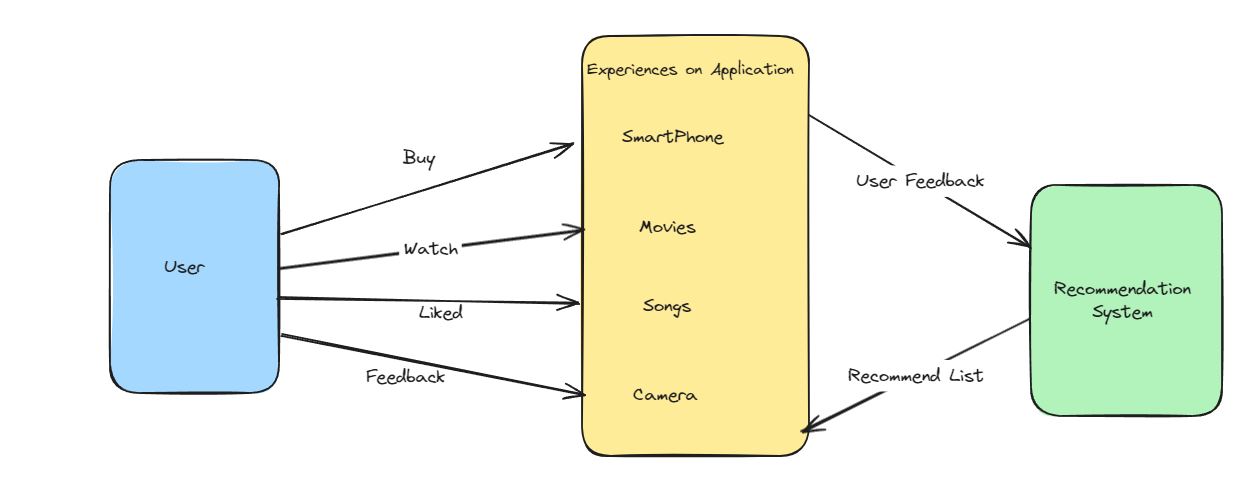
In the digital age, recommendation systems have become an integral part of our online experience. From e-commerce platforms like Amazon to streaming services like Netflix and music apps like Spotify, these systems play a crucial role in helping users discover new content, products, and services tailored to their preferences.
In practice, recommendation systems predict your interest in an item to keep you on the site and prevent you from moving to a competitor’s product. Almost every mid to large-sized organization, that sells products in online channels, uses some type of automated system to make product suggestions to customers. And there is a high demand for experts who can oversee this process.
In this article, we will explore the fascinating world of recommendation systems and learn the following:
1. What is a Recommendation System?
Recommendation systems, frequently known as recommender systems, encompass a spectrum of algorithms and methodologies employed to predict and show the items that a user may want to consume. These items could range from movies, music, books, news, and products to virtually any kind of content or services available online.
This predictive capability is based on users’ historical behavior, expressed preferences, or distinctive characteristics. The primary goal of a recommendation system is to personalize the user experience, enhance user interaction, and improve the relevance of content for each user, by discerning and anticipating individual consumers’ preferences.
2. Types of Recommendation Systems
Most of the recommendation algorithms and techniques fall into three categories discussed below.
2.1. Content-Based Recommendation
Content-based recommendation systems suggest items similar to those the user has interacted with in the past. These systems analyze the attributes or features of items and recommend others with similar characteristics.
For instance, if a user watches a lot of action movies on a streaming platform, a content-based system might recommend more action movies.
2.2 Collaborative Filtering
Collaborative filtering is based on the idea that users who agreed in the past tend to agree again in the future. It can be further divided into two categories:
- User-Item Filtering: This approach recommends items to a user that similar users have liked. For example, if User A and User B have both liked a set of movies, the system might recommend a new movie to User A that User B has enjoyed.
- Item-Item Filtering: This approach recommends items similar to the items a user has already liked. It identifies patterns where items that were liked by the same user are often similar. For example, if a user liked Movie X, they might be recommended Movie Y, which is frequently liked by those who also liked Movie X.
2.3. Hybrid Recommendation Systems
Hybrid recommendation systems combine multiple recommendation techniques to provide more accurate and diverse recommendations. For example, they might combine content-based and collaborative filtering to offer a holistic recommendation experience.
3. Commonly used Algorithms for Recommendation Systems
Several machine learning algorithms are used to power recommendation systems. Here are some of the most common ones:
- Matrix Factorization: This algorithm decomposes the user-item interaction matrix into two lower-dimensional matrices, capturing latent factors (hidden features) that can be used for recommendations. Singular Value Decomposition (SVD) and Alternating Least Squares (ALS) are popular matrix factorization techniques for collaborative filtering.
