Apache Kafka is an open-source distributed event streaming service used for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. It enables users to collect, store, and process data to build real-time event-driven applications.
In this article, we will learn how to configure and deploy a single-node and a multi-node setup of Apache Kafka using Docker Compose.
1. Kafka Terminologies
Let us begin with the high-level definitions and overview of important Kafka terminologies. The following is the architecture diagram of a multi-node kafta cluster. You can learn the architecture in detail in the Apache Kafka tutorial.
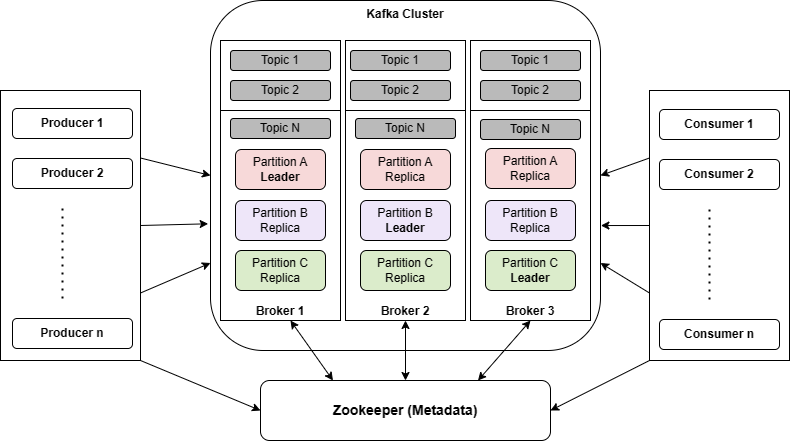
- Producer – A Kafka producer is an application that sends data/events to a Kafka topic. Producers send the messages to the broker, which then distributes the data across the available partitions.
- Consumer – A program that subscribes to one or more topics and receives messages from brokers.
- Topics – A category or feed name to which messages are published. It represents a particular stream of data.
- Partitions – Partitions are where the messages live inside the topic. Each topic is created with one or more partitions. The partitions have a significant effect on scalable message consumption. Each partition is hosted on a separate Kafka broker.
- Broker – A single Kafka server instance that stores and manages the partitions. Brokers act as a bridge between consumers and producers.
- Leader: Each partition has one broker acting as the leader, responsible for handling all read and write requests for that partition. The leader replicates data to other brokers to provide fault tolerance.
- Replication Factor – A replication factor is the number of copies of a message over multiple brokers. The value should be less than or equal to the number of brokers that we have. Replication provides high availability and fault tolerance.
- Offset: Each message within a partition is assigned a unique identifier called an offset. It represents the position of a message within a partition.
- Consumer Offset: It indicates the position of the last message consumed by a consumer from a specific partition. It helps consumers track their progress within a partition.
- Producer Acknowledgment: It is a configuration option for the level of acknowledgment required from Kafka brokers after a message is published. It can be set to ensure message durability and reliability.
Apart from that the Kafka uses Apache ZooKeeper for distributed coordination, including managing and maintaining cluster metadata (about all nodes, topics, partitions etc), tracking nodes’ status, leader selection, and tracking consumer offsets.
2. Kafka Single-Node Setup using Docker Compose
The following docker-compose.yml file that creates a single-node Kafka server with 1 zookeeper and 1 broker instance. The configuration also ensures that the Zookeeper server always starts before the Kafka server (broker) and stops after it.
---
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "22181:2181"
broker:
image: confluentinc/cp-kafka:latest
container_name: broker
ports:
- "19092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:19092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1In the above configuration, the zookeeper server listens on port 2181 within the container setup for the broker service. However, when accessed from the host machine, clients will connect to it through the mapped port 22181.
Likewise, the broker service is accessible to host applications through port 19092, but within the container environment, it is advertised on port 9092 as specified by the KAFKA_ADVERTISED_LISTENERS property.
Let’s understand other environment properties used in the configuration:
- KAFKA_BROKER_ID – The broker.id property is the unique and permanent name of each node in the cluster.
- KAFKA_AUTO_CREATE_TOPICS_ENABLE – If the value is true then it allows brokers to create topics when they’re first referenced by the producer or consumer. If the value is set to false, the topic should be first created using the Kafka command and then used.
- KAFKA_ZOOKEEPER_CONNECT – instructs Kafka how to contact Zookeeper.
- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR – is required when we are running with a single-node cluster. If you have three or more nodes, we can use the default.
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP – defines key/value pairs for the security protocol to use per listener name.
- KAFKA_ADVERTISED_LISTENERS – makes Kafka accessible from outside the container by advertising its location on the Docker host.
To start the Kafka server, use ‘docker-compose up’ in the same directory where the compose file is stored.
docker-compose up3. Kafka Multi-Node Cluster Setup using Docker Compose
For proof-of-concept or non-critical development work, a single-node cluster works fine. However, having just a single node presents below issues:
- Scalability – replication factor will be limited to one. All the partitions of a topic will be stored on the same node. So, load across multiple brokers cannot be spread to maintain certain throughput.
- Fail-over – Since we have only one node, we might face data loss in case the node goes down.
- Availability – Since we have a single broker when the broker fails, we will have a downtime
In real-world scenarios, we will need a more resilient setup to have redundancy for both the zookeeper servers and the Kafka brokers. The following docker-compose.yml creates a cluster with 2 zookeeper nodes and 3 broker nodes as shown below:
