
BeautifulSoup is a popular Python library for scraping the web and processing XML and HTML documents. It is a tool for scraping and retrieving data from websites. BeautifulSoup eases the procedure of extracting specified elements, content, and attributes easily from a specified webpage.
By the end of this article, we will have a good understanding of the basics of BeautifulSoup. We will learn about installing BeautifulSoup, problems after installation, extracting different kinds of data elements, and the challenges in data extraction.
1. Introduction to Web Scraping and BeautifulSoup
1.1. What is Web Scraping?
Web scraping refers to the automated extraction of data from websites. This involves visiting web pages, retrieving their content, and extracting specific data out of the HTML structure of such pages using scripts or tools.
The script makes HTTP requests on the intended website’s server in the website scraping procedure, seeking the HTML content of a specific page or collection of pages. After obtaining the HTML content, the scraper interprets and navigates over the structure of the document in order to find the needed data, which includes text, links, images, and tables.
This collected information can be saved in an organized format, such as a database, or CSV file for later study or use.
1.2. How does BeautifulSoup help in Web Scraping?
BeautifulSoup4 has a number of useful features that make web scraping more efficient and accessible.
Some features of BeautifulSoup are listed below:
- HTML and XML Parsing: In order to handle many kinds of structured information, BeautifulSoup is able to parse both XML and HTML documents.
- Search and Filter: Tags can be searched for and filtered using a variety of techniques, including CSS selectors, regular expressions, and customized filtering methods.
- Encoding Detection: It is simpler to work with various character encodings thanks to Beautiful Soup, which automatically recognizes the document’s source encoding & converts it to Unicode.
- Robust Error Handling: The library is made to gracefully handle HTML/XML documents that are poorly structured or otherwise faulty, which might happen when crawling real-world websites.
- Beautifies the output: The output of a document can be improved by using a library by structuring it with appropriate indentation, which will make it easier to read.
- Cross-Version Support: Python versions are compatible with one another thanks to the functionality of Beautiful Soup on both Python 3 and Python 2.
- Coordination with Other Libraries: Other libraries, such as requests for retrieving websites and lxml for handling and parsing XML documents, can be used with Beautiful Soup.
2. Beautiful Soup Cheat Sheet
Let us prepare a cheat sheet for quick reference to the usage of these functions.
Note that
classis a reserved word in Python that cannot be used as a variable or argument name. So BeautifulSoup adds an underscore for class selectors.Alternatively, you can enclose
classin quotes.
2.1. Make soup
Install beautifulsoup4 library and lxml parser.
pip install beautifulsoup4
pip install lxmlLoading an HTML Document from the Local system.
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"))
soup = BeautifulSoup("<html>data</html>")Loading a remote URL.
import requests
url = "http://books.toscrape.com/"
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
print("Failed to retrieve the webpage. Status code:", response.status_code)
soup = BeautifulSoup(html_content, 'lxml')2.2. The find() and findAll() Methods
The methods to use are:
find_all(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)| Command | Description |
|---|---|
| soup.find(“p”) soup.find(“header”) | Find element(s) by tag name |
| soup.find(id=”unique_id”) | Find an element by its ID. |
| soup.find(‘div’, id=”unique_id”) soup.find(‘div’, {‘id’:’unique_id’}) | Find a DIV Element element by its ID. |
| soup.find_all(class_=”class_name”) | Find the first 3 elements containing the text “Example” |
| soup.find_all(a, class_=”class_name”) soup.find_all(a, {‘class’:’class_name’}) | Find all anchor elements with the CSS class name. |
| soup.find_all(string=”text”) | Find all elements elements containing the text. |
| soup.find_all(text=”Example”, limit=3) | Find first 3 elements containing the text “Example” |
| soup.find_all(“a”)[“href”] | Get the ‘href’ attribute of the ‘anchor’ tags |
2.3. Using Regex Patterns
| Command | Description |
|---|---|
| soup.find_all(string=pattern) soup.find_all(text=re.compile(pattern)) | Searches for elements containing text matching the given pattern. |
