SQL is the standard language for retrieving, updating, inserting and deleting data from a database. It ranks third in the list of the most used programming, scripting, and markup languages survey made by StackOverflow in 2022. Therefore SQL is essential and should not be missing from our preparation for technical interviews. We will start with some of the most fundamental SQL interview questions about databases and increase the difficulty level along the way.
Frequently Asked SQL Interview Questions
1. What is a Database?
A database refers to a structured data collection that can be stored, managed, and retrieved from a remote or local computer system. Databases can become pretty complex and are built with a fixed design and modeling approach.
Let’s take some database examples: An online phone book uses a database to store data of people, phone numbers, and other user details. Your internet service provider uses a database to manage billing, client-related issues, handle fault data, and so on.
2. What is a DataBase Management System (DBMS)?
In terms of programming, a database management system is a software for creating and managing databases. DBMS allows us to create, protect, read, update and delete data in a database. It works as an interface between databases and us or application programs.
A few popular examples are MySQL, PostgreSQL, Microsoft Access, SQL Server, FileMaker, and Oracle.
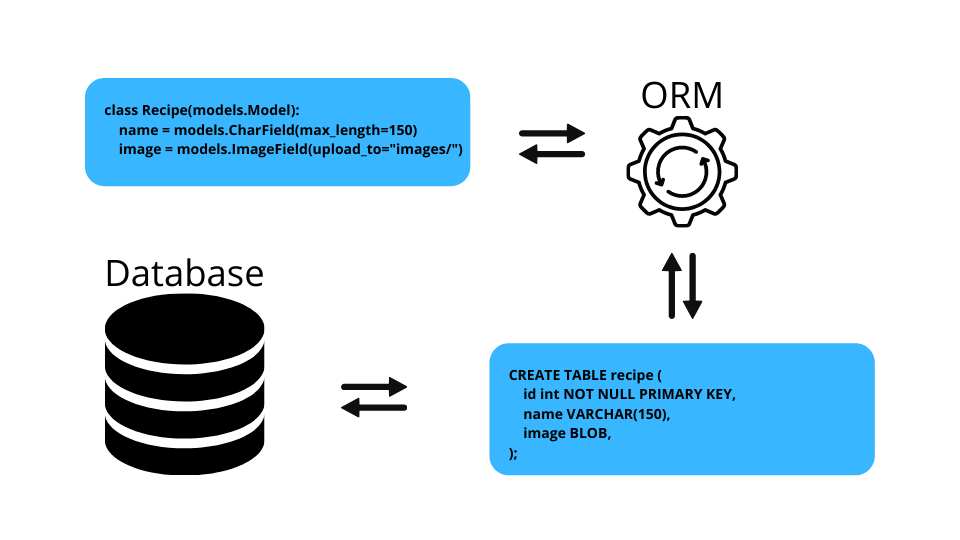
3. What is Object-Relational Mapping?
Object-Relational Mapping (ORM) is a tool that lets you query and manipulates data from a database using an object-oriented programming language such as Java. When we talk about ORMs, we usually refer to a library that implements the Object-Relational Mapping technique, hence the phrase “an ORM”.
An ORM library is written in our language of choice and encapsulates the code needed to manipulate the data. Therefore we don’t need to directly use the SQL; we can interact instantly with an object from our code, instead of a database table. The ORM tool translates the interaction into an SQL query and executes it in the database.
ORMs provide additional features too, such as security, protection from SQL injection and transaction management. A few popular examples are Hibernate, Eclipse Link, and Prisma.
4. Difference between SQL and PL/SQL?
Even though SQL and PL/SQL (Procedural Language extension to SQL) are pretty similar, there are several differences in how they work, they differ in performance, error handling capabilities, and interaction with the databases. For example:
- SQL is a query language with few keywords. And PL/SQL is a programming language using SQL for a database and has variables, data types, loops etc. PL/SQL also offers error and exception handling features that do not exist in SQL.
- SQL is declarative; PL/SQL is procedural.
- While SQL executes one query at a time, PL/SQL can run an entire block or multiple operations in a single execution.
- PL/SQL does not interact directly with the database server, while SQL does.
- Generally, SQL is used for DDL and DML statements, whereas PL/SQL is used to write program blocks, functions, procedures, triggers and packages.
