve this issue, they introduced anotherhash()function, and passed the object’s hash code to thishash()function to bring hash value in the range of array index size. - Now
indexFor(hash, table.length)function is called to calculate the exact index position for storing theEntryobject. - Here comes the main part. Now, as we know that two unequal objects can have the same hash code value, how two different objects will be stored in the same array location [called bucket]. The answer is LinkedList. If you remember, Entry class had an attribute “next”. This attribute always points to the next object in the chain. This is exactly the behavior of
LinkedList.
So, in case of collision, Entry objects are stored in LinkedList form. When an Entry object needs to be stored in particular index, HashMap checks whether there is already an entry?? If there is no entry already present, Entry object is stored in this location.
If there is already an object sitting on the calculated index, its next attribute is checked. If it is null, and the current Entry object becomes the next node in LinkedList. If the next variable is not null, the procedure is followed until next is evaluated as null.
What if we add another value object with the same key as entered before? Logically, it should replace the old value. How it is done? Well, after determining the index position of Entry object, while iterating over LinkedList on calculated index, HashMap calls equals() method on key object for each Entry object. All these Entry objects in LinkedList will have a similar hash code but equals() will test for true equality. If key.equals(k) will be true then both keys are treated as the same key object. This will cause the replacement of value objects inside Entry object only.
In this way, HashMap ensure the uniqueness of keys.
10. What is the difference between Interface and Abstract Class?
This is a very common question if you are appearing for an interview for a junior-level programmer. Well, the most noticeable differences are as below:
- Variables declared in a Java interface is by default
final. An abstract class may contain non-final variables. - Java interfaces are implicitly
abstractand cannot have implementations. A Java abstract class can have instance methods that implement a default behavior. - Members of a Java interface are public by default. A Java abstract class can have the usual flavors of class members like
privateorabstractetc. - Java interface should be implemented using keyword “implements“; A Java abstract class should be extended using keyword “extends“.
- A Java class can implement multiple interfaces but it can extend only one abstract class.
- The interface is
absolutely abstract andcannot be instantiated; A Java abstract class also cannot be instantiated but can be invoked if a main() exists. Since Java 8, you can define default methods in interfaces. - Abstract classes are slightly faster than interfaces because the interface involves a search before calling any overridden method in Java. This is not a significant difference in most cases, but if you are writing a time-critical application, you may not want to leave any stone unturned.
11. When do we Override hashCode() and equals() Methods?
The hashCode() and equals() methods have been defined in Object class which is the parent class for all Java objects. For this reason, all Java objects inherit a default implementation of these methods.
The hashCode() method is used to get a unique integer for a given object. This integer is used for determining the bucket location when this object needs to be stored in some HashTable like data structure. By default, the Object’s hashCode() method returns an integer representation of the memory address where the object is stored.
The equals() method is used to simply verify the equality of two objects. The default implementation simply checks the object references of two objects to verify their equality.
Note that it is generally necessary to override the hashCode() method whenever equals() method is overridden, so as to maintain the general contract for the hashCode() method, which states that equal objects must have equal hash codes.
equals()must define an equality relation (it must be reflexive, symmetric and transitive). In addition, it must be consistent (if the objects are not modified, then it must keep returning the same value). Furthermore,o.equals(null)must always returnfalse.hashCode()must also be consistent (if the object is not modified in terms ofequals(), it must keep returning the same value).
The relation between the two methods is:
Whenever a.equals(b) then a.hashCode() must be the same as b.hashCode().
12. what is the Difference between Deep Copy and Shallow Copy?
A clone is an exact copy of the original. In Java, it essentially means the ability to create an object with a similar state as the original object. The clone() method provides this functionality.
Shallow copies duplicate as little as possible. By default, Java cloning is shallow copy or ‘field by field copy’. Because the Object class can not have any idea about the structure of class on which clone() method will be invoked, JVM when called for cloning, do the following things:
- If the class has only primitive data type members then a completely new copy of the object will be created and the reference to the new object copy will be returned.
- If the class contains members of any class type then only the object references to those members are copied and hence the member references in both the original object as well as the cloned object refer to the same object.
Deep copies duplicate everything. A deep copy of a collection results in two collections with all of the elements in the original collection duplicated. Here, we want a clone that is independent of the original and making changes in the clone should not affect the original.
Deep cloning requires the satisfaction of following rules.
