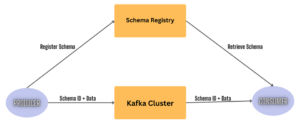
Kafka is a popular choice for building data pipelines, real-time analytics, and event-driven applications. One of the key features that make Kafka powerful is its ability to handle schema evolution and data compatibility challenges efficiently. Schema Registry and Avro Serialization are excellent tools for achieving the changes in schema very efficiently.
Let us learn how schema registry and Avro help in managing the schema evolution.
1. Schema Evolution and Its Challenges
Data serialization is the process of converting data structures or objects into a format that can be easily stored, transmitted, or reconstructed. One common challenge in data serialization arises from schema evolution due to changes in the structure or definition of data over time. These changes can make it difficult to deserialize and interpret data that was serialized using a previous schema.
When the schema changes, it’s important to maintain backward and/or forward compatibility. Backward compatibility ensures that new code can read data serialized with an old schema. Forward compatibility allows old code to read data serialized with a new schema.
Consider the below JSON schema. The Kafka producer and consumer program written for this schema/message structure would work fine until there is a change in it.
{
"id": 1
"firstName": "John",
"lastName": "Doe",
"ordered_time": "2023-09-05T13:11:03.511Z",
"status": "NEW"
}Now let’s add a new field middleName.
{
"id": 1
"firstName": "John",
"lastName": "Doe",
"middleName": "Test", //New Field
"ordered_time": "2023-09-05T13:11:03.511Z",
"status": "NEW"
}Now, the message producer has the latest changes and sends data to the consumer with variable middleName. But, the consumer will fail here because it doesn’t identify the field middleName and so when it tries to deserialize the object it will throw an exception.
2. How Schema Registry Solved the Challenges Due to Schema Evolution?
Schema Registry is a standalone server process that runs on a machine external to the Kafka brokers. Its job is to maintain a database of all of the schema versions that have been written into topics in the cluster for which it is responsible.
Schemas are stored by subject (a logical category), and by default, the registry does a compatibility check before allowing a new schema to be uploaded against a subject. Each subject corresponds to a specific Kafka topic or event type, and versioned schemas related to that topic.
Each time we register a new schema for a subject, it gets a unique version identifier. This versioning allows consumers and producers to specify which version of the schema they want to use when serializing or deserializing data.
When a producer sends a message, it calls an API at the Schema Registry REST endpoint and presents the schema of the new message.
- If the schema is the same as the last message produced, then the producer may succeed.
- If the schema is different from the last message but matches the compatibility rules defined for the topic, the producer may still succeed.
- But if the schema is different in a way that violates the compatibility rules, the producer will fail in a way that the application code can detect.
Likewise, on the consumer side, it uses the registry to fetch the sender’s schema. If a consumer reads a message that has an incompatible schema from the version the consumer code expects, the Schema Registry will instruct it not to consume the message.
3. Compatability Types in Schema Registry
The following table presents a summary of the types of schema changes allowed for the different compatibility types, for a given subject.
| Compatibility Type | Changes allowed | Check Against Which Schemas | Upgrade First |
|---|---|---|---|
| BACKWARD | – Delete fields – Add optional fields | Last version | Consumers |
| BACKWARD_TRANSITIVE | – Delete fields – Add optional fields | All previous versions | Consumers |
| FORWARD | – Add fields – Delete optional fields | Last version | Producers |
| FORWARD_TRANSITIVE | – Add fields – Delete optional fields | All previous versions | Producers |
| FULL | – Add optional fields – Delete optional fields | Last version | Any order |
| FULL_TRANSITIVE | – Add optional fields – Delete optional fields | All previous versions | Any order |
| NONE | – All changes are accepted | Compatibility checking disabled | Depends |
The Confluent Schema Registry default compatibility type is BACKWARD. The main reason that BACKWARD compatibility mode is the default is that we can rewind consumers to the beginning of the topic. With FORWARD compatibility mode, we aren’t guaranteed the ability to read old messages.
The above
middleNameissue is resolved using FORWARD compatibility, as it allows us to add new fields in the producer without causing any issues in the consumer.
4. Understanding the Role of Apache Avro
Avro is a framework for schema evolution, versioning, serialization and deserialization. It helps us to make changes to our data schemas over time without breaking backward or forward compatibility.
