
Recursion is a powerful algorithmic technique (divide-and-conquer strategy) in which a function calls itself (either directly or indirectly) on a smaller problem of the same type in order to simplify the problem to a solvable state.
1. What is Recursion?
Recursion is an approach for the problems that can be partially solved, with a remaining problem in the same form. In layman’s terms, recursive functions call themselves, but with a slight change in their input arguments until they reach an end condition and return an actual value.
1.1. Structure of Recursion
Recursion consists of two distinct operation types:
- Base condition (or base case): is a predefined condition that solves the problem to return an actual value and unwind the recursive call-chain. The base condition provides its value to the previous step, which can now calculate a result and return it to its predecessor.
- Recursive calls (or recursive case): is referred to the call-chain until the call-chain it reaches the base condition. In this call chain, every step will create a new step with modified input parameters.

Don’t worry about the details of the definitions. The main takeaway is that it is defined in terms of itself: “Recursion: … for more information, see Recursion.” :-)
1.2. Recursion Example
A simple example is calculating a factorial. Factorial of number n is the product of all positive integers less than or equal to n.
f(n) = n * (n-1) * (n-2) * .... * 2 * 1When we use recursion to solve the factorial problem, every step of the calculation breaks down into the product of the input parameter and the next factorial operation. When the calculation reaches fac(1), it terminates and provides the value to the previous step and so on.
For example, we are calculating the factorial of 5. Recursion will create a cascade of recursive calls where f(5) calls f(4), which calls f(3), which calls f(2), which finally calls f(1).
f(1) hits the base condition and returns the actual value 1 to f(2). The f(2) will return 2, f(3) will return 6, f(4) returns 24, then finally f(5) returns the final value of 120
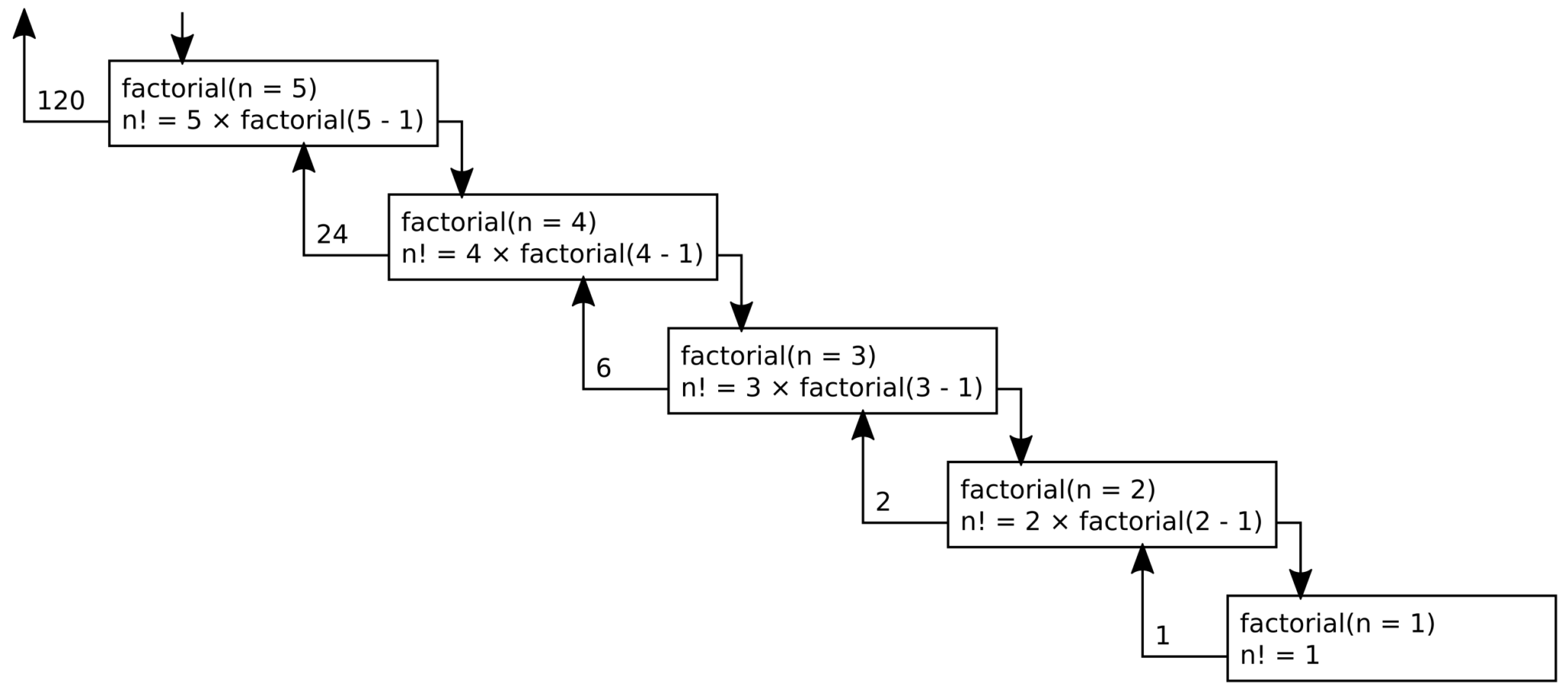
There are many more such problems that we can solve using recursion e.g. Towers of Hanoi (TOH), Inorder/Preorder/Postorder Tree Traversals, DFS of Graph, etc.