- No need to copy primitives separately.
- All the member classes in the original class should support cloning, and in clone method of the original class in context should call super.clone() on all member classes.
- If any member class does not support cloning, in the clone() method, one must create a new instance of that member class and copy all its attributes one by one to the new member class object. This new member class object will be set in cloned object.
Read more: Java clone – deep and shallow copy – copy constructors
13. What is Synchronization? Explain Object-level Lock and Class-level Lock?
Synchronization refers to adding thread-safety behavior in concurrent applications.
Java supports executing multiple threads parallelly. This may cause two or more threads to access the same fields or objects. Synchronization is a process that keeps all concurrent threads in execution to be in sync. Synchronization avoids memory consistency errors caused due to inconsistent views of shared memory.
When a method is declared as synchronized; the thread holds the monitor for that method’s object If another thread is executing the synchronized method, your thread is blocked until that thread releases the monitor.
Synchronization in Java is achieved using synchronized keyword. we can use synchronized keyword in our class on defined methods or blocks. Keywords can not be used with variables or attributes in the class definition.
Object-level locking is a mechanism when you want to synchronize a non-static method or non-static code block such that only one thread will be able to execute the code block on a given instance of the class. This should always be done to make instance-level data thread-safe.
Class-level locking prevents multiple threads to enter in synchronized block in any of all available instances on runtime. This means if in runtime there are 100 instances of a class, then only one thread will be able to execute a method in any one instance at a time, and all other instances will be locked for other threads. This should always be done to make static data thread-safe.
14. Difference between sleep() and wait() Methods?
- The sleep() is used to hold the process for a few seconds or the time we passed as the method argument. But in the case of wait() method, the thread goes in a waiting state and it won’t come back automatically until another thread invokes the notify() or notifyAll().
- The major difference is that wait() releases the lock while sleep() doesn’t release the lock or monitor while waiting.
- The wait() is used for inter-thread communication while sleep() is used to introduce pause on execution, generally.
Thread.sleep() sends the current thread into the “Not Runnable” state for some time. The thread keeps the monitors it has acquired — i.e. if the thread is currently in a synchronized block or method no other thread can enter this block or method.
If another thread calls t.interrupt() it will wake up the sleeping thread. Note that sleep is a static method, which means that it always affects the current thread (the one that is executing the sleep method). A common mistake is to call t.sleep() where t is a different thread; even then, it is the current thread that will sleep, not the t thread.
The object.wait() sends the current thread into the “Not Runnable” state, like sleep(), but with a twist. The wait() is called on an object, not a thread; we call this object the “lock object.”
Before lock.wait() is called, the current thread must synchronize on the lock object; wait() then releases this lock, and adds the thread to the “waitlist” associated with the lock.
Later, another thread can synchronize on the same lock object and call lock.notify(). This wakes up the original, waiting thread. Basically, wait()/notify() is like sleep()/interrupt(), only the active thread does not need a direct pointer to the sleeping thread, but only to the shared lock object.
15. Can We Assign ‘null‘ to ‘this‘ Reference Variable?
NO. We can’t. In Java, the left-hand side of an assignment statement must be a variable. ‘this‘ is a special keyword that represents the current instance always. This is not any variable.
Similarly, null can not be assigned to ‘super‘ or any such keyword for that matter.
16. What is the Difference between ‘&&’ and ‘&’ Operators??
The & is a bitwise operator and && is a logical comparison operator.
- & evaluates both sides of the operation.
- && evaluates the left side of the operation, if it’s true, it continues and evaluates the right side.
17. Explain All Access Modifiers?
Java classes, fields, constructors and methods can have one of the four different access modifiers:
private: If a method or variable is marked as private, then only code inside the same class can access the variable, or call the method. Code inside subclasses cannot access the variable or method, nor can code from any external class.
If a class is marked as private then no external class can access the class. This doesn’t really make so much sense for classes though. Therefore, the access modifier private is mostly used for fields, constructors and methods.
default: The default access level is declared by not writing any access modifier at all. Default access levels mean that code inside the class itself + code inside classes in the same package as this class, can access the class, field, constructor or method. Therefore, the default access modifier is also sometimes called a package access modifier.
