
ChatGPT fine-tuning is a process of training a pre-trained language model, such as ‘gpt-3.5-turbo‘ or ‘gpt-4‘ on a specific dataset. Fine-tuning helps in improving the chatGPT performance and adapting it to a particular task or domain.
In this tutorial, we will learn to create a fine-tuned chatGPT model that specializes in replying the general support questions. We will learn and perform the following steps to build a fine-tuned model at the end of this tutorial:
- Preparing the training data
- Uploading the training data to OpenAI servers
- Creating a fine-tuned model with the training data
- Interacting with the fine-tuned model using chatGPT Completion API
- Further improving the data quality of the fine-tuned model
Apart from the above basic steps, we will also learn to inquire about all the fine-tuned models as well as delete the models that are no longer in use.
Prerequisites
To get the most out of this tutorial, you will require the following:
- Python 3.7 or later installed on your computer
- An OpenAI API key, which can be obtained by signing up for an OpenAI account
- A code editor, such as PyCharm (recommended), to write and run Python code
- Training data in a JSONL file
You can learn to obtain the OpenAI API Key and set up the development workspace in the guide: Getting Started with ChatGPT API and Python.
Step 1: Preparing the Training Data
The fine-tuning process typically begins with a dataset that is carefully curated and labeled, and it involves raining the model on this dataset using techniques such as transfer learning. The model’s parameters are adjusted during fine-tuning to make it more accurate and contextually appropriate to generate responses in the target domain. The model can acquire domain-specific knowledge, language patterns, and nuances by fine-tuning, enabling it to generate more relevant and coherent responses for specific applications or use cases.
During the fine-tuning process, it is necessary to provide the training data as a JSON file. You should create a diverse set of target conversations that expect the model to perform after the fine-tuning process is completed.
This training data can come from a variety of sources, such as books, articles, specialized datasets, or we can prepare it manually.
1.1. Training Data Format
The training data should be in conversational chat format and it is required to fine-tune gpt-3.5-turbo. For example, for our usecase, we have created the input_data.jsonl which has the required pattern. Note that each message appears in a new line.
{"messages": [{"role": "user", "content": "Reset my password for account ID 12345"}, {"role": "assistant", "content": "Your password has been reset. Please check your email for the new login details."}]}
{"messages": [{"role": "user", "content": "How do I update my billing information?"}, {"role": "assistant", "content": "To update your billing information, log in to your account, go to the 'Billing' section, and follow the prompts."}]}
...To start the fine-tuning a model, we must provide at least 10 examples. For optimal results surpassing base models, we should aim to provide a few hundred or more high-quality examples, preferably vetted by human experts. The right number of examples varies on the exact use case and the level of required accuracy.
1.2. Verifying the Training Data
The recommended process to check the validity of training data requires loading the JSONL file (verifies a valid JSON file) and checking for any missing data elements (verifies the JSON file structure).
You can check for the latest recommendations for validating the training data on the OpenAI website.
import json
from collections import defaultdict
data_path = "input_data.jsonl"
# Load the dataset
with open(data_path, 'r', encoding='utf-8') as f:
dataset = [json.loads(line) for line in f]
# Initial dataset stats
print("Num examples:", len(dataset))
# Format error checks
format_errors = defaultdict(int)
for ex in dataset:
if not isinstance(ex, dict):
format_errors["data_type"] += 1
continue
messages = ex.get("messages", None)
if not messages:
format_errors["missing_messages_list"] += 1
continue
for message in messages:
if "role" not in message or "content" not in message:
format_errors["message_missing_key"] += 1
if any(k not in ("role", "content", "name", "function_call") for k in message):
format_errors["message_unrecognized_key"] += 1
if message.get("role", None) not in ("system", "user", "assistant", "function"):
format_errors["unrecognized_role"] += 1
content = message.get("content", None)
function_call = message.get("function_call", None)
if (not content and not function_call) or not isinstance(content, str):
format_errors["missing_content"] += 1
if not any(message.get("role", None) == "assistant" for message in messages):
format_errors["example_missing_assistant_message"] += 1
if format_errors:
print("Found errors:")
for k, v in format_errors.items():
print(f"{k}: {v}")
else:
print("No errors found")If the program gives errors in your training data file then you should fix all the problems first, you will face these errors when running the fine-tune job.
After the file is corrected and there are no errors, you will see the following message:
Num examples: 15
No errors foundStep 2: Uploading the Training Data to OpenAI Server
The next step towards fine-tuning a model is to upload the training data file to OpenAI server using the client.files.create() API.
import os
from openai import OpenAI
input_jsonl_file = 'input_data.jsonl'
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY")
)
file = client.files.create(
file=open(input_jsonl_file, "rb"),
purpose="fine-tune"
)
print("File has been uploaded to OpenAI with id ", file.id)After the file is uploaded, a file ID is generated that we can refer to everytime we need without uploading the file again and again.