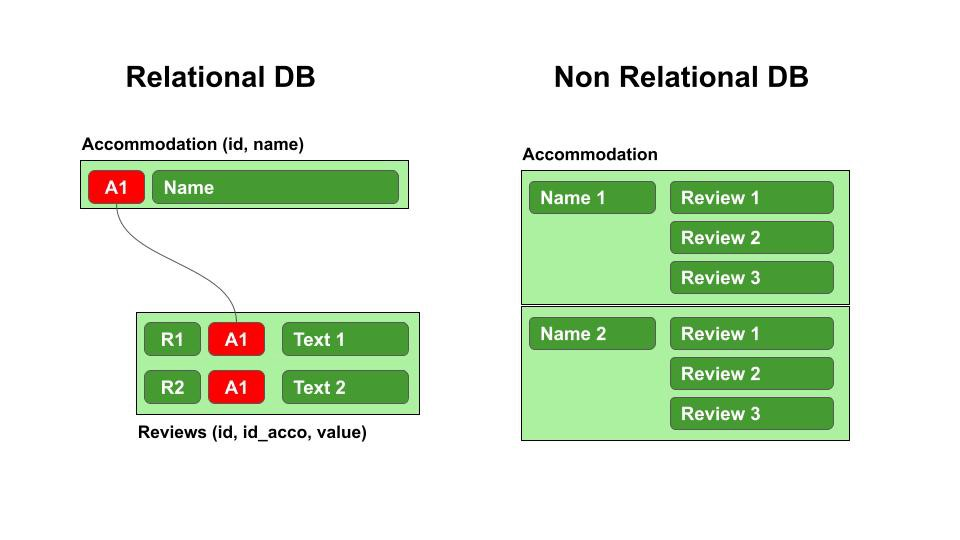
5. Difference between Relational and Non-relational Databases
A relational database is organized in tables. Usually, the data within these tables have relationships with one another or dependencies.
A non-relational database is document-oriented, meaning all information gets stored in more of a laundry list order. As a result, we will have all our data listed within a single construct or document.
6. Difference between DDL, DQL, DML, DCL, and TCL Statements?
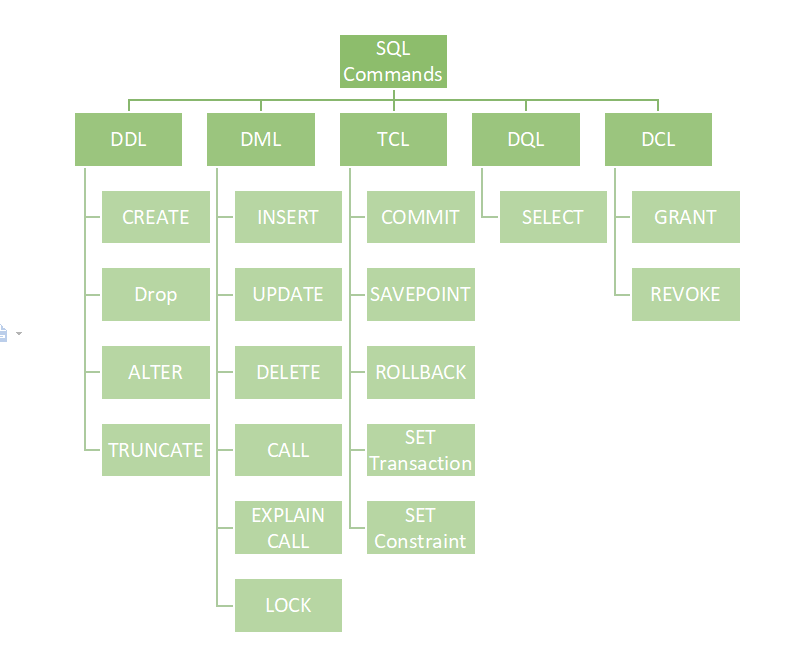
There are five main categories for the SQL commands:
- DDL – Data Definition Language – defines and alters the database schema;
- DQL – Data Query Language – performs the query operations on the data within schema objects;
- DML – Data Manipulation Language – manipulate the data present in the database;
- DCL – Data Control Language – manages the database system’s rights, permissions, and other controls.
- TCL – Transaction Control Language – deals with the transaction within the database.
7. What is a Query?
A query, in SQL, is a command used to request data or update information from a database table or combination of tables. Users can write and execute queries to retrieve, delete or update information in a database. Usually, a query response returns data from different tables within the database, but this does not apply every time (for example, a delete query will not return anything).
For example, let’s say that we have an employee table. We want to get all employees from the table that are born before 1990. For this case, we will use a SELECT statement because all we want is to retrieve data from a table.
SELECT * FROM employees WHERE year_born < 19908. What is a Primary Key?
A primary key refers to a column or a set of columns containing values uniquely identifying each row in a table. A database table uses a primary key to uniquely insert, update, restore or delete data from a database table.
Generally, a primary key is a sequentially generated long number and its whole purpose is to uniquely identify a particular row in the table. It does not have any business value in itself.
We can define a primary key in the employee table as follows. In this example, we are marking ID column as the primary key for the table Employee.
CREATE TABLE Employee (
id INT PRIMARY KEY,
name VARCHAR(45),
email VARCHAR(45),
manager_id INT,
country VARCHAR(45),
);9. What is a Unique Key?