Subclasses cannot access methods and member variables in the superclass if they have default accessibility declared unless the subclass is located in the same package as the superclass.
protected: The protected access modifier does the same as the default access, except subclasses can also access protected methods and member variables of the superclass. This is true even if the subclass is not located in the same package as the superclass.
public: The public access modifier means that all code can access the class, field, constructor or method, regardless of where the accessing code is located.
| Modifiers | Same Class | Same Package | Subclass | Other packages |
| public | Y | Y | Y | Y |
| protected | Y | Y | Y | N |
| default | Y | Y | N | N |
| private | Y | N | N | N |
18. What is Garbage Collection? Can We Enforce It?
Garbage collection is an automatic memory management feature in many modern programming languages, such as Java and languages in the .NET framework. Languages that use garbage collection are often interpreted or run within a virtual machine like the JVM.
In each case, the environment that runs the code is also responsible for garbage collection. A GC has two goals: any unused memory should be freed, and no memory should be freed unless the program will not use it anymore.
Can you force garbage collection?? Nope, System.gc() is as close as you can get. Our best option is to call System.gc() which simply hints to the garbage collector that you want to invoke the garbage collection.
There is no way to force an immediate collection though as the garbage collector is non-deterministic. Also, under the documentation for OutOfMemoryError it declares that it will not be thrown unless the VM has failed to reclaim memory following a full garbage collection. So if you keep allocating memory until you get the error, you will have already forced a full garbage collection.
19. What is ‘native‘ Keyword? Explain in Detail.
The native keyword is applied to a method to indicate that the method is implemented in native code using JNI. It marks a method, that it will be implemented in other languages, not in Java.
Native methods were used in the past to write performance-critical sections but with Java getting faster this is now less common. Native methods are currently needed when
- You need to call a library from Java that is written in another language.
- You need to access system or hardware resources that are only reachable from the other language (typically C). Actually, many system functions that interact with the real computers (disk and network IO, for instance) can only do this because they call native code.
The downsides of using native code libraries are also significant:
- JNI / JNA have a tendency to destabilize the JVM, especially if you try to do something complicated. If your native code gets native code memory management wrong, there’s a chance that you will crash the JVM. If your native code is non-reentrant and gets called from more than one Java thread, bad things will happen … sporadically. And so on.
- Java with native code is harder to debug than pure Java or pure C/C++.
- Native code can introduce significant platform dependencies/issues for an otherwise platform-independent Java app.
- Native code requires a separate build framework, and that may have platform/portability issues as well.
20. What is Serialization? Explain the Catches.
In computer science, in the context of data storage and transmission, serialization is the process of translating data structures or object states into a format that can be stored and “resurrected” later in the same or another computer environment. When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object.
Java provides automatic serialization which requires that the object be marked by implementing the java.io.Serializable interface. Implementing the interface marks the class as “okay to serialize,” and Java then handles serialization internally.
There are no serialization methods defined on the Serializable interface (marker interface), but a serializable class can optionally define methods with certain special names and signatures that if defined, will be called as part of the serialization/deserialization process.
Once an object is serialized, changes in its class break the de-serialization process. To identify the future changes in your class which will be compatible and others that will prove incompatible, please read the full guide here. In short, I am listing down here:
Incompatible changes
- Deleting fields
- Moving classes up or down the hierarchy
- Changing a non-static field to static or a non-transient field to transient
- Changing the declared type of a primitive field
- Changing the writeObject or readObject method so that it no longer writes or reads the default field data
- Changing a class from Serializable to Externalizable or vice-versa
- Changing a class from a non-enum type to an enum type or vice versa
- Removing either Serializable or Externalizable
- Adding the writeReplace or readResolve method to a class
Compatible changes
- Adding fields
- Adding/ Removing classes
- Adding writeObject/readObject methods [defaultReadObject or defaultWriteObject should be called first]
- Removing writeObject/readObject methods
- Adding java.io.Serializable
- Changing the access to a field
- Changing a field from static to non-static or transient to non-transient
21. Can we use HashMap in Concurrent Environment?
We know that HashMap is a non-synchronized collection whereas its synchronized counterpart is HashTable. We should not use HashMap in a concurrent environment.
So, when you are accessing the collection in a multithreaded environment and all threads are accessing a single instance of collection, then it’s safer to use HashTable for various obvious reasons e.g. to avoid dirty reads and to maintain data consistency. In the worst case, this multithreaded environment can result in an infinite loop as well.