- k-Nearest Neighbors (k-NN): The k-NN algorithm calculates recommendations by finding items that are similar to those the user has interacted with. It’s simple but effective for both user-based and item-based collaborative filtering.
- Neural Collaborative Filtering (NCF): NCF combines neural networks with collaborative filtering techniques to learn complex user-item interactions. It has been successful in recommendation systems for e-commerce and streaming platforms.
- Deep Learning Models: Deep learning models like Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and Transformer-based models are increasingly used in recommendation systems for their ability to capture complex patterns in user behavior.
4. Data Preparation for a Recommendation Engine
A recommendation engine operates at the intersection of data and machine learning technology, where the quality and quantity of data play a pivotal role. Data serves as the foundation upon which patterns are discerned. The more comprehensive the dataset is, the more adept the recommendation engine becomes at generating pertinent and revenue-generating suggestions.
The data preparation of a recommendation engine typically involves a systematic four-step process:
Step 1: Data Collection
The initial and paramount phase in constructing a recommendation engine is the accumulation of data. Two primary categories of data are essential for effective functioning:
- Implicit Data: encompasses information derived from various activities, including web search history, clicks, cart events, search logs, and order history.
- Explicit Data: pertains to information gleaned directly from customer input, such as reviews, ratings, likes, dislikes, and product comments.
Additionally, customer attribute data, encompassing demographics (age, gender) and psychographics (interests, values), is utilized to identify similar customers. Feature data, such as genre and item type, contribute to identifying product similarities.
Step 2: Data Storage
Once the data is amassed, a robust storage system is indispensable as the volume of data expands over time. The choice of storage depends on the nature of the collected data, ranging from customer interactions to demographic information.
Below are some tools that can be useful for storing large amounts of data.
- Amazon Redshift
- Apache HBase
- Amazon S3 (Simple Storage Service)
- Google Cloud Storage
- Azure Blob Storage
- Hadoop Distributed File System (HDFS)
Step 3: Data Analysis
After data collection, an in-depth analysis is imperative for effective utilization. At this step, we clean and preprocess the data. This might involve handling missing values, normalizing data, or encoding categorical data.
Below are some tools and Libraries that can be useful for data analysis
- Jupyter Notebooks
- Tableau
- Power BI
- RStudio
- NumPy
- Pandas
- Scikit-learn
Step 4: Data Filtering
The conclusive step involves data filtering, where diverse matrices, mathematical rules, and formulas are applied. The choice of filtering is contingent upon whether a collaborative, content-based, or hybrid model recommendation filtering is employed. This filtration process culminates in the generation of tailored recommendations.
Below are some tools and Libraries/Algorithms that can be useful for data filtering
- Microsoft Excel/Google Sheets
- Pandas/NumPy
- Collaborative Filtering
This systematic approach ensures that a recommendation engine optimally utilizes data to deliver personalized and relevant suggestions to users.
5. Demo (Movie Recommendation System)
We are now creating a Movie Recommendation System using the K-Nearest Neighbors Algorithm. It will be a web app created using Python and Flask framework.
5.1. Prerequisites
Before we go deep dive into creating our recommendation system let’s install/set up all the required things to get started. Below is the prerequisite for this project.
- Python 3.7 or later installed on your computer
- Flask installed on your computer
- Python Libraries: NumPy, Pandas, SciPy, SciLearn
Once you all get these then you are good to start with us.
5.2. Movies and Ratings DataSet
In this demo, we are using two files (movies.csv and ratings.csv) as our dataset.
Our movies.csv file contains information using below fields:
- movieId: It contains the id of the movie.
- Title: It contains the title of the movie.
- Genre: It contains the list of genres in which movies fall.
Below are some sample rows from movies.csv
| MovieId | Title | Genre |
| 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
| 5 | Father of the Bride Part II (1995) | Comedy |
Our ratings.csv file contains information using below fields:
- UserId: It contains the user ID of the user who watched the movie.
- movieId: It contains the ID of the movie.
- rating: It contains the rating of the movie provided by the user.
- timestamp: It contains the timestamp of the movie.
Below are some sample rows from ratings.csv
| UserId | MovieId | Ratings | Timestamp |
| 1 | 296 | 5 | 1147880044 |
| 1 | 306 | 3.5 | 1147868817 |
| 2 | 524 | 3.5 | 1141417112 |
| 2 | 553 | 2 | 1141415539 |
| 1 | 8973 | 4 | 1147869211 |
From the above sample rows, you can understand how moviId and UserId are related. Based on this we can create a User-Item Matrix to predict our data.