A unique key refers to a value of one column (or combination of more than one column) that uniquely identifies a record in the database table. not like primary key, a unique key has a business meaning and puts a certain constraint on the table as defined by the business.
For example, for an EMPLOYEE table, am EMAIL can be a unique key because each employee is guaranteed to have a unique key throughout the organization.
We can create a unique key constraint in a new table as follows:
CREATE TABLE Employee (
id INT PRIMARY KEY,
name VARCHAR(45),
email VARCHAR(45) UNIQUE,
manager_id INT,
country VARCHAR(45),
);If the table and the column already exist, we can add the constraint in the following way:
ALTER TABLE Employee
ADD UNIQUE (email);10. Difference between Primary key and Unique Key?
- A primary key column cannot contain NULL values, but the unique key can accept one NULL value.
- Every database table can have just one primary key, but multiple unique keys.
- The primary key generates a clustered index, but the unique key generates a non-clustered index.
11. What is a Foreign Key?
A FOREIGN KEY is a column (or collection of columns) in one table that links the PRIMARY KEY in another table.
We can add a foreign key to our employee table on the manager_id column because a manager is also an employee. We will link the manager_id column with the id from the same table. If we are creating a new table we can implement the foreign key in the following way:
CREATE TABLE Employee (
id INT PRIMARY KEY,
name VARCHAR(45),
email VARCHAR(45) UNIQUE,
manager_id INT,
country VARCHAR(45),
FOREIGN KEY (manager_id) REFERENCES Employee(id)
);And if we already have the table and the column created we can add the constraint altering the table in the following way:
ALTER TABLE employee
ADD FOREIGN KEY (manager_id) REFERENCES Employee(id);12. What are Database Normalization and Denormalization?
Database normalization is an essential process that consists of structuring a relational database by a sequence of so-called normal forms to ease redundancy and improve data integrity. To say that the data from our database is normalized, it should meet the following two requirements:
- No redundancy of data. The data is held in just one place and is not duplicated in other tables.
- Data dependencies are logical and separated. All related data are stored together.
There are a few rules for database normalization. Each rule is called a “normal form.” If the first rule is observed, the database is said to be in “first normal form.” If the first three rules are observed, the database is considered to be in “third normal form.” The third normal form is considered the highest level necessary for most applications.
Here is a list of Normal Forms in SQL:
- 1NF (First Normal Form): Each table cell should contain a single value. Each record needs to be unique.
- 2NF (Second Normal Form): In addition to 1NF, all non-key attributes are fully dependent on the primary key. It helps to eliminate redundant data.
- 3NF (Third Normal Form): In addition to 2NF, there are no transitive functional dependencies. In 3NF, values in a record that are not part of that record’s key do not belong in the table.
- BCNF (Boyce-Codd Normal Form): is just a more strong form of 3NF. Sometimes also referred to as 3.5NF.
- 4NF (Fourth Normal Form): In addition to BCNF, the database has no multi-valued dependency.
- 5NF (Fifth Normal Form) In addition to 4NF, the database does not contain any join dependency, joining should be lossless.
On the opposite, denormalization is the exact opposite process of normalization. Here, we intentionally add redundancy to the data to improve the specific application’s performance and protect data integrity.
Although denormalization is not recommended, it may be necessary in some very specific cases.
13. What is a Join?
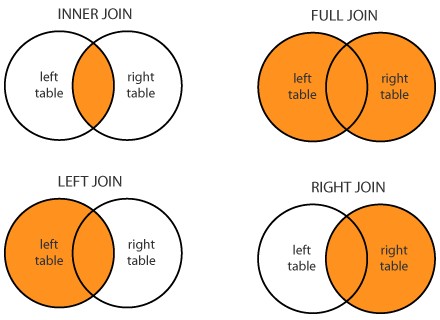
The SQL Joins refer to combining rows from two or more tables based on a related column between them. Various types of Joins can be used to retrieve related data, and it depends on the relationship between tables.
There are four types of Joins:
- Inner Join: returns records that have matching values in both tables
- Left Join; returns all records from the left table, and the matched records from the right table
- Right Join: returns all records from the right table, and the matched records from the left table
- Full Join: returns all records when there is a match in either left or right table
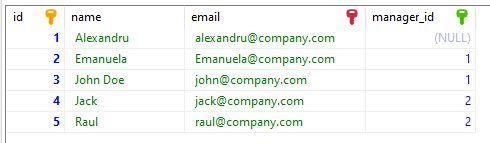
14. Explain Self-Join with an Example
The self-join means joining one table with itself. We can use the Self-Join on a table only if it has a column (we will call it A) that serves as the primary key and another column (that we will call Y) that stores values that can correspond with the primary key column.
For example: Let’s take our Employee table. We have a manager for each employee, but it’s hard to read because we cannot see the manager’s name of an employee directly.
We can write a Self-Join to create a view where we have the employee and manager names on the same row.