22. Explain Abstraction and Encapsulation? Their Differences?
Abstraction
Abstraction captures only those details about an object that are relevant to the current perspective. In object-oriented programming theory, abstraction involves the facility to define objects that represent abstract “actors” that can perform work, report on and change their state, and “communicate” with other objects in the system.
Abstraction in any programming language works in many ways. It can be seen from creating subroutines to defining interfaces for making low-level language calls. Some abstractions try to limit the breadth of concepts a programmer needs, by completely hiding the abstractions they, in turn, are built on, e.g. design patterns.
Typically abstraction can be seen in two ways:
Data abstraction is the way to create complex data types and expose only meaningful operations to interact with the data type, whereas hiding all the implementation details from outside works.
Control abstraction is the process of identifying all such statements and exposing them as a unit of work. We normally use this feature when we create a function to perform any work.
Encapsulation
Wrapping data and methods within classes in combination with implementation hiding (through access control) is often called encapsulation. The result is a data type with characteristics and behaviors. Encapsulation essentially has both i.e. information hiding and implementation hiding.
“Whatever changes, encapsulate it“. It has been quoted as a famous design principle. For that matter in any class, changes can happen in data in runtime and changes in implementation can happen in future releases. So, encapsulation applies to both i.e. data as well as implementation.
SO, they can relate like following :
– Abstraction is more about ‘What‘ a class can do. [Idea]
– Encapsulation is more about ‘How‘ to achieve that functionality. [Implementation]
23. How StringBuffer saves the Memory?
A String is implemented as an immutable object; that is when you initially decide to put something into a String object, the JVM allocates a fixed-width array of exactly the size of your initial value. This is then treated as a constant inside the JVM, which allows for very significant performance savings in the case where the String’s value is not changed.
However, if you decide to change the String’s contents in any way, what the JVM then essentially does is copy the contents of the original String into a temporary space, make your changes, then save those changes into a whole new memory array. Thus, making changes to a String’s value after initialization is a fairly expensive operation.
StringBuffer, on the other hand, is implemented as a dynamically – growable array inside the JVM, which means that any update operation can occur on the existing memory location, with new memory allocated only as needed.
However, there is no opportunity for the JVM to make optimizations around the StringBuffer, since its contents are assumed to be changeable at any instance.
24. Why wait() and notify() are Declared in Object instead of Thread?
Wait, notify, notifyAll methods are only required when you want your threads to access a shared resource and a shared resource could be any java object which is on the heap. So, these methods are defined on the core Object class so that each object has control of allowing threads to wait on its monitor.
Java doesn’t have any special object which is used for sharing a common resource. No such data structure is defined. So, the onus is given on the Object class to be able to become shared resource providing it will helper methods like wait(),notify() and notifyAll().
Java is based on Hoare‘s monitors idea. In Java, all object has a monitor. Threads wait on monitors so, to perform a wait, we need 2 parameters:
– a Thread
– a monitor (any object)
In the Java design, the thread can not be specified, it is always the current thread running the code. However, we can specify the monitor (which is the object we call wait on). This is a good design because if we could make any other thread to wait on the desired monitor, this would lead to an “intrusion”, posing difficulties in designing /programming concurrent programs.
Remember that in Java all operations that are intrusive in another thread’s execution are deprecated (e.g. stop()).
25. Write a Java Program to Create a Deadlock, and Fix It?
In java, a deadlock is a situation where a minimum of two threads are holding the lock on some different resource, and both are waiting for another resource to complete its task. And, none is able to leave the lock on the resource it is holding.
Read More: Writing a deadlock and resolving in java
26. Explain transient and volatile Keywords?
Transient
“The transient keyword in Java is used to indicate that a field should not be serialized.” According to language specification: Variables may be marked transient to indicate that they are not part of the persistent state of an object. For example, you may have fields that are derived from other fields, and should only be done so programmatically, rather than having the state be persisted via serialization.
For example, in class BankPayment.java fields like principal and rate can be serialized while interest can be calculated any time even after de-serialization.
If we recall, each thread in java has its own local memory space as well and it does all read/write operations in its local memory. Once all operations are done, it write back the modified state of variable in the main memory from where all threads access this variable.
Normally, this is the default flow inside JVM. But, the volatile modifier tells the JVM that a thread accessing the variable must always reconcile its own private copy of the variable with the master copy in memory. It means every time thread want to read the state of variable, it must flush its local memory state and update the variable from main memory.