5.3. Design of the Recommendation System
In this Demo, we are going to build our recommendation system using the k-nearest Neighbors (KNN) algorithm. So let’s understand how this algorithm works.
The k-Nearest Neighbors (KNN) algorithm is a supervised machine learning algorithm used for classification and regression tasks. It doesn’t have a traditional training phase like some other algorithms. Instead, it memorizes the entire training dataset.
KNN works by finding the ‘nearest‘ neighbors of a given point in the feature space. To determine ‘nearness‘, the distance metric used is typically Euclidean distance, but other distance measures such as Manhattan, or cosine similarity can be used based on the nature of the data. When a new, unlabeled data point is given for classification, KNN calculates the distance between that point and every other point in the training dataset.

Then it looks at the class labels of the k-nearest neighbors and assigns the class label that is most common among them. This is done through a majority voting mechanism.
The majority class label obtained from the voting process is assigned as the predicted class label for the new data point and returned to the result of those points, that is how KNN makes decisions.
KNN in movie recommendations faces challenges like scalability (as the number of movies and users grows, the computation becomes more intensive) and sparsity (many users may have rated only a small subset of movies, leading to sparse data). Often, KNN is used in conjunction with other methods, like collaborative filtering or content-based filtering, to enhance the quality of recommendations and overcome some of its inherent limitations.
5.4. Project Structure
Now let’s see what our project structure looks like.
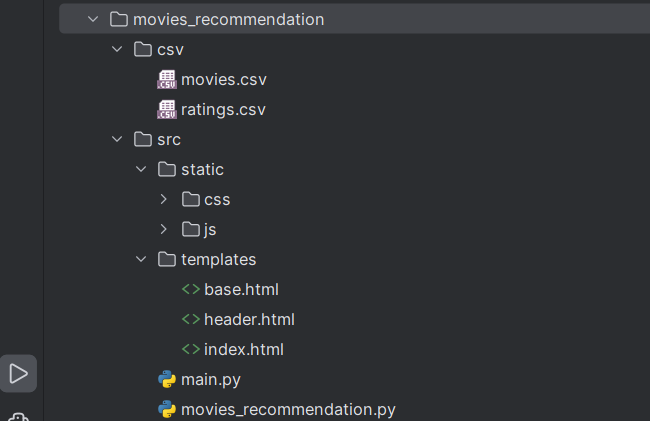
If you have ever worked with Flask then this will be relative to you. However, let’s discuss each of them below.
- /src: This is our main folder which contains our code. You can name it as per your choice.
- /static: This folder contains the all required static files like CSS and JS that are needed to style the app.
- /templates: This Folder contains all the html files that we created for the web app.
- main.py: This is the main Python script that contains the flask config.
- movies_recommendation.py: As the name suggests it contains the main core logic for our recommendation system.
The ‘movies.csv‘ and ‘ratings.csv‘ are our dataset files.
5.5. Code for Recommendation System
Now we have set up all the required things that are needed for our project so let’s get started with our movie recommendation.
Let’s start with the ‘main.py‘ file which starts the flask application and integrates the recommendation engine with UI.
from flask import Flask, render_template, request
import movies_recommendation as m_rx
# initializing the flask app
app = Flask(__name__)
app.secret_key = "secret_key"
# default routing for the app
@app.route("/")
def home():
return render_template('index.html')
@app.route("/recommend", methods=['POST'])
def recommend():
movie_name = request.form['movies']
recommend_movies = m_rx.main_call(movie_name)
return render_template('index.html', recommend_movies=recommend_movies, name=movie_name)
# main function
if __name__ == "__main__":
app.run(debug=True, host='0.0.0.0') # for debugging purpose
# app.run()
Here we have three functions that are described below:
- def home(): This is the entry point of the web app when flask runs it will be called its route with a slash (“/”) and it will render an index.html file on the browser.
- def recommend(): This method calls our main function from movies_recommendation.py by providing the movie_name as the parameter.
- if __name__ == “__main__”: this is the main function and entry point of our main.py. This starts Flask when called.