SELECT employee.id, employee.name, employee.email, employee.manager_id, manager.name AS "Manager name"
FROM Employee employee
LEFT JOIN Employee manager ON employee.manager_id= manager.idAfter executing the query, we will obtain the following result:
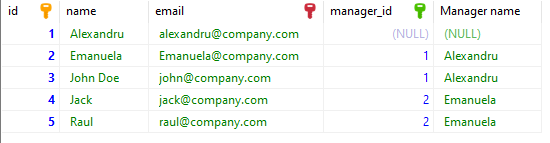
Note that we have used LEFT JOIN because we want to get all the employees even if the manager_id is NULL. If we use a normal join, the first entry from the result will be excluded because the employee Alexandru does not have a manager.
15. Difference between INNER JOIN and OUTER JOINs
The major difference between inner and outer joins is that inner joins result in the intersection of two tables, whereas outer joins result in the union of two tables. For example, if a from table A has no matching entry in table B, A will be included in the left outer join but in the inner join not.
An inner join searches tables for matching or overlapping data. Upon finding overlapping data, the inner join combines and returns the information into one new table.
An outer join returns a set of records (or rows) that include what an inner join would return but also includes other rows for which no corresponding match is found in the other table.
16. Difference between UNION and UNION ALL
The UNION and UNION ALL are two operators that merge the set of results of two or more SELECT queries. These operators allow to execute multiple SELECT queries, retrieve the desired results, and then combine them into a final output.
The difference between these two is that the UNION operator will filter out the duplicate rows and show only the unique records while UNION ALL allows duplicate records.
SELECT ID, NAME, EMAIL, DOB FROM EMPLOYEE e WHERE e.ID IN (1,2,3,4,5);
UNION
SELECT ID, NAME, EMAIL, DOB FROM EMPLOYEE e WHERE e.ID IN (3,4,5);In the above example, the final result will contain 5 records if we use UNION. When using UNION ALL, we will get 8 records because 3,4,5 are duplicate records.
17. What is an Index?
Indexes are database objects that help improve the performance of the SQL SELECT query on a table. Typically, an index contains keys built from one or more columns in the table or view. These built keys are stored in a structure (B-tree) in the database server’s physical memory. It enables the database server to find the row or rows associated with a given key quickly and efficiently.
When we execute a query and use the WHERE keyword on a column that does not have an index, then the SQL Server has to do a full-table scan and check every row to find matches. This is a bad practice because it can be unpredictable in terms of execution time. Therefore this process may have a slow execution for a large amount of data.
When indexes have been built on a column, these indexes are used to find all the matching rows for a WHERE clause, and then scanning happens through only those subsets of the data to discover the matches in the table.
We can add an index in the following way:
CREATE INDEX INDEX_EMAIL ON EMPLOYEE (EMAIL);18. What is a Trigger? How many Types of Triggers?
Triggers are stored procedures that are automatically fired by the DBMS when a DML or DDL command related to them is executed. There are three types of triggers:
- Data Manipulation Language (DML) triggers are executed when a DML (INSERT, UPDATE, DELETE) is executed;
- Data Definition Language (DDL) triggers are fired automatically when a DDL Statement (ALTER, DROP, CREATE) is executed;
- Logon triggers are fired in response to establishing a new user session.
For example, if we want to keep track of the changes in the EMPLOYEE table then we can create a separate table EMPLOYEES_AUDIT and push a new record in this table for each change in the EMPLOYEE table.
CREATE TABLE EMPLOYEES_AUDIT (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(45) NOT NULL,
email VARCHAR(45) NOT NULL,
changedat DATETIME DEFAULT NULL,
action VARCHAR(45) DEFAULT NULL
);We will keep the initial value for the name and email of the employee in the table, and we will create a new entry every time an employee is changed.
CREATE TRIGGER BEFORE_EMPLOUEE_UPDATE
BEFORE UPDATE ON EMPLOYEE
FOR EACH ROW
INSERT INTO EMPLOYEES_AUDIT
SET action = 'update',
name = OLD.name,
email = OLD.email,
changedat = NOW();This is the trigger that will be fired before each update. Let’s update a user to check if our trigger works properly. We run the following query to change the name of the user with an id equal to 1:
UPDATE employee SET NAME = "Luke" WHERE id = 1And we will check the employees_audit table where the trigger created a new row for the change.

19. What are Cursors? How Many Types of Cursors?
A database cursor can be thought of as a pointer to a specific row within a query result. The pointer can be moved from one row to the next. Depending on the type of cursor, you may even be able to move it to the previous row.
We separate Cursors into two types: Implicit Cursors and Explicit Cursors.
- The system creates implicit cursors (or default cursors). These are automatically created when SQL SELECT statements are executed. Explicit cursors are made by users whenever the user needs them.