Volatile
volatile is most useful in lock-free algorithms. You mark the variable holding shared data as volatile when you are not using locking to access that variable and you want changes made by one thread to be visible in another, or you want to create a “happens-after” relation to ensure that computation is not re-ordered, again, to ensure changes become visible at the appropriate time.
The volatile should be used to safely publish immutable objects in a multi-threaded Environment. Declaring a field like public volatile ImmutableObject foo secures that all threads always see the currently available instance reference.
Happy Learning !!
Hi Lokesh,
Can you update this page for the below question.
Difference between interfaces and abstract classes?
“A Java abstract class can have the usual flavors of class members like private, abstract.”
There is no use of declaring the abstract class method as private and only you can declare data members as private.
Please check once
Thanks for the information.
There is comma between private and abstract for this reason. Anyway, I updated the text so it does not create this confusion to others. Thanks for your comment.
Superb content. thanks to Lokesh for share valuable information to with us.
This is the best material i have ever read about java in my entire 4 years of career. I feel so fortunate that i got this sort of straight to the point explanation for my revision.
I am glad you find it useful.
Thanks,
beautiful article
very helpful and useful list of core java interview question will be good to prepare for interview. I have an interview next week as java developer and i can predict what they will ask or what type of question will ask from this list. Thanks a lot!
You have some problems with English
I also realize it. And I am working on it. Thanks for the feedback. Much appreciated.
I beg to differ on the point where you say in question
What is the difference between creating String as new() and literal?
“When we create String with new() it’s created in heap and also added into string pool” The thing is when I create a String object using new only one object is created in the Heap and is still not placed in the String Pool. In order to place it in the String Pool, you need to call String.Intern() method on it. this will put the String the String Pool.
Hi Tushar, I must say it’s some how confusing for me too – till date. Let me put my logic:
Here, we both agree that one new object will be created in heap – so let’s leave that discussion. Coming to main point, the argument
"abc"is a string literal and before passing it to String class’s constructor, JVM must somehow interpret it and that is done by placing it inside string pool.Your logic??
This is from Java Doc-
public String intern()
Returns a canonical representation for the string object.
A pool of strings, initially empty, is maintained privately by the class String.
When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.
It follows that for any two strings s and t, s.intern() == t.intern() is true if and only if s.equals(t) is true.
Returns:
a string that has the same contents as this string, but is guaranteed to be from a pool of unique strings.
Here they didn’t mention anything about Heap
Explain the working of HashMap. How duplicate collision is resolved?
while iterating over LinkedList on calculated index, HashMap calls equals() method on key object for each Entry object…
Just to add one more imp thing here i.e. after rehashing the key the new hascode is saved in the Entry object together with key and value. While iterating over linkedlist, Hashmap together with reference equality and object equality it also check for the hashcode match too.
if(e.hash == hash && ((k = e.key) == key || key.equals(k))){...}Please refer: https://howtodoinjava.com/java/collections/hashmap/how-hashmap-works-in-java/
What is the use of the finally block? Is finally block in Java guaranteed to be called? When finally block is NOT called?
if the thread executing the try or catch code is interrupted…
I wrote a test for the above case but unable to reproduce. Could you highlight when this is possible.
Test Code
package core.thread.interrupt; public class InterruptThread implements Runnable { @Override public void run() { try { Thread.sleep(10000); } catch (InterruptedException intException) { intException.printStackTrace(); } finally { System.out.println("finally executed"); } } } package core.thread.interrupt; public class InterruptThreadMain { public static void main(String...args) { Thread thread = new Thread(new InterruptThread()); thread.start(); thread.interrupt(); } } o/p : java.lang.InterruptedException: sleep interrupted finally executed and the stack frame dumpYou may use the method
setDaemon(boolean status)which is used to mark the current thread as daemon thread or user thread and exit the JVM as and when required. This will enable you exit the JVM beforefinally{}is executed.public class InterruptThreadMain { public static void main(String...args) throws InterruptedException { Thread thread = new Thread(new InterruptThread()); thread.setDaemon(true); thread.start(); //Let the thread start - at least Thread.sleep(1000); thread.interrupt(); } } class InterruptThread implements Runnable { @Override public void run() { try { System.out.println("Thread Start"); Thread.sleep(10000); } catch (InterruptedException intException) { intException.printStackTrace(); } finally { System.out.println("finally executed"); } } } Output: Thread StartHi Lokesh,
When I executed the above snippet as you have mentioned here, the output is something else. The finally block is getting executed.