2. Recursion Types
In broader sense, recursion can be of two types: direct and indirect recursions.
2.1. Direct or Indirect Recursion
2.1.1. Direct Recursion
In direct recursion, a function calls itself from within itself, as we saw in factorial example. It is the most common form of recursion.
int testfunc(int num) {
if (num == 0)
return 0;
else
return (testfunc(num - 1));
}When a method calls itself, it must encounter some condition where it stops calling itself. If a method calls itself again and again without encountering such a case, it will never terminate. This is called unbounded recursion. It results in the application terminating abnormally.
To prevent unbounded recursion, at least one base condition must exist where the method does not call itself. In addition, it is necessary for the value passed to the method to eventually meet this condition. When this happens, we say that we have bounded recursion.
2.1.2. Indirect Recursion
In indirect recursion, one method, say method A, calls another method B, which then calls method A. This involves two or more methods that eventually create a circular call sequence.
int testfunc1(int num) {
if (num == 0)
return 0;
else
return (testfunc2(num - 1));
}
int testfunc2(int num2) {
return testfunc1(num2 - 1);
}2.2. Head vs Tail Recursion
2.2.1. Head Recursion
In head recursion, the recursive call, when it happens, comes before other processing in the function (think of it happening at the top, or head, of the function).
public void head(int n)
{
if(n == 0)
return;
else
head(n-1);
System.out.println(n);
}2.2.2. Tail Recursion
It is opposite of head recursion. The processing occurs before the recursive call. A tail recursion is similar to a loop. The method executes all the statements before jumping into the next recursive call.
public void tail(int n)
{
if(n == 1)
return;
else
System.out.println(n);
tail(n-1);
} Generally, tail recursions are always better than head recursions. Even though they both have same time complexity and auxiliary space, tail recursions takes an edge in terms of memory in function stack.
Head recursions will wait in function stack memory until the post recursion code statements are executed which causes a latency in overall results, whereas tail recursions will be terminated in function stack over execution.
3. Tail-Call Optimisation (TCO)
3.1. What is Tail-Call Optimisation
If we look closely the tail recursion where we do all the computation before making the recursive all at the very end, there is no need to store the stack frame as there is no calculation is left in that frame. We can simply pass the result of the function to the next recursive call to let it add its result into previously calculated result.
So in the case of tail recursion, we can eliminate the creation of a new stack frame and just re-use the current stack frame. The stack never gets any deeper, no matter how many times the recursive call is made.
This way, TCO lets us convert regular recursive calls into tail calls to make recursions practical for large inputs, which was earlier leading to stack overflow error in normal recursion scenario.
For example, without tail recursion, a factorial program stack frames look like this:
(fact 3)
(* 3 (fact 2))
(* 3 (* 2 (fact 1)))
(* 3 (* 2 (* 1 (fact 0))))
(* 3 (* 2 (* 1 1)))
(* 3 (* 2 1))
(* 3 2)
6In contrast, the stack trace for the tail recursive factorial looks as follows:
(fact 3)
(fact 3 1)
(fact 2 3)
(fact 1 6)
(fact 0 6)
6As we can see, we only need to keep track of the same amount of data for every call to fact because we are simply returning the value we get right through to the top.
This means that even if I were to call (fact 1000000), I need only the same amount of space as (fact 3). This is not the case with the non-tail-recursive fact, and as such large values may cause a stack overflow.
In tail recursion, due to no additional calculations required on the returned value of the recursive call, stack frames are not required. This reduces the stack frame space complexity of the recursive call from O(N) to O(1), resulting in faster and more memory-friendly machine-code.