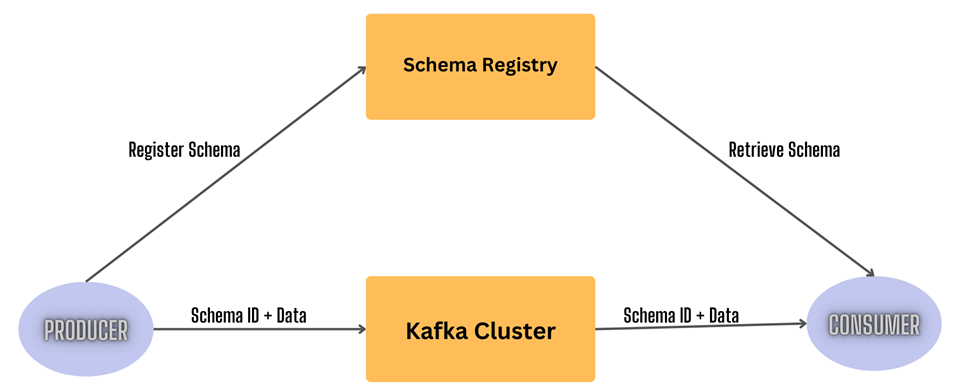
When using normal JSON serialization, without Avro, the entire JSON payload is sent to the Kafka server. So when the size of JSON increases with schema evolution, so does the memory overhead and latency.
To tackle the payload size issue, Apache AVRO uses the binary serialization method. It uses a compact binary format for serializing data which is highly efficient in terms of both size and speed. Unlike JSON or XML, Avro’s binary format is optimized for machine consumption.
By combining AVRO with schema registry, we can externalize schema, and serialize and deserialize data into bytes according to that schema. Rather than supply a copy of that schema with each message, which would be an expensive overhead, it’s also common to keep the schema in a registry and supply just an ID with each message as shown in the image below:
5. Demo Overview and Environment Setup
To demonstrate the integration of Kafka, Avro and Schema Registry, we will do the following steps:
- Prepare local environment using docker-compose with four containers i.e. Kafka broker, zookeeper, schema registry and create-topic
- Create the Order schema with few fields and test the Kafka message producer and consumer modules
- Modify the Order schema, and producer module to accommodate the addition of a new field “middleName“
- Verify the Kafka message producer and consumer modules again so the new messages are consumed without error
For local development and testing purposes, the following docker-compose.yml is a Docker Compose configuration file that defines a multi-container environment using three services: ZooKeeper, Kafka Broker, and Schema Registry.
---
version: '3.6'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.1.0
platform: linux/amd64
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-server:7.1.0
platform: linux/amd64
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
schema-registry:
image: confluentinc/cp-schema-registry:7.1.0
platform: linux/amd64
hostname: schema-registry
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0/
create-topic:
image: confluentinc/cp-kafka:7.1.0
command: [ "kafka-topics", "--create", "--topic", "orders-sr", "--partitions", "1", "--replication-factor", "1", "--if-not-exists", "--bootstrap-server", "broker:9092" ]
depends_on:
- zookeeper
environment:
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092If a more resilient Kafka setup is needed, then we can use the following docker cluster configuration using Docker Compose. We can change the configurations based on the specific requirements.
6. Publishing Kafka Messages using Schema Registry
To publish a message, we need two modules:
- schema: maintains the latest schema and its version
- order-service: connects to Kafka cluster and sends a message to the configured topic
6.1. Maven
Include the latest versions of Avro dependency as follows so we can use it with the Schema registry:
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>io.confluent</groupId>
<artifactId>kafka-avro-serializer</artifactId>
<version>5.5.1</version>
</dependency>
<repositories>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>We also need to use Avro Maven plugin to generate the Avro classes. We specify the source directory where schema files are present and the output directory where the Java classes need to be generated.
<build>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.9.2</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
<enableDecimalLogicalType>true</enableDecimalLogicalType>
<customConversions>org.apache.avro.Conversions$UUIDConversion</customConversions>
</configuration>
</execution>
</executions>
</plugin>
</build>6.2. Creating Schema and Generating Classes from Schema
Next, let’s define a schema for Order class. We name it as Order.avsc.
{
"name": "Order",
"namespace": "com.howtodoinjava.avro.example.domain.generated",
"type": "record",
"fields": [
{
"name": "id",
"type": {
"type": "string",
"logicalType": "uuid"
}
},
{
"name": "firstName",
"type": "string"
},
{
"name": "lastName",
"type": "string"
},
{
"name": "ordered_time",
"type": {
"type": "long",
"logicalType": "timestamp-millis"
}
},
{
"name": "status",
"type": "string"
}
]
}Now, we run the maven command:
mvn clean installIt internally executes the schema goal from avro-maven-plugin and generates Java classes from schema. The classes are generated in the package which is mentioned in namespace field in the schema file.