File has been uploaded to OpenAI with id file-yCIKv0pm8K54FqmBam0w3BG1Step 3: Fine-tuning a Model with the Uploaded Training Data
3.1. Fine Tuning using OpenAI API
After the file has been uploaded to the OpenAI server, we can use the client.fine_tuning.jobs.create() API to fine-tune the selected chatGPT model with the supplied training data.
import os
from openai import OpenAI
input_jsonl_file = 'input_data.jsonl'
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY")
)
file = client.files.create(
file=open(input_jsonl_file, "rb"),
purpose="fine-tune"
)
print("File has been uploaded to OpenAI with id ", file.id)
ft_job = client.fine_tuning.jobs.create(
training_file=file.id,
model="gpt-3.5-turbo"
)
print("Fine Tune Job has been created with id ", ft_job.id)The API returns a Job ID which refers to an asynchronous Job that has been created on the backend.
Fine Tune Job has been created with id ftjob-cEkAzoJeA3fuFQ7ftfHyqv9YIt’s important to note that the process of creating the model may vary in duration, taking anywhere from a few minutes to hours. The OpenAI servers will continue processing your fine-tuned model until it reaches completion.
We can enquire about the progress of the fine-tuning job using the client.fine_tuning.jobs.list_events() API that returns the latest N statuses related to the job.
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=ft_job.id, limit=10)
print(events)The console output:
SyncCursorPage[FineTuningJobEvent](data=[
FineTuningJobEvent(id='ftevent-QL4SIRzfDkCRAwJZ0aaN3cWU', created_at=1702316542, level='info', message='Validating training file: file-yCIKv0pm8K54FqmBam0w3BG1', object='fine_tuning.job.event', data={}, type='message'),
FineTuningJobEvent(id='ftevent-4lpFir27PhOsjZa2N1a0Q6ti', created_at=1702316542, level='info', message='Created fine-tuning job: ftjob-cEkAzoJeA3fuFQ7ftfHyqv9Y', object='fine_tuning.job.event', data={}, type='message')], object='list', has_more=False)....By utilizing the provided commands, you can continually track and monitor the progress of your fine-tuned model until its creation is finalized. Throughout this period, you can regularly check the status field to remain informed about the current state of the job.
Once the job has been completed, we can get the ID of the fine-tuned model in the final status message:
FineTuningJobEvent(id='ftevent-OqhBL7WqEkkYTQqFCjGS1BSu', created_at=1702289919, level='info', message='New fine-tuned model created: ft:gpt-3.5-turbo-0613:personal::8UXexX8R', object='fine_tuning.job.event', data={}, type='message')In the above message, we can see that a model has been created with the ID: ft:gpt-3.5-turbo-0613:personal.
3.2. Fine Tuning from UI
OpenAI supports creating fine-tuning jobs via the fine-tuning UI. This option is much use friendly and good for small training data sets.
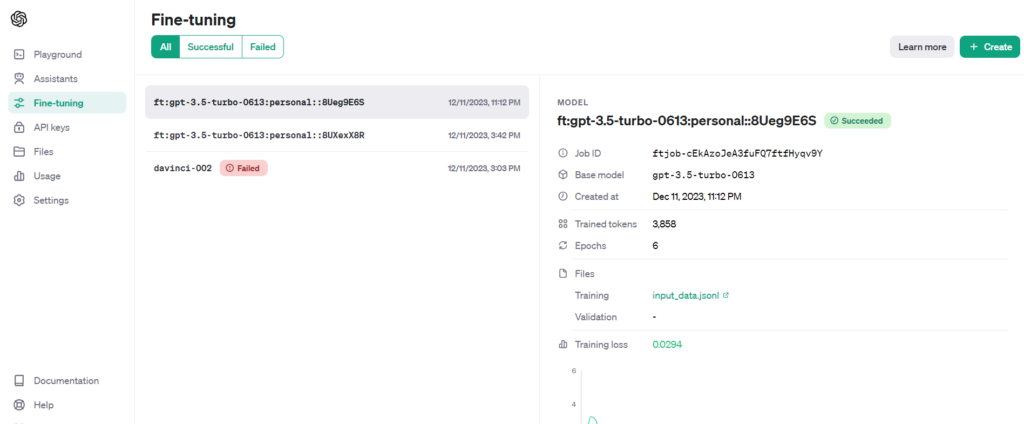
To fine-tune a model, click the ‘+ Create’ button from the top right side of the screen. It opens a popup where we can choose the model to train, and the training data (JSONL) file.