---
version: '3'
services:
zookeeper-1:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper-1
environment:
ZOOKEEPER_SERVER_ID: 1
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "22181:2181"
zookeeper-2:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper-2
environment:
ZOOKEEPER_SERVER_ID: 2
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "32181:2181"
broker-1:
image: confluentinc/cp-kafka:latest
container_name: broker-1
ports:
- "19092:9092"
depends_on:
- zookeeper-1
- zookeeper-2
environment:
KAFKA_BROKER_ID: 1
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181,zookeeper-2:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker-1:9092,PLAINTEXT_HOST://localhost:19092
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
broker-2:
image: confluentinc/cp-kafka:latest
container_name: broker-2
ports:
- "19093:9092"
depends_on:
- zookeeper-1
- zookeeper-2
environment:
KAFKA_BROKER_ID: 2
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181,zookeeper-2:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker-2:9093,PLAINTEXT_HOST://localhost:19093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
broker-3:
image: confluentinc/cp-kafka:latest
container_name: broker-3
ports:
- "19094:9092"
depends_on:
- zookeeper-1
- zookeeper-2
environment:
KAFKA_BROKER_ID: 3
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper-1:2181,zookeeper-2:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker-3:9094,PLAINTEXT_HOST://localhost:19094
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXTIt is essential to ensure that service names and the KAFKA_BROKER_ID are distinct for each service. Additionally, each service should have a unique port exposed to the host machine. For instance, while zookeeper-1 and zookeeper-2 listen on port 2181, they are exposed to the host through ports 22181 and 32181, respectively. Similarly, the broker-1, broker-2, and broker-3 services, will be listening on ports 19092, 19093, and 19094, respectively.
Now that we have created a Kafka cluster successfully, let’s do some operations and verify the same.
4. Modifying Cluster Configuration
If we need to modify cluster configuration, for example, add or remove the brokers and zookeeper instances, then follow these steps:
- Stop the Kafka cluster using the following command in the directory where your Docker Compose file is located:
docker-compose down- Modify the Docker Compose file and add new service definitions for the new brokers specifying their container names, images, environment variables, ports, and any other necessary configurations. Make sure to give them a unique name.
- To remove a Kafka broker, remove the service definition for the broker you want to remove. Also, ensure to handle data replication and rebalancing properly to maintain availability and consistency. Adjust the replication factor and partition assignments accordingly.
- Start the Kafka cluster with the modified configuration. Docker Compose will read the updated Docker Compose file and deploy the Kafka cluster with the new configuration.
docker-compose up -d- Verify the cluster configuration using Kafka CLI or Kafka Manager to ensure that the new brokers have been added or the removed brokers are no longer part of the cluster.
5. Creating Topics
Kafka stores messages in topics. It is considered a best practice to create topics explicitly before using them, regardless of Kafka’s configuration to create them when referenced automatically.
The below command creates the ‘todo‘ topic with 6 partitions and with a replication factor of 3.
$ docker exec broker-1 \
kafka-topics --bootstrap-server broker-1:9092 \
--create \
--topic todos --partitions 6 --replication-factor 3To confirm the cluster setup we use the below command:
$ docker exec broker-1 \
kafka-topics --bootstrap-server broker-1:9092 \
--describe todos Using the above command we get various information about the topic such as the partition leader, replica information, etc as shown below:

6. Testing Message Producer
Utilizing the kafka-console-producer command line tool, we can effectively generate messages on a specific topic. Although it serves well for experimentation and troubleshooting, in real-world scenarios, the recommended approach is to use the Producer API within your application code to send messages.
The below command starts a producer and will wait for our input to produce messages into Kafka.
$ docker exec --interactive --tty broker-1 \
kafka-console-producer \
--broker-list broker-1:9092,broker-2:9093,broker-3:9094 \
--topic todosNow, type some lines, each line is a new message as shown below:

7. Testing Message Consumer
Since we produced messages from the broker-1 instance, we will read messages from broker-3 to confirm our cluster setup. To launch the kafka-console-consumer and read the messages back, use the following command.
$ docker exec --interactive --tty broker-3 \
kafka-console-consumer \
--bootstrap-server broker-1:9091,broker-2:9093,broker-3:9094 \
--topic todos \
--from-beginningOnce the consumer is up, the produced messages should be printed on the console. The –from-beginning argument ensures that messages will be read from the beginning of the topic.

8. Conclusion
In this article, we used Docker Compose to set up a single node and muti-node cluster of Apache Kafka. Now we can easily add or remove zookeeper or broker nodes as per our needs.
Happy Learning !!
Comments