| soup.find_all(attrs={‘attribute’: re.compile(pattern)}) | Searches for elements with attribute values matching the pattern. |
| soup.select(‘tag:contains(pattern)’) | Uses the :contains pseudo-class to select elements by tag names containing specific text. |
2.4. Using CSS Selectors
| Command | Description |
|---|---|
| soup.select(‘element’) | Selects all elements with the specified tag name. |
| soup.select(‘.class’) | Selects all elements with the specified class. |
| soup.select(‘#id’) | Selects the element with the specified ID. |
| soup.select(‘element.class’) soup.select(‘element#id’) | Selects elements with a specific tag, ID, or class. |
| soup.select(‘element.class1.class2’) | Selects elements with specified multiple classes. |
| soup.select(‘element[attribute=”value”]’) | Selects elements with a specified attribute name and value. |
| soup.select(“p nth-of-type(3)”) | Selects the third <p> element. |
| soup.select(“p > a:nth-of-type(2)”) | Selects the second <a> element that is a direct child of a <p> element. |
| soup.select(“#link1 ~ .sister”) | Selects all elements with the class sister that are siblings to the element with ID ‘link1’. |
2.5. Navigation
| Command | Description |
|---|---|
| element.find_next(tag) | Find and return the first occurrence of the tag AFTER the current element. |
| element.find_all_next(tag) | Find and return a list of all occurrences of a tag AFTER the current element. |
| element.find_previous(tag) | Find and return the first occurrence of the tag BEFORE the current element. |
| element.find_all_previous(tag) | Find and return the first occurrence of the tag BEFORE the current element. |
| element.find_parent(tag) | Find and return the first occurrence of the tag in the parent elements. |
| element.find_all_parents(tag) | Find and return a list of all occurrences of the tag in the parent elements. |
If you wish to deep dive into individual tasks in detail, keep reading.
3. Setting up Beautiful Soup
3.1. Installing BeautifulSoup4
BeautifulSoup isn’t an inbuilt module of the Python distribution, thus we must install it before using it. We’re going to use a BeautifulSoup4 package (also referred to as bs4).
Installing on Linux Machine
Run the following command for installing bs4 on Linux utilizing the system packages manager-
sudo apt-get install python-bs4 (for python 2.x)
//or
sudo apt-get install python3-bs4 (for python 3.x)You can also install bs4 with pip or easy_install if installing with system packager fails.
easy_install beautifulsoup4
//or
pip install beautifulsoup4Installing on Windows Machine
Beautifulsoup4 installation on the Windows machine is easy, which is done using the command given below-
pip install beautifulsoup4
3.2. Installing a Parser
Note that BeautifulSoup is a high-level interface for parsing and navigating HTML and XML documents. It cannot parse the documents and relies on external parsers to do the actual parsing of the document’s structure.
Although Python’s standard library’s built-in ‘HTML parser‘ is supported by BeautifulSoup by default, it also works with numerous other independent third-party Python parsers, such as the lxml parser and the html5lib parser.
Use the command given below to install the html5lib or lxml parser:
On Linux Machine
apt-get install python-lxml
apt-get insall python-html5libOn Windows Machine
pip install lxml
pip install html5lib
The lxml is generally better at parsing “messy” or malformed HTML code. It is forgiving and fixes problems like unclosed tags, tags that are improperly nested, and missing head or body tags.
Although lxml is slightly faster than html.parser, a good web scraping code generally focuses on robust and easily readable implementations, rather than clever processing optimizations that can easily dwarfed by network latency.
Like lxml, the html5lib is an also extremely forgiving parser that takes even more initiative in correcting broken HTML.
4. Load and Parse a Webpage to Beautiful Soup and Requests Modules
To scrape a webpage, we must first retrieve it from its host server as an HTML or XML string, and then we can parse its content.
For example, we can use Python’s requests library to fetch the HTML content of a web page. Make sure to install requests if we haven’t already:
import requests
url = "http://books.toscrape.com/"
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
print("Failed to retrieve the webpage. Status code:", response.status_code)Now, we can run various commands to exact data from the parsed text. For this demo, we will use the website (http://books.toscrape.com/) for scraping purposes.
