
In this Apache Kafka tutorial, we’ll learn to configure and create a Kafka Streams application using Spring Boot. We will also build a stream processing pipeline and write test cases to verify the same.
1. Introduction to Kafka Streams
The Kafka Streams library is a robust stream processing tool used to enrich data by performing various operations such as data transformation, data aggregation, and joining data from multiple Kafka topics. Kafka Streams uses functional programming techniques, like lambda expressions, mapping, filtering, and flatMap, which are commonly found in modern Java programming.
Kafka Streams support stateless and stateful operations, allowing us to maintain and update the state while processing streams. This stateful processing capability is advantageous when dealing with complex event processing or when we need to correlate and analyze data across different streams. For example, we can calculate the real-time total number of orders, total revenue, or total number of tickets sold.
Kafka Streams provides a high-level DSL (Domain-Specific Language) and a low-level Processor API. The DSL offers a more declarative and easy-to-use approach, whereas the Processor API allows for fine-grained control and allows custom logic implementation.
2. What is a Processor Topology?
The processor topology represents the structure of the stream processing application. It defines how the input data streams are read, transformed, processed, and produced. It consists of a directed acyclic graph (DAG) of processing nodes, where each node represents a processing step. The topology defines the flow of data and the relationships between different processing stages.
The processors in Kafka Streams are shown below:
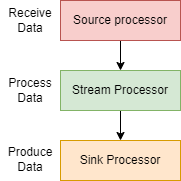
Initially, Source processors receive data from one or more Kafka topics and deserialize it before forwarding them to the Stream Processor node which contains the main transformation or computation logic. Finally, Sink Processor writes the processed data into one or more output Kafka Topic or to a State Store.
3. Setting up Kafka Streams in Spring Boot Application
3.1. Maven
To use Kafka Streams with the Spring Boot application we add spring-kafka and kafka-streams dependency.
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>We also need spring-kafka-test, kafka-streams-test-utils and awaitility dependencies for writing unit and integration tests.
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams-test-utils</artifactId>
</dependency>
<dependency>
<groupId>org.awaitility</groupId>
<artifactId>awaitility</artifactId>
</dependency>3.2. Configuration
The @EnableKafkaStreams annotation is used to autoconfigure and enable the Kafka stream’s default components. The default config class KafkaStreamsDefaultConfiguration is automatically imported when using the EnableKafkaStreams annotation. This class registers a StreamsBuilderFactoryBean using KafkaStreamsConfiguration class.
@Configuration
@EnableKafkaStreams
public class StreamsConfig {
}The KafkaStreamsConfiguration connects to the provided bootstrap servers specified by the spring.kafka.streams.bootstrap-servers property. We also need to specify application-id that acts as a consumer group name for the stream.
spring:
kafka:
streams:
bootstrap-servers: localhost:9092
application-id: order-streams-app4. Kafka Streams in Action
4.1. Prerequisites
The following docker-compose.yml creates a single-node Kafka server with 1 zookeeper and 1 broker instance. The configuration also ensures that the Zookeeper server always starts before the Kafka server (broker) and stops after it.
If a more resilient Kafka setup is needed, then we can use the following docker cluster configuration using Docker Compose. We can change the configurations based on the specific requirements.
---
version: '3.6'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
platform: linux/amd64
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-server:latest
platform: linux/amd64
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'4.2. Topology Design
Spring Boot offers a lightweight abstraction over the Streams API and manages the lifecycle of our KStream instance. It handles the creation and configuration of the necessary components for the topology and executes our Streams application. This allows us to concentrate on our primary business logic, while Spring effectively handles the lifecycle management.
Now let’s build the topology to count the total number of orders sold for a given product.
In our example, we’ve used the high-level DSL to define the transformations:
- At first, we create a KStream from the input topic using the specified key and value SerDes (Apache Kafka provides a Serde interface, which is a wrapper for the serializer and deserializer of a data type. Kafka provides an implementation for several common data types such as String, Long, Json etc. In our code, we have used String and Json Serdes for key and Value respectively).