Hi Lokesh
Greetings!!!
What is the internal functionality of below code?
String strObj = new String(null); – Exception at Compile time
StringBuilder d = new StringBuilder(null); – Exception at Runtime
Please clarify.
Hi Lokesh,
Why the Singleton classes are in JVM level not in application level? Please clarify.
This is tricky question. Usually when we talk about singleton, we assume that only one instance of application is running in one JVM. A singleton is always tied to classloader hirarchy for application. In case of single instance of application running on JVM, there can be only one class loaded by classloaders.
What if we deploy two instances of same application in same JVM/server instance? Here the location of singleton class will decide the number of instances created for singleton class. E.g. if class belongs to any shared lib (any j2se class or tomcat lib class) then both applications ( sharing same parent class loader for java and tomcat ) will have only one singleton instance. BUT, if class belongs to application specific lib folder, then both application will end up having their separate instances of same singleton because classloader for both application is separate.
You can find more detailed discussion of StackOverFlow thread1 and thread2.
Thanks Lokesh. Can you please explain Abstraction with some real time example?
Hi Lokesh
import java.io.*; import java.util.*; public class HelloWorld { public static void main(String []args) throws IOException,ClassNotFoundException { ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("Newfile.txt")); out.writeObject(new Child()); ObjectInputStream in = new ObjectInputStream(new FileInputStream("Newfile.txt")); System.out.print(in.readObject()); System.out.println(); } } class Parent { protected transient String hello = "Hello!"; } class Child extends Parent implements Serializable{ int age = 11; public String toString() { return "age="+age+" hello="+hello; } }Actual Result of above snippet : age=11 hello=Hello!
My doubt is, hello string should print null because it is declared as transient. How come the value got serialized?
Please clarify.
I slightly modified your code to make it more clear:
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; import java.io.Serializable; public class HelloWorld { public static void main(String []args) throws IOException,ClassNotFoundException { ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("Newfile.txt")); out.writeObject(new Child()); out.close(); ObjectInputStream in = new ObjectInputStream(new FileInputStream("Newfile.txt")); Child c = (Child)in.readObject(); in.close(); //parent System.out.println(c.hello); //child System.out.println(c.age); System.out.println(c.world); } } class Parent { protected transient String hello = "Hello!"; } class Child extends Parent implements Serializable{ int age = 11; protected transient String world = "World"; public String toString() { return "age="+age+" hello="+hello+" world="+world; } }As per java docs:
So essentially, only
Childclass is part of serialization and de-serialization.Parentclass is created by calling it’s default constructor and normal initialization process, so value is set forhellofield.Effect of serialization is visible in new
transientfield added inChildclass.Thanks Lokesh. So, there will not be any impact by using transient declaration in non-serializable classes. Right?
Yes, in relation to serialization.
Excellent work. Please keep it up.. :)
Hi Lokesh,
The memory leak with string that you mentioned here have been fixed in 1.7 right ?
Yes.
Thank you Lokesh! Important, clear and helpful questions!
Hi,
This is great website which explain most critical topics in detail, I love the way you explained HashMap and HashSet concept, waiting for your book in market for Java details interview preparation for experience candidate, because in so many websites they just highlighted the concept but you explained them really well.
wish you all the best.
Regards,
Raj Sharma
Hi Lokesh,
Excellent website. I always come back here to brush up my knowledge.
One doubt from a question on this page.
For the question “Why main() in java is declared as public static void?”, you say that irrespective of the access modifiers, java.exe or javac.exe can invoke the main method. But, when I try to run a test program which does not have ‘public’ access modifier for main(), it gives me the below error. Has the behavior changed lately?
Error: Main method not found in class TestJavaMain, please define the main method as:
public static void main(String[] args)
Bastin, java.exe file is written in native code and uses C++ like instructions to verify the syntax and execute
main()method. Infact, error “does not have ‘public’ access modifier” is itself thrown from inside java.exe file sourcecode, when syntax does not match.But, I get this error when running the program from command line using java.exe. If it doesn’t have such a restriction, then it should work fine.
Hi Lokesh,
Well explained theoritically.
If you provide programs for each concept will be more easier to understand the internals of java.
Please do it.