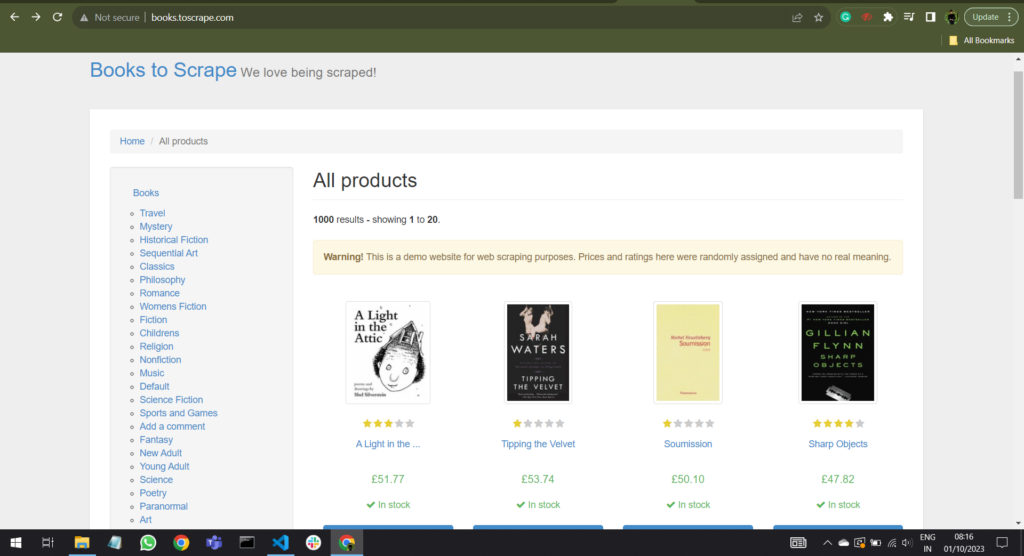
Now we have the HTML content of the webpage, we can create a BeautifulSoup object with a parser:
import requests
from bs4 import BeautifulSoup
url = "http://books.toscrape.com/"
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
else:
print("Failed to retrieve the webpage. Status code:", response.status_code)
soup = BeautifulSoup(html_content, 'lxml')
print(soup.h1)
print(soup.h1.text)
print(soup.h1.string)The program outputs only the first instance of the h1 tag found on the page.
<h1>All products</h1>
All products
All productsNote that there can be multiple paths to reach to a node in HTML structure using bs4. In fact, any of the following function calls would produce the same output:
print(soup.html.body.h1)
print(soup.body.h1)
print(soup.html.h1)5. The Basics of WebScrapping with BeautifulSoup
5.1. The find() and findAll() Methods
At the center of web scrapping using BeautifulSoup, we have two methods find() and findAll() methods that locate and extract specific HTML elements from a parsed HTML document. These methods make it easy to navigate and manipulate HTML data in Python.
- The
find()method locates and retrieves the first occurrence of a specific HTML element that matches the specified criteria by the element’s name (tag), attributes, text content, or a combination of these. It returns a single element, orNoneif no matching element is found. - The
findAll()method finds and returns a list of all occurrences of a specific HTML element that match the provided criteria as above. It returns a list of matching elements, or an empty list if no elements are found.
find_all(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)Let’s take an example.
from bs4 import BeautifulSoup
html = """
<p class='my-class'>Hello, world!</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
"""
soup = BeautifulSoup(html, 'html.parser')
element = soup.find('p', class_='my-class')
print(element.text) # Prints "Hello, world!"
items = soup.find_all('li')
for item in items:
print(item.text) # Prints "Item 1" "Item 2" "Item 3"
5.2. Using CSS Selectors for Fine-grained Extraction
CSS selectors are patterns that specify which elements on a page should be selected based on their attributes and relationships. We can use the select and select_one methods to apply CSS selectors and retrieve elements that match the selector.
- ‘
select‘ method returns a list of all elements that match the CSS selector. If no elements match the selector, an empty list is returned. - ‘
select_one‘ method returns the first element that matches the CSS selector. If no elements match the selector,Noneis returned.
We can use these methods to collect data from elements that might be difficult to reach using normal methods.
elements = soup.select_one(selector)For example, to fetch data from the element with the selector “div.col-sm-6.product_main > h1“, we will use the code given below.
selector = "div.col-sm-6.product_main > h1"
element = soup.select_one(selector)
element_text=element.text
if element:
print("Element Text:", element_text)
else:
print("Element not found on the page.")The program output:
Element Text: A Light in the Attic5.3. Using Regular Expressions
Regular expressions (regex) are strong tools for filtering through text for data patterns. BeautifulSoup mainly works with structured HTML, but when combined with regex, it can improve the collection of data from element content.