6.3. Producing Messages with KafkaAvroSerializer
First, let’s add configuration for the producer that uses KafkaAvroSerializer as a key and value serializer, which in turn uses the Schema Registry and Avro.
Note that it is not mandatory to use KafkaAvroSerializer as a key serializer. We can use use String, Integer or any standard serializer for keys.
import io.confluent.kafka.serializers.KafkaAvroSerializer;
import io.confluent.kafka.serializers.KafkaAvroSerializerConfig;
import io.confluent.kafka.serializers.subject.RecordNameStrategy;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
private static KafkaProducer<Integer, CoffeeOrder> configureProducer() {
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class);
properties.put(KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081");
return new KafkaProducer<>(properties);
}The property KafkaAvroSerializerConfig.SCHEMA_REGISTRY_URL_CONFIG is used to specify the url of our schema registry server.
Next, we use the configured producer to produce messages:
private static final String ORDERS_TOPIC_SR = "orders-sr";
KafkaProducer<String, Order> producer = configureProducer();
Order order = buildNewOrder();
ProducerRecord<String, Order> producerRecord =
new ProducerRecord<>(ORDERS_TOPIC_SR, order.getId().toString(), order);
producer.send(producerRecord, (metadata, exception) -> {
if (exception == null) {
System.out.println("Message produced, record metadata: " + metadata);
System.out.println("Producing message with data: " + producerRecord.value());
} else {
System.err.println("Error producing message: " + exception.getMessage());
}
});
producer.flush();
producer.close();We can run the class and check the logs to verify that the message is produced successfully:
Message produced, record metadata: orders-sr-0@6
Producing message with data: { "id": 3a2a6134-a2b9-40d9-8462-e5dedcea3746,
"firstName": "John", "lastName": "Doe", "ordered_time": 2023-09-12T10:12:36.748Z, "status": "NEW"}7. Consuming Kafka Messages with KafkaAvroDeserializer
Just like with the producer, we have to let the consumer know where to find the Schema Registry, and configure the KafkaAvroDeserializer.
private static KafkaConsumer<String, Order> configureConsumer() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "order.consumer.sr");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
props.put(KafkaAvroDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG, "http://localhost:8081");
props.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
return new KafkaConsumer<>(props);
}We set KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG value to true as we need to tell Kafka to use the generated version of the Order object. If we did not, then it would deserialize the value into org.apache.avro.generic.GenericRecord instead of our generated Order object, which is a SpecificRecord.
private static final String ORDERS_TOPIC_SR = "orders-sr";
KafkaConsumer<String, Order> consumer = configureConsumer();
consumer.subscribe(Collections.singletonList(ORDERS_TOPIC_SR));
System.out.println("Consumer Started");
while (true) {
ConsumerRecords<String, Order> records = consumer.poll(Duration.ofMillis(2000));
for (ConsumerRecord<String, Order> orderRecord : records) {
Order order = orderRecord.value();
System.out.println(
"Consumed message: \n key: " + orderRecord.key() + ", value: " + order.toString());
}
}We can check the logs that the messages are consumed successfully:
Consumed message:
key: 3a2a6134-a2b9-40d9-8462-e5dedcea3746,
value: {"id": 3a2a6134-a2b9-40d9-8462-e5dedcea3746, "firstName": "John",
"lastName": "Doe", "ordered_time": 2023-09-12T10:12:36.748Z, "status": "NEW"}
8. Testing Compatibility with Changes in Schema
Now, let’s evolve the above schema by adding the middleName field and then verifying our producer and consumer.