- Implicit cursors are capable of fetching a single row at a time, while explicit cursors can fetch multiple rows.
- Implicit cursors are closed automatically after execution whereas the user must close the explicit cursors after execution.
- Implicit cursors are supposed to be used only with SQL statements that return a single row. These are robotically connected with each INSERT, UPDATE and DELETE statement and can raise NO_DATA_FOUND or TOO_MANY_ROWS exceptions when the SQL statement returns more than one row. Explicit cursors do not raise such exceptions.
20. What is a View in a Database?
A view is a virtual table in the database that contains data from one or more tables, but it takes less memory because it is not physically stored in the database. The names of the views are always unique.
Database views are saved in the database as named queries and can be used to save frequently used complex queries. Views are an excellent tool to restrict access to the data in such a way that a user can see and (sometimes) modify exactly what they need and no more.
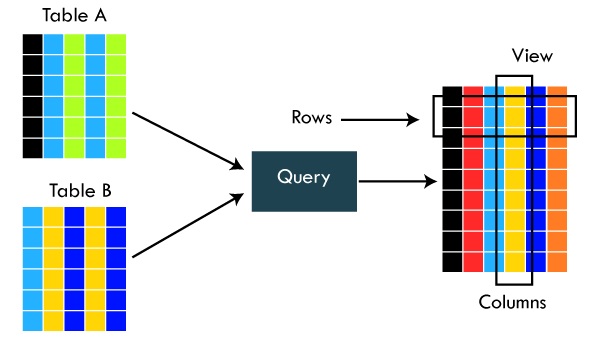
In the following VIEW, we are exposing only 3 columns to the query users. Other columns are hidden for various purposes.
CREATE VIEW EMPLOYEE_VIEW AS
SELECT ID, NAME, DOB
FROM EMPLOYEE;There are two types of database views: dynamic views and static views. Dynamic views are automatically updated when related objects or extended objects are created or changed. Static views must be manually updated when related objects or extended objects are created or changed.
21. Differences between Views and Tables?
Views and tables may seem pretty similar, but they have some differences. Both of them consist of rows and columns, but they differ in terms of persistence.
A table stores and retrieves data from persistent storage whenever the user wants. On the other side, the view is only a virtual table based on the result of some SQL queries, meaning that this will disappear after the session ends.
22. Difference between TRUNCATE and DROP Statements?
The DROP command removes the entire table, including the definition, indexes, constraints, and triggers for that table.
The TRUNCATE command deletes only all the rows from the table. The schema is not affected by this command.
23. Difference between DELETE and TRUNCATE?
- DELETE command removes some or all of the records from the table, while the TRUNCATE will delete all the rows from the table.
- We can filter the rows that you want to DELETE by using the WHERE clause, while TRUNCATE cannot.
- When a DELETE query is executed, all delete triggers are fired, and TRUNCATE does not fire any trigger.
24. Difference between ORDER BY and GROUP BY clauses?
Using ORDER BY, we can sort the result set in ascending or descending order.
GROUP BY clause is used to group the rows with the same value.
25. Difference between WHERE and HAVING?
With the WHERE clause, we can filter the result set according to given conditions. It can be used with SELECT, UPDATE, and DELETE statements.
SELECT ID, NAME FROM EMPLOYEE
WHERE ID >= 100HAVING clause is used as a filter with the GROUP BY statement. Those grouped rows that will satisfy the given condition in HAVING will appear in the final result. HAVING Clause can only be used with SELECT statement.
SELECT ID, NAME FROM EMPLOYEE
GROUP BY NAME
HAVING AGE > 18If we use the HAVING clause without GROUP BY, it can also refer to any column, but it won’t be used while performing the query, unlike the WHERE clause.
26. What are constraints? Different types of Constraints?
Constraints are the rules imposed on the database contents and processes to ensure data integrity. There are different types of constraints:
- Domain constraint specifies the attribute’s domain or set of values (if we define a number column, we cannot insert ‘A’ in the column).
- Tuple Uniqueness constraint specifies that all the rows must be necessarily unique in any table.
Key constraint defines that every primary key should be unique and not null. - Entity Integrity constraint specifies that no attribute that composes the primary key must contain a null value in any relation.
- Referential Integrity constraint establishes that all the foreign key values must either be in the relation to the primary key or be null.
27. What is a Stored Procedure?
A stored procedure is a prepared SQL code. We can save the procedure in the database, so we can use it every time we need it without rewriting it. If we are using a query multiple times we can save it and store it as a procedure.
For example, let’s we want to store the inner join query for getting the manager for each employee:
CREATE PROCEDURE join_employees
AS
SELECT employee.id, employee.name, employee.manager_id, manager.name as ManagerName
FROM Employees employee
JOIN Employees manager ON employee.manager_id= manager.id
GO;And we can execute the procedure as follows:
EXEC join_employees;28. What is a Schema in SQL?