Why can’t you provide with examples
thanks this helped lot.
Hi Lokesh,
One of the interview, they asked me how to do sort in ascending order on String of characters after converting them into Ascii values and I answered in below mentioned way but he does not satisfied with my answer.Could you please tell me other way to do this.
I have coded like this.
public static String convert_String_To_Ascii(String numStr){
char ch[] = numStr.toCharArray();
int first=0;
int last=0;
StringBuffer asn=new StringBuffer();
for(int i=0;i<ch.length;i++)
{
first=(int) ch[i];
for(int j=i;jlast)
{
char temp=(char)first;
first=last;
ch[i]=(char)last;
ch[j]=temp;
}
}
}
return new String(ch);
}
What about below?
String s = “some-string-here”;
byte[] bytes = s.getBytes(“US-ASCII”);
Arrays.sort(bytes);
It’s sort and easy to read. Your’s is also correct.
Veri Nice Post.
In this page you mentioned:
When we create string with new () it’s created in heap and not added into string pool
and in https://howtodoinjava.com/interview-questions/string-questions/ you have mentioned:
==================================
2) Using new keyword
String str = new String(“abc”);
This version end up creating two objects in memory. One object in string pool having char sequence “abc” and second in heap memory referred by variable str and having same char sequence as “abc”.
==================================
Isn’t it contradictory to each other?
Hey Sumeet, Good catch. It was a typo (sometimes happen when you type so much text). Thanks for pointing out and I have corrected that.
To put more focus on topic, When you use new keyword and pass a String parameter then that parameter is actually a String literal and string literal in string pool gets created even before your String() constructor is called. So, on runtime when constructor is called, you get your second object in heap area.
“Compile-time constant expressions of type String are always “interned” so as to share unique instances, using the method String.intern”
Source: https://docs.oracle.com/javase/specs/jls/se7/html/jls-15.html#jls-15.28
Hi, thank you for your post, very nice!
At the question: “Why there are two Date classes; one in java.util package and another in java.sql?”
When you say : “So, what changed in java.sql.Date: […] the getters and setter for hours, minutes and seconds are deprecated” I feel it’s a bit misleading, because in the original java.util.Date class, those methods are already deprecated, but it’s just not for the same reasons.
https://docs.oracle.com/javase/7/docs/api/index.html?java/util/Date.html
You caught me on wrong foot.- :-) OK, it can be misleading. So let’s me clarify again.
Methods in java.util.Date were gone deprecated because of Calendar class was considered recommended approach. So, util’s Date class’s multiple methods were marked as deprecated.
e.g. setMinutes(int minutes) :: Deprecated. As of JDK version 1.1, replaced by Calendar.set(Calendar.MINUTE, int minutes).
But, in java.sql.Date class it was deprecated because they are (though not enforced) conceptually discouraged.
e.g. setMinutes(int i) :: Deprecated. This method is deprecated and should not be used because SQL Date values do not have a time component.
I like this answer ;) Thx!
Great list dude. Keep it up the writing.
public class FinallyReturnVariableAlter
{
public static void main(String[] args)
{
System.out.println(test());
}
public static int test()
{
int i=0;
try
{
return i;
}
finally
{
i+=100;
}
}
}
why the return value is 0 instead of 100?
Manohar, This is really good question and most fail to answer it correctly. Let me put my reasoning.
Every function call in java leads to creation of extra memory space created where return value is stored for reference after function execution completes and execution return to caller function back.
At that time, that special memory address where return value is stored, if referenced back as return value of function.
Here, trick is, the memory slot store the value of returned value, not its reference. So, once any return statement is encountered its value is copied in memory slot. That’s why if you change the value of “i” in finally, return value does not change because its already copied to memory slot.
We any other return statement is encountered (e.g. in finally block), its value will be overwritten again. So, it you want to return 100, use return statement in finally also.;
Hi Lokesh,
does the finally block executes if we have a return statement in try block if it works fine without throwing an exception?
Yes.
whatever you return in try block will be override by finally block if you are returning anything in finally block.
Hi Lokesh
certainly I will go thr’ questions but tell me java code to connect to
hsqldb .I am getting user lacks privilege or object not found: EMPLOYEEDETAILS exception
pl help me
Are you using hibernate.. match your properties..
https://docs.jboss.org/hibernate/orm/4.1/devguide/en-US/html_single/#d5e54