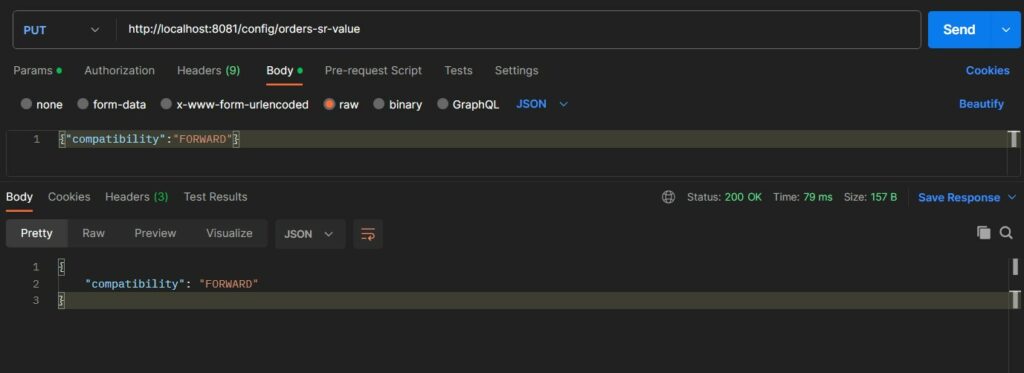
8.1. Changing Compatibility Type
First, we need to change the compatibility for the schema to FORWARD using the below API request. We can use Postman or any API tool:
curl --request PUT \
--url http://localhost:8081/config/orders-sr-value \
--header 'Content-Type: application/json' \
--data '{
"compatibility": "FORWARD"
}'
8.2. Changing the Schema Module
Now, let’s evolve our schema only for the producer. To do this, first, we need to change the project version from 1.0 to 2.0 in the pom.xml file so that the upgraded schema is registered in the schema registry with a new version ID.
<version>2.0</version>Next, we update the schema and add middleName as shown below:
{
"name": "Order",
"namespace": "com.howtodoinjava.avro.example.domain.generated",
"type": "record",
"fields": [
//....
{
"name": "middleName",
"type": "string"
},
//....
]
}Then, we build the schema and generate the equivalent Java classes.
mvn clean install8.3. Changing the Producer Module
Build the producer module so it can refer to the updated schema.
mvn clean installNext, we update the producer to send the newly added field with the modified schema.
private static Order buildNewOrder() {
return Order.newBuilder()
.setId(UUID.randomUUID())
.setFirstName("John")
.setLastName("Doe")
.setMiddleName("TestMiddleName") //Added field
.setOrderedTime(Instant.now())
.setStatus("NEW")
.build();
}Finally, send the message to the Kafka topic, similar to the previous run.
Message produced, record metadata: orders-sr-0@7
Producing message with data: {"id": 98eade55-a5c8-49e9-b779-0f495ee7b7a3, "firstName": "John",
"lastName": "Doe", "middleName": "TestMiddleName", "ordered_time": 2023-09-12T11:09:53.264Z, "status": "NEW"}8.4. Verifying Message Consumer
Run the Kafka producer code again and notice the outputs. We notice that the message is consumed with the old schema successfully even though the middleName field is not present.
Consumed message: key: 98eade55-a5c8-49e9-b779-0f495ee7b7a3,
value: {"id": 98eade55-a5c8-49e9-b779-0f495ee7b7a3, "firstName": "John", "lastName": "Doe",
"middleName": "TestMiddleName", "ordered_time": 2023-09-12T11:09:53.264Z, "status": "NEW"}
9. Conclusion
In this Kafka tutorial, we learned about Apache AVRO and Schema Registry. We also learned to integrate the Schema Registry with the Kafka Producer and Consumer application and how to evolve schema with a simple demo.
Happy Learning !!
Hi Lokesh,
I have another question and doubt related to Compatibility Types in Schema Registry section.
If you can share your thoughts on this:
I am getting confused with this, it seems to me a backward Compatible change:
What is the Avro schema evolution rule for removing a field?
this is referenced here:
https://github.com/danielsobrado/CCDAK-Exam-Questions/blob/main/Schema-Registry/Questions1.md#question-6
“Therefore, removing a field allows new code to read old data (forward compatibility), but not old code to read new data (backward compatibility).” this seems to be other way ?
I feel the confusion arises because of the new code (consumer) vs old code (consumer) in the language used in both texts. The official docs refer to consumer still running the old code and only using the new schema. Whereas Github link refers to consumer running the new updated code.
For me, when I say compatibility then I assume that only the schama has been changed. The consumer (and producer) is still running the old code. This is the case discussed in official docs, so I will go with deletion of field is backward compatible change.
It does not mean that the Github question answer is wrong, it is just a different perspective.
Hi Lokesh,
This is awesome content as always.
I have one doubt, does Kafka broker itself validate anything with schema registry. because broker just saves the data as it is in binary format.
No. Kafka manages only the storage, replication, and retrieval of the data, not its structure or validity. Schema validation happens on the producer side. The producer ensures data matches the schema before sending it. Kafka stores and transfers data as-is without inspecting or validating its content.
Thanks Lokesh for confirmation.
Actually the first diagram shows kafka would validate the schema as in the 3rd step, which brought this doubt.
Oh. I have fixed the image.