Let’s understand this with an example given below-
import re
pattern = re.compile(r"(\d{3})-\d{3}-\d{4}")
phone_numbers = soup.find_all(text=pattern)The regex pattern(\d{3})-\d{3}-\d{4}) given above in the code is looking for phone numbers in the format “###-###-####”, where each “#” represents a digit. So after running this code, we will have the list of phone numbers that are there on the HTML page.
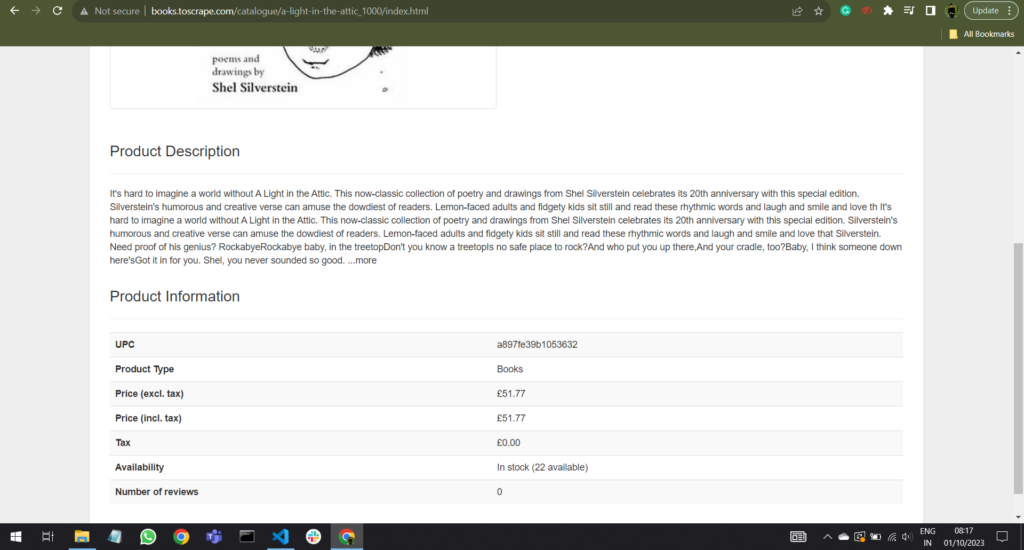
Now suppose we want to see all the prices that were there on this webpage, so we will use the code given below.
pattern = re.compile(r"£\d+\.\d{2}")
prices = soup.find_all(text=pattern)
if prices:
for price in prices:
print("Price:",price)
else:
print("Element not found on the page.")This code fetches a web page, parses its HTML content, and extracts and prints all prices in the format “£XX.XX” using a regular expression pattern.
Price: £51.77
Price: £51.77
Price: £51.77
Price: £0.006. Web Scrapping in Action
Let us see a few examples of the above-discussed commands and understand them in runtime.
6.1. Find All Headings
We can find all the headings in an HTML document by the following code.
soup = BeautifulSoup(html_content, 'lxml')
headings = soup.find_all(['h1','h2','h3','h4','h5','h6'])
# Iterate over the headings and print their text
for heading in headings:
print(heading.text)6.2. Scraping Tables and Structured Data
The navigation and data extraction capabilities of BeautifulSoup are still quite useful when working with data that is structured, like tables. To carefully extract table data, we can focus on particular cells and rows.
Let’s understand the syntax and process with an example:
table = soup.find("table")
for row in table.find_all("tr"):
cells = row.find_all("td")
for cell in cells:
print(cell.text)The code given above will find out the HTML table, after that, it will iterate over each and every row and its cells. After extracting the content from each cell, it will print that onto the console.