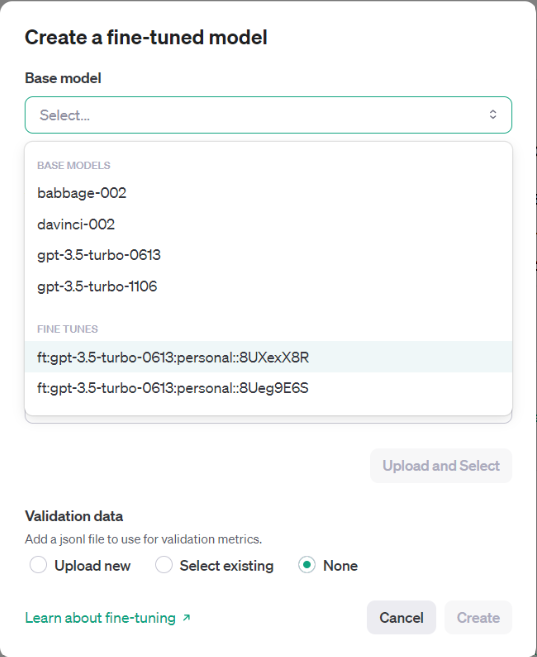
Now upload the training file that generated the file ID. In the same window, we can press the “Create” button to generate a fine-tuned model.
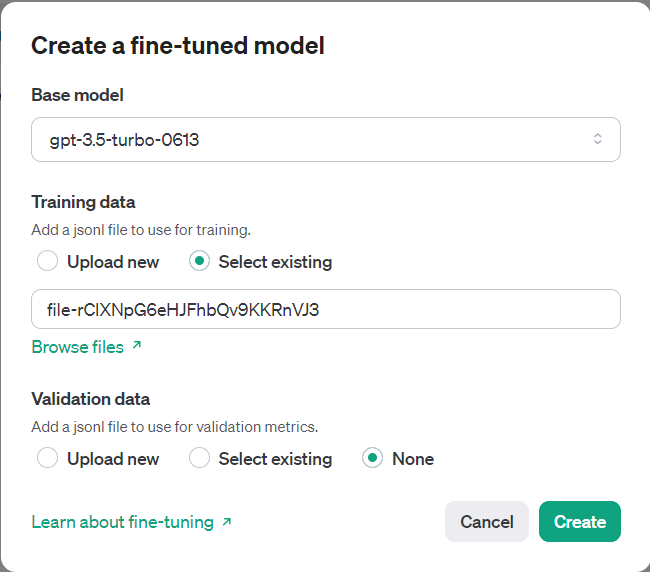
It will start the asynchronous job and we can monitor the progress on this screen itself.
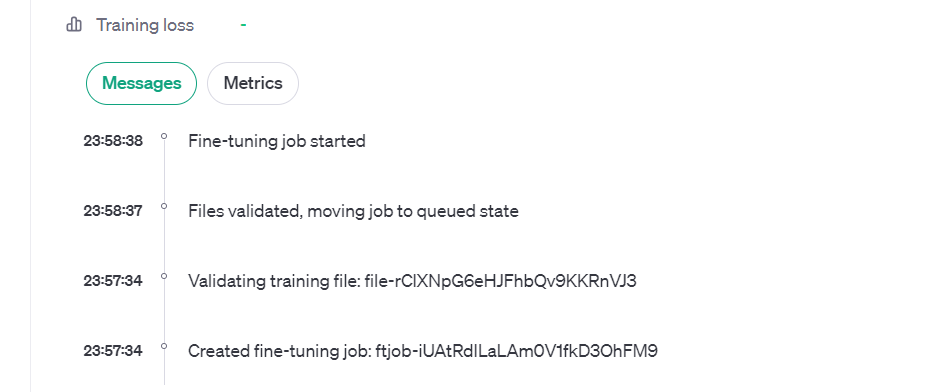
After the Job finishes, we can see that the model has been created successfully.