Our database holds a lot of different objects, such as tables, relations, triggers, indexes, their relationships and so on. So, we usually make a database schema to create a clear vision of our database and organize all tables and relations between them.
So, we can view schema as the logical relationship between all the different tables in the database. Overall, we can consider a schema as a blueprint for the database. Usually, the schema is the first thing created when creating a database.
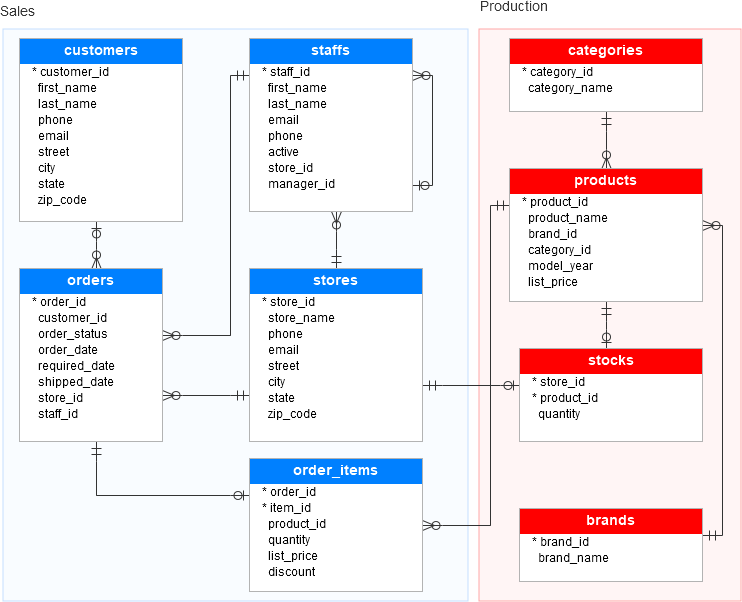
In the above image, we can see an example of a schema for a database.
29. What are UNION, MINUS and INTERACT commands?
- The UNION operator merges the results of two tables and eliminates duplicate rows from the tables.
- The MINUS returns the rows from the first query but not from the second query.
- The INTERSECT returns the rows that are returned by both of the queries.
30. What does the COALESCE function do?
The COALESCE function takes several parameters, evaluates them in sequence, and returns the first non-null argument. For example, given the following query:
SELECT COALESCE(NULL, ‘Alexandru’, ‘Java’, NULL) result;The result will be ‘Alexandru’.
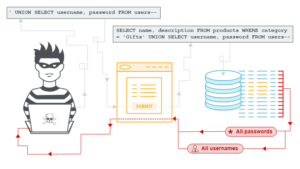
31. What is SQL Injection?
SQL injection is a hacking technique that is widely used by hackers to steal data from databases. Let’s say we go to a website and we want to log in. We insert our username and password, and then add some malicious code over there such that: “username; drop table users;“.
So, if the site does not have any prevention to SQL injection, it executes a query in the database to find if the username exists, this will result in deleting the complete USERS table.
SELECT * FROM USERS WHERE USERNAME=username; drop table users;That will be a terrible thing. Do not forget, that if our database contains any vital information, it is always better to keep it secure from SQL injection attacks.
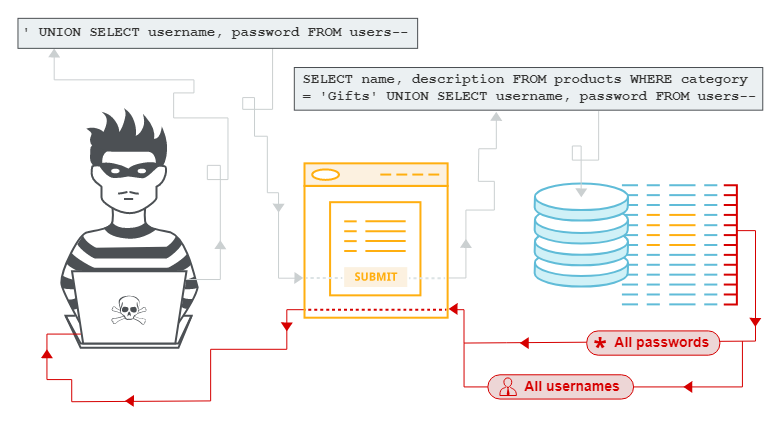
Use prepared statements that eliminate the possibilities of such SQL injection vulnerabilities.
32. How to Insert Multiple Rows in a Table?
Let’s say we want to insert multiple rows in our employee table. To do this, we pass multiple tuples consisting of values for each row as given in the following SQL statement:
INSERT INTO employee (id, NAME, email, manager_id, country)
VALUES
(6, 'Anna','ana@gmail.com',2,'Romania'),
(7, 'Maria', 'maria@company.com',1, 'UK'),
(8, 'Laura', 'laura@as.com',3,'Norway');33. How to Add a New Column to a Table?