Let’s move to our main file the ‘movies_recommendation.py‘. It recommends movies based on user ratings data. Here’s a step-by-step analysis of how a movie is recommended to a user:
# importing the libraries
import pandas as pd
import numpy as np
# to create user-item matrix
from scipy.sparse import csr_matrix
# finding nearest ratings using nearest-neighbour algo
from sklearn.neighbors import NearestNeighbors
# importing the data
movies_data = pd.read_csv('../csv/movies.csv')
movies_ratings_data = pd.read_csv('../csv/ratings.csv')
# checking data
rating_length = len(movies_ratings_data)
movies_length = len(movies_data)
unique_movies = len(movies_ratings_data['movieId'].unique())
unique_users = len(movies_ratings_data['userId'].unique())
user_freq = movies_ratings_data[['userId', 'movieId']].groupby('userId').count().reset_index()
user_freq.columns = ['userId', 'n_ratings']
# creating a function to generate user-item matrix
def create_matrix(df):
N = len(df['userId'].unique())
M = len(df['movieId'].unique())
# mapping Ids to indices (means indexing)
user_mapping = dict(zip(np.unique(df['userId']), list(range(N))))
movie_mapping = dict(zip(np.unique(df['movieId']), list(range(M))))
# inverse mapping of user and movie
user_inverse_mapping = dict(zip(list(range(N)), np.unique(df['userId'])))
movie_inverse_mapping = dict(zip(list(range(M)), np.unique(df['movieId'])))
user_index = [user_mapping[i] for i in df['userId']]
movie_index = [movie_mapping[i] for i in df['movieId']]
X = csr_matrix((df['rating'], (movie_index, user_index)), shape=(M, N))
return X, user_mapping, movie_mapping, user_inverse_mapping, movie_inverse_mapping,
# function ends here
# here we are calling create_matrix function
X, user_mapper, movie_mapper, user_inv_mapper, movie_inv_mapper = create_matrix(movies_ratings_data)
# creating function to find similar movies using nearest neighbour algo with cosine metric
def find_similar(movie_id, X, k, metric='cosine', show_distance=False):
neighbour_list = []
movie_ind = movie_mapper[movie_id]
movie_vec = X[movie_ind]
k += 1
kNN = NearestNeighbors(n_neighbors=k, algorithm='brute', metric=metric)
kNN.fit(X)
movie_vec = movie_vec.reshape(1, -1)
neighbour = kNN.kneighbors(movie_vec, return_distance=show_distance)
for i in range(0, k):
n = neighbour.item(i)
neighbour_list.append(movie_inv_mapper[n])
neighbour_list.pop(0)
return neighbour_list
# function ends here
def main_call(titles):
movie_titles = dict(zip(movies_data['movieId'], movies_data['title']))
movie_title = dict(zip(movies_data['title'], movies_data['movieId']))
Id = movie_title[titles]
similar_ids = find_similar(Id, X, k=10)
recommended_movies = []
for i in similar_ids:
recommended_movies.append(movie_titles[i])
return recommended_movies
- We have imported all necessary libraries, including Pandas for data manipulation, NumPy for numerical operations, scipy.sparse for creating a sparse user-item matrix, and NearestNeighbors from scikit-learn for implementing the kNN algorithm along with our dataset files.
- Some basic data exploration is performed, including checking the length of the rating dataset, the number of unique movies and users, and creating a frequency table of user ratings.
- A function create_matrix is defined to generate a sparse user-item matrix. This matrix represents user ratings for movies, with users on X-axis and movies on the Y-axis. KNN uses this matrix to provide results.
- Each row represents a unique user.
- Each column represents a unique movie.
- The cells contain the ratings given by a user to a movie.
- If a user has not rated a movie, that cell would typically be empty or have a default value (like 0 or NaN).
Such a matrix is typically sparse, meaning most of the cells do not have a rating, as it’s unlikely that all users have rated all movies.
| UserID \ MovieID | Movie 1 | Movie 2 | Movie 3 | … | Movie N |
|---|---|---|---|---|---|
| User 1 | 4.0 | NaN | 5.0 | … | 3.0 |
| User 2 | NaN | 3.0 | NaN | … | 4.5 |
| User 3 | 2.5 | 4.0 | NaN | … | NaN |
| … | … | … | … | … | … |
| User M | 3.5 | NaN | 4.0 | … | 5.0 |
- The find_similar is the main function where all work happens. It is created to find similar movies using the kNN algorithm with cosine similarity as the distance metric. It takes a movie ID, the user-item matrix, the number of neighbors to find (k), and the metric as parameters.
- Internally, each movie is represented as a vector, where each element corresponds to a user’s rating for that movie. For instance, the vector for “Movie 1” would be [4.0, NaN, 2.5, …, 3.5] according to the ratings by User 1, User 2, User 3, …, User M.