Let’s take an example to understand this in a better way:
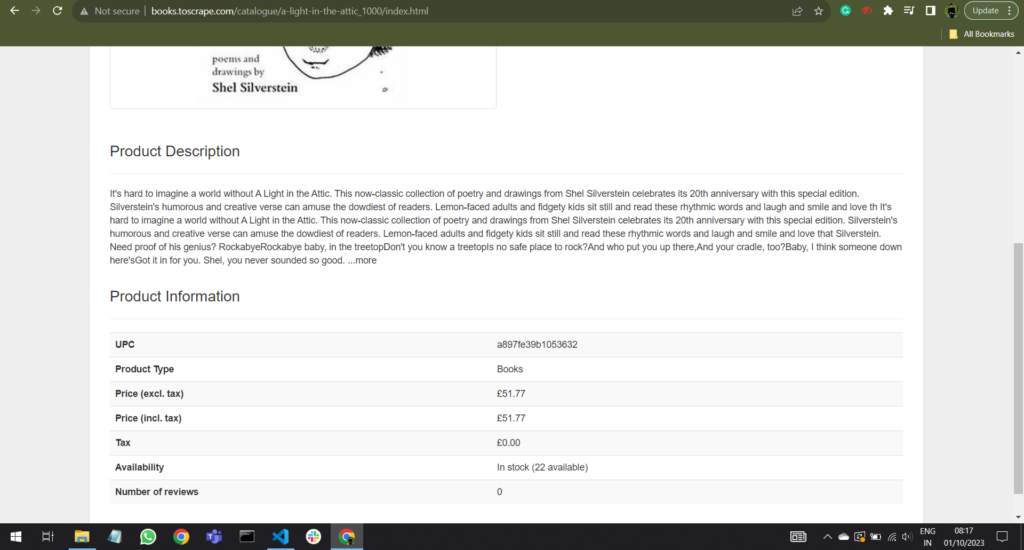
Now suppose we want to extract the data of “Product Information” table, so we will use the the code given below:
table = soup.find("table")
if table:
for row in table.find_all("tr"):
cells = row.find_all("th")
cells += row.find_all("td")
for cell in cells:
print(cell.text)
else:
print("Table not found on the page.")The program output:
UPC
a897fe39b1053632
Product Type
Books
Price (excl. tax)
£51.77
...6.3. Scraping Images and Media Files
Even though BeautifulSoup is mainly meant for interpreting HTML, we are still able to extract data from media assets like photos.
Let’s take another example to understand this in a more clear way.
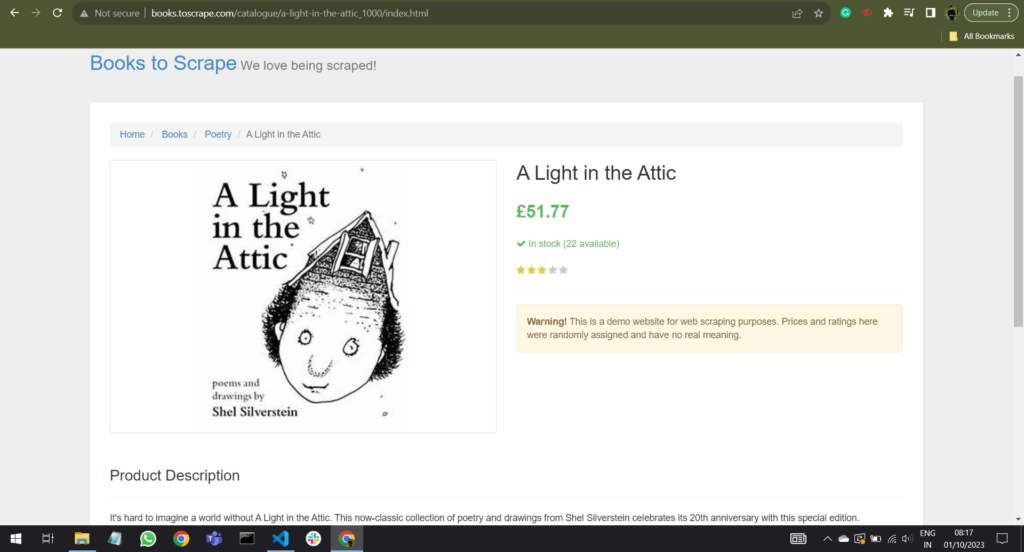
Now suppose we want to download this book cover image into our local disk, so we will use the code given below:
from bs4 import BeautifulSoup
import requests
import os
from urllib.parse import urljoin # Import the urljoin function
# Define the URL of the web page you want to scrape
base_url = "http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html"
url = base_url
# Send an HTTP GET request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
html_content = response.content
else:
print("Failed to retrieve the web page. Status code:", response.status_code)
exit()
# Create a BeautifulSoup object to parse the HTML content
soup = BeautifulSoup(html_content, 'html.parser')
image_tags = soup.find_all("img")
if image_tags:
for img in image_tags:
img_url_relative = img.get("src")
# Construct the complete URL by joining the relative path with the base URL
img_url_absolute = urljoin(base_url, img_url_relative)
img_response = requests.get(img_url_absolute)
if img_response.status_code == 200:
# Generate a unique filename based on the image URL
img_filename = os.path.basename(img_url_absolute)
with open(img_filename, 'wb') as fp:
fp.write(img_response.content)
print(f"Image '{img_filename}' downloaded and saved.")