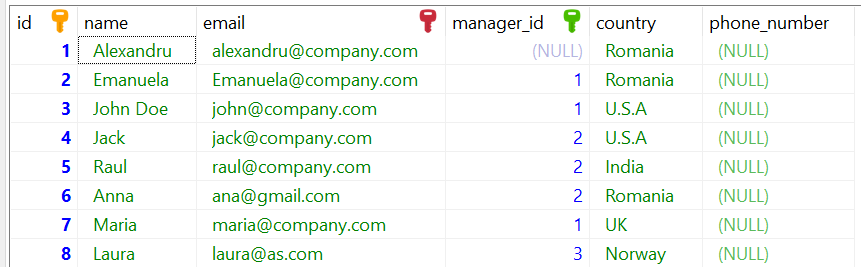
We can add a new column in SQL with the help of ALTER command. We will use the following SQL statement if we want to add a new column in our employee table with the employee’s phone number.
ALTER TABLE employee ADD COLUMN phone_number VARCHAR(13);After the execution our table will look like this:
34. What are the NVL and the NVL2 Functions? How do They Differ?
NVL(exp1, exp2) and NVL2(exp1, exp2, exp3) are functions that help us with null-checking problems. But there are some differences.
- As you can see the NVL function accepts 2 parameters, while the NVL2 function accepts 3 parameters.
- The NVL can be traduced in the following way: if exp1 is not null, return exp1 otherwise, return exp2.
- On the other side, the NVL2 function check if exp1 is null, if it is indeed null, it will return exp2, otherwise, it will return exp3. Conceptually, it is like the ternary operator for SQL queries.
select nvl(null, 'arg2') from dual; //Returns arg2
select nvl('arg1', 'arg2') from dual; //Returns arg1
select nvl2(null, 'arg2', 'arg3') from dual; //Returns arg3
select nvl2('arg1', 'arg2', 'arg3') from dual; //Returns arg235. How to Use LIKE operator in SQL?
The LIKE operator is used in WHERE clauses to check if a value fits a given string pattern. Here is an example of a LIKE operator:
SELECT * FROM employe WHERE name like "Alexandru"; With this command, we can pull all the records where the first name is like “Alexandru“. The result will look like this:

36. How to Remove Duplicate Rows from a Query?
SELECT DISTINCT fetches all the distinct data from a query. For example, let’s say that we want all the distinct countries where our employees are located. For this task, we will use the following SQL query:
SELECT DISTINCT country FROM employeeAnd the result of the query will be:

37. What is Data Integrity?
Data integrity is referred to the data’s precision and consistency (validity) over its lifecycle. It ensures an organization’s data’s accuracy, completeness, consistency, and validity.
Every time data is copied or moved, it should remain unchanged and unaltered between updates. Error checking methods and validation procedures are typically responsible for ensuring the integrity of data transmitted or reproduced without the purpose of alteration.
38. What are ACID Properties?
The ACID properties describe the set of properties of database transactions that guarantee data integrity despite errors, system failures, power failures, or other issues.
- Atomicity: means that the transaction takes place at once or doesn’t happen at all;
- Consistency: means that integrity constraints must be maintained so that the database is consistent before and after the transaction;
- Isolation: ensures that each transaction is independent and occurs without interference;
- Durability: ensures that after a transaction has completed execution, the updates and modifications to the database are stored in and written to disk, and they persist even if a system failure occurs.
39. Difference between CHAR and VARCHAR2
The CHAR data type stores character values. It is a fixed-length data type and has a maximum length of 2000 bytes of characters. Because char is a fixed size, it will often lead to memory wastage. (If you have a char(10), and want to store “Alex” in it will result in “Alex”). It has 6 additional blank characters.
The VARCHAR2 also stores character values, but it has variable length and can have a maximum length of 4000 bytes of characters. It helps in saving memory bytes.
40. Explain COMMIT and ROLLBACK Commands
Commit and rollback are the transaction control commands in SQL. In SQL, all the commands executed consecutively are treated as a single unit of work and termed as a transaction.
- Commit in SQL is used to permanently save the changes done in the transaction in tables/databases. Until we perform COMMIT after making changes to data, data will not be saved unless AUTO COMMIT is ON.
- ROLLBACK in SQL undoes the transactional changes that have not been already saved in the database. The data changes are undone until the last COMMIT command. With the help of ROLLBACK, we can avoid unwanted database changes.
41. Are NULL values Same as Zero or a Blank space?
No, they are three different things with three different data types.
- The NULL represents an unavailable, unassigned, or unknown value,
- The zero is a number value.
- The blank space is a single whitespace character. It is a valid value for CHAR/VARCHAR2 datatypes.