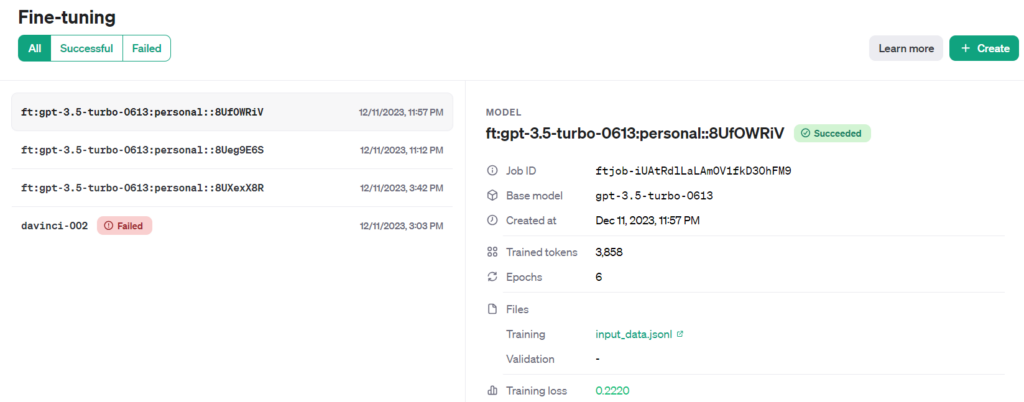
Here we can copy the model ID from the UI that will be used for interacting with the model programmatically.
Step 4: Interacting with Fine-tuned Model using Completion API
After the model has been created, we can interact with the model using the chat completion API as we normally do with the base model. The only difference is that now we provide the created model ID in the request payload:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY")
)
question = input("Ask me anything: ")
response = client.chat.completions.create(
messages=[
{
"role": "user",
"content": question
}
],
model="ft:gpt-3.5-turbo-0613:personal::8UXexX8R",
temperature=0,
max_tokens=1024,
n=1,
stop=None
)
print(response)Run the application and check for a configured prompt and its completion response.
Ask me anything: What security measures are in place to protect my account?
ChatCompletion(id='chatcmpl-8Ueks0SWI7pcB096cud09Hha013p5', choices=[Choice(finish_reason='stop', index=0,
message=ChatCompletionMessage(content='We use industry-standard encryption and authentication methods. Additionally, enable two-factor authentication for added security.', role='assistant',
function_call=None, tool_calls=None))], created=1702317194, model='ft:gpt-3.5-turbo-0613:personal::8UXexX8R',
object='chat.completion', system_fingerprint=None,
usage=CompletionUsage(completion_tokens=19, prompt_tokens=18, total_tokens=37))Notice the API response that it contains the message that we configured for the input prompt in the training data file. This concludes that we have successfully created a fine-tuned chatGPT model with custom training data.
Step 5: Further Improving the Data Quality of the Fine-tuned Model
If the results from a fine-tuning job are not as good as you expected, we can update the training data and run the fine-tuning job again. These are the recommendations for updating the training data:
- Add missing examples that directly show the model how to do the given aspects correctly.
- Update existing examples (with grammar, style, etc) that you expect from the model.
- Check the diversity of examples. The examples should be as close as possible to real conversations.
- Do not write the information in short. Always provide an abundance of details at the training time.
After you have updated the training data, re-upload the file and run the fine-tune job again on the previously fine-tuned model as the starting point. Keep repeating this process until you are satisfied with the quality of completion responses.
In general, a smaller amount of high-quality data is generally more effective than a larger amount of low-quality data.
FAQs
How to delete a fine-tuned Model?
We can delete a fine-tuned model using the OpenAI API as follows:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY")
)
client.models.delete('ft:gpt-3.5-turbo-0613:personal::8UXexX8R')It is important to note that deleting a fine-tuned model should be done judiciously, as it permanently removes the model and its associated data.
How to list all the models?
We can list all the available to us using the OpenAI API as follows. This will list all the base models as well as all fine-tuned models by us.
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY")
)
models = client.models.list()
print(models)The program output:
SyncPage[Model](data=[Model(id='text-search-babbage-doc-001', created=1651172509, object='model', owned_by='openai-dev'), Model(id='curie-search-query', created=1651172509, object='model', owned_by='openai-dev'), Model(id='text-davinci-003', created=1669599635, object='model', owned_by='openai-internal'),
...
...
Model(id='gpt-3.5-turbo-0613', created=1686587434, object='model', owned_by='openai'), Model(id='tts-1-1106', created=1699053241, object='model', owned_by='system'), Model(id='tts-1-hd-1106', created=1699053533, object='model', owned_by='system'), Model(id='dall-e-3', created=1698785189, object='model', owned_by='system')], object='list')Conclusion
In this OpenAI chatGPT tutorial, we have explored the entire life cycle of fine-tuning models. The fine-tuning enriched the base model’s capacity to generate accurate and contextually fitting responses by incorporating domain-specific knowledge and language patterns.
We dived into a comprehensive step-by-step guide on dataset preparation for fine-tuning and uploading the training data to OpenAI servers. We learned to use the training data to create a fine-tuned model and monitor the job progress. Finally, we learned to perform some other important actions such as deleting the unused models.
Happy Learning !!