else:
print("Failed to download image from URL:", img_url_absolute)
else:
print("No image tags found on the page.")
This code extracts the relative URL of this image and combines it with the base URL to create a complete image URL. After sending HTTP requests to these URL, it checks if the response has a status code of 200 (indicating success).
If successful, it saves the image to the local directory with a unique filename and prints a message for the downloaded image. If an image fails to download, it prints an error message. If there is no image tag on the web page, it displays a message indicating so. This code is designed to scrape and download images from a web page for further use.
Output:
Image 'fe72f0532301ec28892ae79a629a293c.jpg' downloaded and saved.6.4. Handling Missing Elements and Errors
The elements that we are searching for while scraping can sometimes not be there. To solve this, we may apply conditional statements or return the result of the find() method to prevent errors.
element = soup.find("text")
if element:
print(element.text)
else:
print("Element not found")7. Challenges in Data Extraction
Now let us discuss some common challenges that are often seen while web scraping.
7.1. Websites with JavaScript and Dynamic Content
Data extraction from websites with dynamic content can be tricky because these sites often use JavaScript to load and update information. The fact that BeautifulSoup doesn’t understand JavaScript, creates a barrier for standard web scraping.
Asynchronous requests, where data is loaded after the initial page load, can complicate data capture. Additionally, navigating complex web structures and handling tasks like authentication, CAPTCHAs, and rate limiting pose challenges. Websites may frequently change their layout, requiring constant updates to scraping scripts. Legal and ethical concerns also come into play, as scraping dynamic sites may violate terms of service and copyright laws.
To address this challenge, various solutions and libraries are available.
For example, Headless browsers like Selenium or Puppeteer can render JavaScript-driven content and interact with web pages. They are helpful when standard HTML parsing is not sufficient. We can also use Selenium to explicitly wait and handle content that loads dynamically after the initial page load.
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "my_element")))
data = element.text
7.2. Handling Pagination and Infinite Scrolling
Imagine a long list of items on a webpage. Pagination means there are multiple pages of items, and you need to go from page to page to get all the data. Infinite scrolling means new items keep appearing as you scroll down, and you must keep scrolling to collect everything. It’s like trying to collect all the candies from a conveyor belt that keeps moving.
Traditional web scraping tools may not be good at this. To handle this, you need custom-made tools that understand how the website works. These tools can mimic your scrolling and flipping through pages. They also make sure you don’t collect the same candy twice.
To address this challenge, various solutions and libraries are available such as Scrappy, Selenium, etc.
import requests
from bs4 import BeautifulSoup
url = "https://example.com/api/data"
headers = {"User-Agent": "BrowserAgent"}
params = {"param1": "value1", "param2": "value2"}
response = requests.get(url, headers=headers, params=params)
if response.status_code == 200:
# If the response is JSON, parse it directly
data = response.json()
# If the response is HTML, parse it with BeautifulSoup
soup = BeautifulSoup(data, 'html.parser')
# Now, you can navigate and extract data from 'soup'
7.3. Websites Behind Authentication
Extracting data from websites that require user authentication presents various hurdles. Firstly, gaining entry to the content necessitates the management of user authentication, involving the submission of login details such as usernames and passwords. This can be a complex process to automate securely. After successful authentication, it becomes essential to maintain session states and handle cookies for accessing protected areas of the website.
Additionally, challenges such as rate limiting, CAPTCHA tests or multi-factor authentication (MFA) methods may need to be addressed, adding layers of complexity. Furthermore, the structure of authenticated pages often differs significantly from publicly accessible pages, necessitating adjustments in scraping scripts.
Lastly, it is crucial to consider the legal and ethical aspects, as scraping authenticated websites can potentially breach terms of service or privacy regulations. Hence, careful compliance and ethical data usage practices are required.