3.2. Tail-Call Optimisation with Java Streams
Memory is finite and can quickly exhaust if not used smartly. Take a look at below code. It uses simple recursion logic to find the sum of numbers from to 1 to N, where N is the method argument.
public class RecursionDemo {
public static void main(String[] args) {
var result = simpleRecursiveSum(1L, 40000L);
System.out.println(result);
}
static long simpleRecursiveSum(long total, long summand) {
if (summand == 1L) {
return total;
}
return simpleRecursiveSum(total + summand, summand - 1L);
}
}The above code will result in Exception in thread “main” java.lang.StackOverflowError error. This is because the program creates a huge number of stack frames and memory goes out of limit.
Java Streams can be used to support tail-call optimization and we can implement a better way to do recursive style coding ourself. We can write recursive function with streams that runs until reaching a base condition.
But instead of calling the lambda expression recursively, it returns a new expression that runs in the Stream pipeline. This way, the stack depth will remain constant, regardless of the number of performed steps.
The given RecursiveCall interface is a functional interface and can be used to write recursive operations in more optimized manner.
In below code, the apply() represents the recursive call. It executes the recursive step and returns a new lambda with the next step. The call to done() will return a terminating specialized instance of RecursiveCall, signaling the recursion’s termination. The invoke() method now will return the final result of the computation.
import java.util.stream.Stream;
@FunctionalInterface
public interface RecursiveCall<T> {
RecursiveCall<T> apply();
default boolean isComplete() {
return false;
}
default T result() {
throw new Error("not implemented");
}
default T run() {
return Stream.iterate(this, RecursiveCall::apply)
.filter(RecursiveCall::isComplete).findFirst().get().result();
}
static <T> RecursiveCall<T> done(T value) {
return new RecursiveCall<T>() {
@Override
public boolean isComplete() {
return true;
}
@Override
public T result() {
return value;
}
@Override
public RecursiveCall<T> apply() {
throw new UnsupportedOperationException();
}
};
}
}To use above interface, we must call RecursiveCall.done() when thw base condition is reached; i.e. the value is 1. Until then, we must create a new RecursiveCall with decreasing the N by 1, and adding the N to the total running sum.
The given code now executes successfully and the total sum is printed in the console.
public class RecursionDemo
{
public static void main(String[] args) {
var result = sum(1L, 40000L).run();
System.out.println(result);
}
static RecursiveCall<Long> sum(Long total, Long summand) {
if (summand == 1) {
return RecursiveCall.done(total);
}
return () -> sum(total + summand, summand - 1L); //800020000
}
}3.3. Project Loom’s Unwind and Invoke
The primary goal of Project Loom is to support a high-throughput, lightweight concurrency model in Java. It will provide support for lightweight threads (fibres) and tail recursion (unwind-and-invoke). You can read the detailed infromation on its proposal page.
The new feature unwind-and-invoke, or UAI will add the ability to manipulate call stacks to the JVM. UAI will allow unwinding the stack to some point and then invoke a method with given arguments (basically, a generalization of efficient tail-calls). This will lower the barriers to use recursion if the necessary tools are available.
As part of Project Loom, UAI will be done in the JVM and exposed as very thin Java APIs.
4. Recursion with Stack
Stack is a LIFO (last in, first out) data structure that comes from the analogy to a set of physical items stacked on top of each other. This structure makes it easy to take an item off the top of the stack, while getting to an item deeper in the stack may require taking off multiple other items first.
In Stack, the push and pop operations occur only at one end of the structure, referred to as the top of the stack. Every push operation creates a new stack frame in the stack.
In functional programming, a stack frame contains the state of a single method invocation. Every time the code calls a method, the JVM creates and pushes a new frame on the global stack. After returning from a method, its stack frame gets popped and discarded.
While using recusrion, each recursive function call f(n) is stored as stack frame because every value of n must be isolated from the previous calculation. There will be as many stack frames as there are recursive function calls to reach the base condition.
Note that if the available stack size is finite. Too many calls will fill up the available space and lead to a StackOverflowError.
5. Recursion with Tree
Similar to stack, A tree is also a recursive data type. A tree also stores information in its nodes which can be searched in the applications when needed.
Three of most common ways to traverse a tree are known as in-order, pre-order, and post-order. And most efficient technique to implement any of the search order is using recursion.
For example, searching a binary search tree for a certain piece of data is very simple. We start at the root of the tree and compare it to the data element we’re searching for. If the node we’re looking at contains that data, then we’re done. Otherwise, we determine whether the search element is less than or greater than the current node. If it is less than the current node we move to the node’s left child. If it is greater than the current node, we move to the node’s right child. Then we repeat as necessary.