- We used selectKey(..) to set a new key for each input record. Then using print(..) and Printed(..) method print the KStream data in the logs with the specified label.
- Then, we create a KTable by transforming, grouping, and then counting the data.
- Finally, we produce the result to an output stream (Kafka Topic).
@Component
@Slf4j
public class OrdersTopology {
@Autowired
public void process(StreamsBuilder streamsBuilder) {
KStream<String, Order> orderStreams = streamsBuilder
.stream(ORDERS,
Consumed.with(Serdes.String(), new JsonSerde<>(Order.class))
)
.selectKey((key, value) -> value.productId());
orderStreams
.print(Printed.<String, Order>toSysOut().withLabel("orders"));
KTable<String, Long> ordersCount = ordersStream
.map((key, order) -> KeyValue.pair(order.productId(), order))
.groupByKey(Grouped.with(Serdes.String(), new JsonSerde<>(Order.class)))
.count(Named.as(OrdersTopology.ORDERS_COUNT));
ordersCount
.toStream()
.print(Printed.<String,Long>toSysOut().withLabel(OrdersTopology.ORDERS_COUNT));
ordersCount
.toStream()
.to(ORDERS_OUTPUT, Produced.with(Serdes.String(), Serdes.Long()));
}
//...
}Here, we’ve annotated the method with @Autowired annotation to inject a matching bean from the container into the StreamsBuilder parameter.
4.3. State Store
Optionally, Instead of publishing the data to an output Kafka topic, we can materialize the result into a StateStore which allows us to query and fetch data more effectively instead of writing a consumer code for the output topic. We can either provide a custom StateStore or use the default RocksDB by providing just a store name.
RocksDB is an embedded state store meaning writes do not entail a network call. This removes latency and ensures it does not become a bottleneck in the stream processing, which means this is not a potential failure point that would need to be catered for. It is a key/value store, with records persisted as their byte representation resulting in fast reads and writes. It is a persistent rather than in-memory state store with writes being flushed to disk asynchronously.
In our case, we will use RocksDB to store the result. So let’s modify the KTable from earlier and materialize the aggregated order count as a local state store.
@Autowired
public void process(StreamsBuilder streamsBuilder) {
//...
KTable<String, Long> ordersCount = ordersStream
.map((key, order) -> KeyValue.pair(order.productId(), order))
.groupByKey(Grouped.with(Serdes.String(), new JsonSerde<>(Order.class)))
.count(Named.as(OrdersTopology.ORDERS_COUNT),
Materialized.as(OrdersTopology.ORDERS_COUNT)
);
//...
}Using StateStore, allows us to write REST API to fetch the data as shown below easily:
@Autowired
private StreamsBuilderFactoryBean streamsBuilderFactoryBean;
@GetMapping("/count")
public List<OrdersCountPerStoreDTO> ordersCount() {
ReadOnlyKeyValueStore<String, Long> ordersStoreData = streamsBuilderFactoryBean.getKafkaStreams()
.store(StoreQueryParameters.fromNameAndType(
ORDERS_COUNT,
QueryableStoreTypes.keyValueStore()
));
var orders = ordersStoreData.all();
var spliterator = Spliterators.spliteratorUnknownSize(orders, 0);
return StreamSupport.stream(spliterator, false)
.map(data -> new OrdersCountPerStoreDTO(data.key, data.value))
.collect(Collectors.toList());
}In the controller, we begin by autowiring the StreamsBuilderFactoryBean. This grants us access to the KafkaStreams instance that is managed by the factory bean. Subsequently, we utilize KafkaStreams to fetch the results from the ORDERS_COUNT key/value state store, which is represented by a KTable.
5. Testing
5.1. Unit Test
Let’s write a unit test for our topology using the TopologyTestDriver. This class makes it easier to write tests to verify the behavior of topologies created with StreamsBuilder.