- To compute the similarity between two movies, we calculate the cosine of the angle between their vectors. For example, to calculate the similarity between “Movie 1” and “Movie 2”, we would use their respective vectors.
- Cosine similarity is particularly effective here as it is less affected by the magnitude of ratings and more by the rating pattern.
- The Nearest Neighbors algorithm will return the top
kmovies that have the highest cosine similarity scores with “Movie 1”. - After processing it stores the result in the neighbour_list array which is returned to the main_call function.
- The main_call function takes a movie title as input, retrieves the corresponding movie ID, and calls the find_similar function to find similar movies. It then returns a list of recommended movies based on similarity to display on UI.
5.6. Building the UI
Now our backend part is clear let see how’s our frontend part is. We have the below files.
<!DOCTYPE html>
<html lang="en">
<head>
{% block head %}
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/npm/bulma@0.9.3/css/bulma.min.css"
/>
<link
rel="stylesheet"
href="https://www.jsdelivr.com/package/npm/@creativebulma/bulma-badge"
/>
<!-- -->
<script src="{{url_for('static', filename='js/close.js')}}"></script>
<title>{% block title %}{% endblock %}</title>
{% endblock %}
</head>
<body>
{% block body %} {% endblock %}
</body>
</html>The base.html file contains all basic things like CSS and JS script tags and other important blocks and thanks to this we do not write basic things again and again. We just use this file using Extend in our other HTML files.
{% extends "base.html" %} {% include "header.html" %} {% block title %} Movies
Recommendation | FLASK {% endblock %} {% block body %}
<div>
<div class="level block">
<div class="level-item has-text-centered">
<div class="container mx-6 block">
<form action="/recommend" method="post">
<input
type="text"
class="input is-primary block"
name="movies"
id="movie_recom"
list="suggestion"
placeholder="select a movie from dropdown"
/>
<datalist id="suggestion">
<option value="Toy Story (1995)"></option>
<option value="Jumanji (1995)"></option>
<option value="Grumpier Old Men (1995)"></option>
<option value="Nixon (1995)"></option>
<option value="Taxi Driver (1976)"></option>
<option value="Spider-Man 2 (2004)"></option>
<option value="I, Robot (2004)"></option>
<option value="X-Men: The Last Stand (2006)"></option>
<option value="Da Vinci Code, The (2006)"></option>
<option value="Superman Returns (2006)"></option>
</datalist>
<button class="button is-info">Submit</button>
</form>
</div>
</div>
</div>
</div>
<div class="columns is-multiline my-6">
{% for row in recommend_movies %}
<div class="column is-3 is-desktop">
<div class="box">{{row}}</div>
</div>
{% endfor %}
</div>
</div>
{% endblock %}
In the index.html file, if you see the data list tag I have provided hard-coded values for the simplicity of our app. However, in real scenarios, input values can be real-time or proceed as per the needs.
5.7. Recommendation System in Action
When a user selects a movie and submits the form, an API endpoint (“/recommend”) is called, which triggers the recommend() function. This function, in turn, calls another function from the movies_recommendation.py file and returns the result. The recommend() function then renders the result on the web page.
Below are some screenshots from our app.


Hope this demo will give basic insight into recommendation systems.
6. Challenges In Recommendation Systems
Building recommendation systems come with a set of challenges, ranging from data sparsity to algorithm complexity. Here are some common challenges and potential solutions:
| Challenge | Problem | Solution |
|---|---|---|
| Cold Start Problem | Recommending items for new users or new items with limited interaction history | For new items, utilize content-based features until there is enough interaction data |
| Scalability | As the user base and item catalog grows, computational demands increase | As the user base and item catalog grows, computational demands increase |
| Dynamic User Preferences | User preferences change over time, and the system needs to adapt | Implement models that continuously update based on real-time user interactions. |
| Bias and Fairness | Recommendations can be biased based on historical data, leading to unfairness | Implement fairness-aware algorithms and metrics |
| Privacy Concerns | Users may be hesitant to share personal data for fear of privacy breaches. | Allow users to control the level of information shared and provide transparent privacy policies. |
| Real-Time Recommendations | Providing timely recommendations as user preferences change. | Use caching and pre-computed recommendations to reduce response times |
7. Conclusion
In this article, we explored the significance of recommendation systems, discussed different recommendation algorithms, and demonstrated how to build a simple movie recommender. The field of recommendation systems is vast and continues to advance in a wide range of industries. As data and AI technologies continue to grow, so too will the capabilities and applications of recommendation systems.
Happy Learning !!