To address this challenge, we can use requests library in Python for managing authentication, session control, and cookie persistence.
import requests
url = 'https://example.com/login'
payload = {'username': 'your_username', 'password': 'your_password'}
# Perform authentication
session = requests.Session()
response = session.post(url, data=payload)
if response.status_code == 200:
# You are now authenticated and can make requests as an authenticated user
7.4. Handling Rate-limiting
In order to avoid receiving too many requests coming from just one IP address, websites frequently use rate-limiting techniques. Dealing with rate-limiting when gathering data is a bit like being in a buffet where you can only take one plate of food at a time and have to wait a bit before getting more. Similarly, some websites slow down how quickly you can collect data from them to avoid problems.
You need to collect data slowly, take breaks when necessary, and be considerate of the website’s resources. This might mean waiting a bit between data requests and keeping an eye out for any signs that you’re collecting data too quickly. It’s all about finding the right pace for getting the data you want without causing any issues.
We can use the time.sleep() function to introduce delays between your requests. This is a simple way to ensure you don’t exceed the allowed request rate.
import requests
import time
max_retries = 3
retry_delay = 5 # Wait for 5 seconds between retries
for _ in range(max_retries):
response = requests.get('https://example.com')
if response.status_code == 200:
# Process the response
elif response.status_code == 429:
time.sleep(retry_delay)
else:
break # Exit the loop on other status codes
8. Ethical Considerations
8.1. Understanding Website’s Terms of Service
It is essential to read and understand all terms of the service or conditions of usage of any web page prior to scraping it. Though some websites’ agreements explicitly discourage scraping, others may have particular recommendations or limitations. Always follow these rules to ensure good behavior.
8.2. Robots.txt and Respecting Website Permissions
Robots.txt files are commonly used by websites to interact with web crawlers as well as indicate certain areas of the website that are prohibited from being crawled and scraped. It’s crucial to review a site’s robots.txt file prior to scraping it. Respect towards the website’s wishes is shown by following the robots.txt permitted guidelines.
8.3. Crawler Politeness and Avoiding Excessive Requests
Crawler respect involves sending acceptable requests in order to avoid stressing a site’s server. The performance of the website may suffer if there are excessive requests sent to the website’s server in just a short amount of time. If you want to make sure that the scraping activities are not annoying use strategies like delaying and throttling.
8.4. Data Privacy and User Consent
Be aware of security considerations while scraping websites with input from users. Make sure you are not breaking any privacy rules and avoid collecting personal information prior to the appropriate consent. The ethical practice of web scraping must always respect the confidentiality of data.
8.5. Sending Your Name and Email in Request Headers
If any problems emerge as a result of your scraping activities, website managers will be able to identify you as well as contact you once you include both your email address and name in the request’s header. This openness encourages web scraping that is ethical and acceptable.
9. FAQs
9.1. ImportError “No module named HTMLParser“
On Windows, you may experience the errors given below-
- ImportError “No module named HTMLParser”– this error means you are executing the Python 2 release of that code under Python 3.
- ImportError “No module named html.parser”– this error means you are executing the Python 3 release of that code under Python 2.
The only approach to resolve the above two issues is to reinstall BeautifulSoup, and totally uninstalling the previous installation.
9.2. Invalid Syntax: ROOT_TAG_NAME = u'[document]’
If you’re receiving the SyntaxError i.e “Invalid syntax” on the line that says ROOT_TAG_NAME = u'[document]’, you’ll have to change the Python 2 code to Python 3, which is as simple as downloading the package python3.
python3 setup.py install
or run Python’s 2 to 3 conversion code in the bs4 directory by using-
2to3-3.2 -w bs410. Conclusion
We have developed a solid basis in the fundamentals of data extraction from our experience with web scraping. To parse and extract data in an efficient manner, we have used BeautifulSoup and CSS selectors. Considering the nuances of ethics, such as watching robots.txt, adhering to website agreements, and protecting data privacy has highlighted the ethical application of this technology. Web scraping’s future will be characterized by creativity, technology, and ethical data handling.
Web scraping will be crucial in gaining insights from the huge digital ecosystem as technology develops while adjusting to the difficulties posed by changing web technologies and rules and regulations.
Happy Learning !!