42. What are User-defined Functions?
SQL Server user-defined functions are routines that accept parameters, perform an action and return the result of that action as a value, like all the functions in the programming languages. The result can either be a scalar value or result set.
CREATE FUNCTION GetEmployee(@id INT)
RETURNS VARCHAR(50)
AS
BEGIN
RETURN (SELECT Name FROM Employee WHERE id=@id)
END To execute this function use the following command.
PRINT dbo.GetEmployee(1) //Print name of the employee43. Explain Aggregate Functions?
Aggregate functions are SQL functions that take several rows, perform a calculation, and then return the result after reducing it according it the used function.
Some examples of aggregate functions will be COUNT (used to get the number of values returned by a SQL statement), MAX/MIN (the largest, respective the smallest value from a SQL result set), etc.
Let us understand with an example. Our table looks like this:
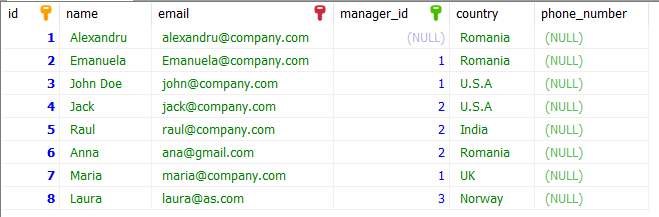
Let’s test the COUNT function. We want to write a query to see how many employees have Alexandru as their manager.
SELECT COUNT(NAME) FROM employee WHERE manager_id = 1 #result will be 344. Different Types of Relationships?
There are 3 main types of relationships in a database: one-to-one, one-to-many and many-to-many. Let us understand these relationships with following image.

- One-to-one -> occurs when each row in the user table has only one corresponding row in the password table.
- One-to-many -> one-to-many relationship occurs when one record in the class table is related to one or more records in the student table. However, one record in the student table cannot be related to more than one record in the class table.
- Many-to-many -> multiple records in one table (books table) are related to various records in another table (authors table).
45. What is a Live Lock?
Locks are essential parts of databases. If our application scales, it will receive many requests, which may result in a situation where two or more sessions will try to edit the same row. That may result in some data integrity problems.
A Live lock happens when a request for an exclusive lock is denied continuously because a sequence of other shared locks keeps interfering with each other and changing the status. Therefore no one will complete the transaction.
An excellent example of a live lock would be two cars meeting on a one-way street, both of them will turn left or right at the same time to let the other car pass, but as these actions are done at the same time, neither of them will advance.
46. SQL Query to Find Names Starting with a Substring?
For this query, we can use the LIKE operator for comparing strings and the % symbol which acts as a wildcard to match characters.
Let’s say we want to select all the employees that have a name starting with ‘a”. We will write the following query:
select name from employee where name like 'a%'The result of our query will be:

47. SQL Query to Find and Delete Duplicate Records from a Table?
For this problem, we can use a CTE. CTE stands for Common Table Expression. It is a temporary result set that we can reference within a SELECT, UPDATE, INSERT, or DELETE statement.
Let us consider following table EMPLOYEE_2 which has few duplicate records.
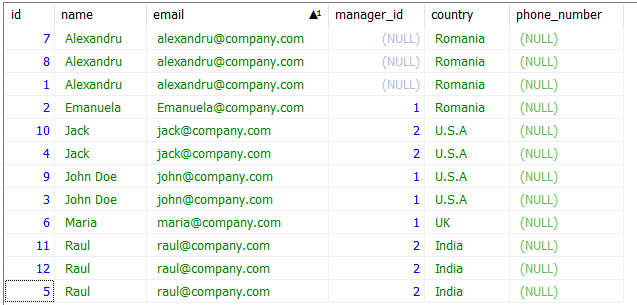
To delete duplicate records, we will use a DELETE command combined with a self-join to remove all the duplicates. We use the id column to uniquely identify a row among duplicates. We are deciding the duplicated entries based on the email column.
Our query will look like this:
DELETE employee1 FROM employee_2 employee1
INNER JOIN employee_2 employee2
WHERE employee1.id < employee2.id AND employee1.email = employee2.email;After we run the query our table will look like this:
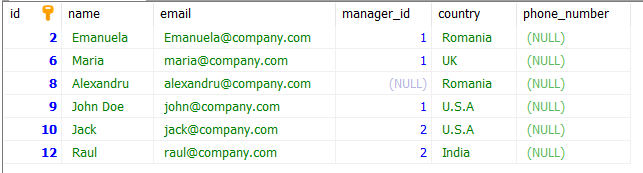
Conclusion
SQL is a high-demand skill today and a language that should not be missing from the arsenal of programmers. This guide listed out a few of the most asked SQL interview questions and gave their answers to begin with, to keep the post in limit. You are advised to read a more detailed answer if a question is not very clear to you.
You can also go over JDBC performance tips for additional concepts to learn.
Happy Learning !!