Eventually, recursively, we get to a point where the ‘sub trees’ are just nodes. At this point, if we reach to the base condition then we found the result. Remember how we defined recursion as solving sub problems of a bigger problem. Binary search is another usecase of that theory.
SEARCH(x, T)
if(T.root != null)
if(T.root.data == x)
return r
else if(T.root.data > x)
return SEARCH(x, T.root.left)
else
return SEARCH(x, T.root.right)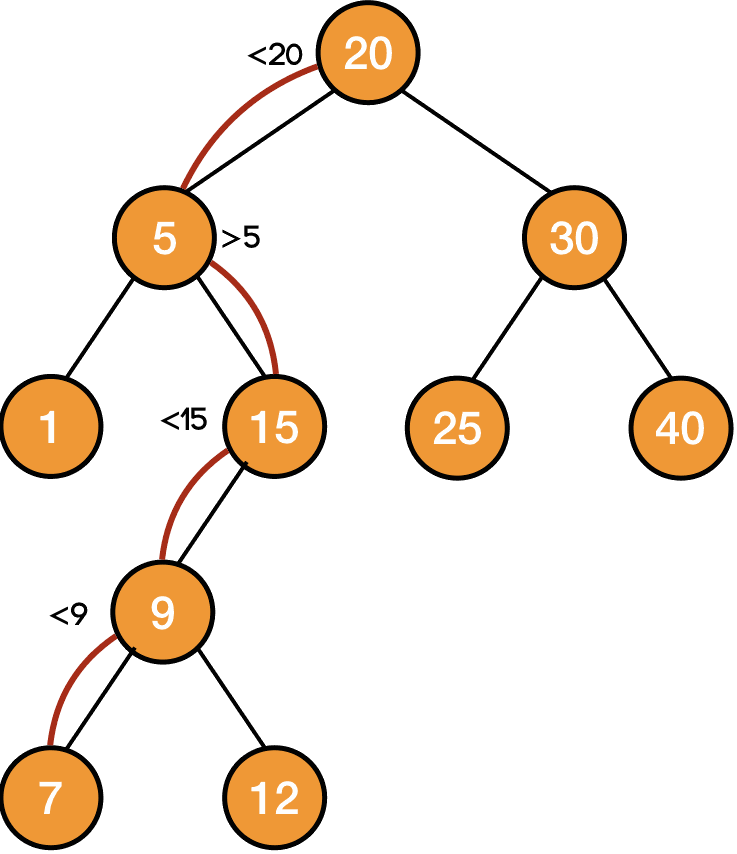
Similar to the search operation, in fact, all tree operations (sorting, insertion, deletion) can be implemented with the help of recursion.
6. Difference between Recursion and Iteration
Generally, each above-discussed problem can be solved using either iteration or recursion. The ideal solution depends highly on the problem we want to solve and in which environment our code runs.
Recursion is often the preferred tool for solving more abstract problems, and iteration is preferred for more low-level code. An iteration might provide better runtime performance, but recursion can improve your productivity as a programmer.
Note that It’s easy to get it wrong and can be harder to understand an existing recursive solution. Be very careful about slower execution times and stack-overflow problems when choosing between recursion and its alternatives.
Let us see a quick comparison of both approaches:
| Factor/Property | Recursion | Iteration |
|---|---|---|
| Basic | Recursion is the process of calling a function itself within its own code. | In Iteration, loops are used to execute the set of instructions repetitively until the condition is false. |
| Syntax | Recursion has a termination condition known as base condition. | Iteration includes initialization, condition, and increment/decrement of a variable. |
| Performance | It is slower than iteration. | It is faster than recursion. |
| Applicable To | The problem can be partially solved, with the remaining problem will be solved in the same form. | The problem is converted into a series of steps that are finished one at a time, one after another. |
| Time Complexity | It has high time complexity. | It has relatively lower time complexity. We can calculate the time complexity by finding the number of iterations in the loop.. |
| Stack | It has to update and maintain the stack in certain types of recursions. | There is no utilization of stack. |
| Memory | IF TCO is not applied, it uses more memory as compared to iteration. | It uses less memory as compared to recursion. |
7. Conclusion
A recursive algorithm breaks down a problem into smaller pieces which we either already know the answer to, or can solve by applying the same algorithm to each piece, and then combining the results.
Recursions are a valuable tool in programming, but a simple implementation of recursion is often not useful for practical problems. Functional interfaces, lambda expression, and infinite Streams can help us design tail-call optimization to make recursions feasible in such cases.
Happy Learning !!
Reference:
Functional Programming in JAVA by Venkat Subramaniam