At first, we instantiate StreamsBuilder, then we use it to create a bean of OrdersTopology that has our business logic. Then, using the TopologyTestDriver we simply instantiate the driver by providing a Topology (StreamsBuilder.build()). Then, we use the driver to create an input topic specifically for testing purposes.
class OrdersTopologyTest {
TopologyTestDriver topologyTestDriver = null;
TestInputTopic<String, Order> ordersInputTopic = null;
static String INPUT_TOPIC = ORDERS;
StreamsBuilder streamsBuilder;
OrdersTopology ordersTopology = new OrdersTopology();
@BeforeEach
void setUp() {
streamsBuilder = new StreamsBuilder();
ordersTopology.process(streamsBuilder);
topologyTestDriver = new TopologyTestDriver(streamsBuilder.build());
ordersInputTopic =
topologyTestDriver.
createInputTopic(
INPUT_TOPIC, Serdes.String().serializer(),
new JsonSerde<Order>(Order.class).serializer());
}
@AfterEach
void tearDown() {
topologyTestDriver.close();
}
@Test
void ordersCount() {
ordersInputTopic.pipeKeyValueList(orders());
ReadOnlyKeyValueStore<String, Long> OrdersCountStore = topologyTestDriver.getKeyValueStore(ORDERS_COUNT);
var product1234OrdersCount = OrdersCountStore.get("product_1234");
assertEquals(2, product1234OrdersCount);
var product4567OrdersCount = OrdersCountStore.get("product_4567");
assertEquals(2, product4567OrdersCount);
}
static List<KeyValue<String, Order>> orders(){
// create some orders
}
}5.2. Integration Test
We use EmbeddedKafka and TestPropertySource to set up the environment for the integration test. Additionally, we also use Awaitility for making it easier to test asynchronous code.
@SpringBootTest
@EmbeddedKafka(topics = {ORDERS})
@TestPropertySource(properties = {
"spring.kafka.streams.bootstrap-servers=${spring.embedded.kafka.brokers}",
"spring.kafka.producer.bootstrap-servers=${spring.embedded.kafka.brokers}"
,"spring.kafka.streams.auto-startup=false"
})
@DirtiesContext(classMode = DirtiesContext.ClassMode.AFTER_EACH_TEST_METHOD)
public class OrdersTopologyIntegrationTest {
@Autowired
KafkaTemplate<String, String> kafkaTemplate;
@Autowired
StreamsBuilderFactoryBean streamsBuilderFactoryBean;
@Autowired
ObjectMapper objectMapper;
@Autowired
OrderService orderService;
@BeforeEach
public void setUp() {
streamsBuilderFactoryBean.start();
}
@AfterEach
public void destroy() {
streamsBuilderFactoryBean.getKafkaStreams().close();
streamsBuilderFactoryBean.getKafkaStreams().cleanUp();
}
@Test
void ordersCount() {
publishOrders();
Awaitility.await().atMost(10, SECONDS)
.pollDelay(Duration.ofSeconds(1))
.ignoreExceptions()
.until(() -> orderService.ordersCount().size(), equalTo(1));
var ordersCount = orderService.ordersCount();
assertEquals(1, ordersCount.get(0).count());
}
private void publishOrders() {
orders()
.forEach(order -> {
String orderJSON = null;
try {
orderJSON = objectMapper.writeValueAsString(order.value);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
kafkaTemplate.send(ORDERS, order.key, orderJSON);
});
}
static List<KeyValue<String, Order>> orders() {
// create some orders
}
}6. Conclusion
In conclusion, we learned about the key concepts of Kafka Streams, such as processor topology and the different types of processors involved in the stream processing pipeline. The article also provided a step-by-step guide on setting up Kafka Streams in a Spring Boot application, including the necessary dependencies and configuration.
Happy Learning !!
Comments