
Batch processing has been around for decades. Earlier, batch processing applications were developed to utilize the offline time to do work aggregated throughout the day. These applications required several features such as transaction support, fast I/O, schedulers such as Quartz, and solid threading support. Spring batch, a batch processing solution for the Spring platform, helps in developing the batching processing applications in a more modular and predictable way.
Batch processing can be applied to different kinds of applications such as loading records from a comma-separated value (CSV) file into a database, nontrivial processing on records in a database, or even resizing images on the file system whose metadata is stored in a database.
1. How does Spring Batch Work?
Spring Batch works with a JobRepository, which is the keeper of all the knowledge and metadata for each job (including component parts such as JobInstances, JobExecution, and StepExecution). Each Job is composed of one or more Steps, one after another. With Spring Batch, a Step can conditionally follow another Step, allowing for primitive workflows. These steps can also be concurrent i.e. executing the two steps can run at the same time.
When a job is run, it’s often coupled with JobParameters to parameterize the behavior of the Job itself. For example, a job might take a date parameter to determine which records to process. This coupling is called a JobInstance.
Each time the same JobInstance (i.e., the same Job and JobParameters) is run, it’s called a JobExecution. This is a runtime context for a version of the Job. Ideally, for every JobInstance there’d be only one JobExecution. However, if there were any errors, the JobInstance should be restarted; the subsequent run would create another JobExecution.
For every step in the original job, there is a StepExecution in the JobExecution, thus forming an object graph.
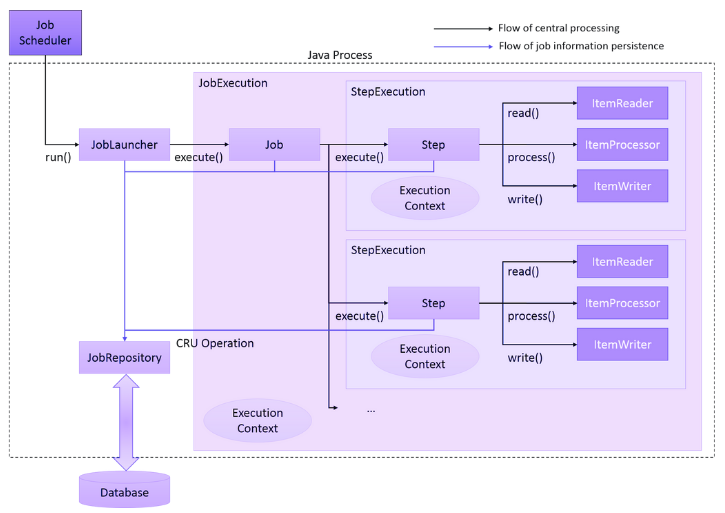
Overall, in a typical batch application, the flow of sequence is:
- JobLauncher is initiated from the job scheduler or any other mechanism. JobLauncher registers JobInstance in the database through JobRepository.
- Job is executed from JobLauncher and registers that Job execution has started through JobRepository.
- Step is executed from Job. It updates miscellaneous information like counts of I/O records and status in the database through JobRepository.
- Step fetches input data by using ItemReader.
- Step processes input data by using ItemProcessor.
- Step outputs processed data by using ItemWriter.
- Finally, JobLauncher registers that Job execution has been completed in the database through JobRepository.
2. Setting Up Spring Batch with Spring Boot
As discussed in the previous section, the JobRepository requires a database which is a persistent data store. We are using H2 (in-memory database) which integrates well with the Spring batch and is good enough for demo purposes. In production applications, it is recommended to use an enterprise database system.
2.1. Maven
Start with including spring-boot-starter-batch dependency which transitively imports the other necessary dependencies.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>Additionally, we need to have a database backend (here, we are using the H2 database). The database is used as a Job repository to store metadata about batch jobs, such as job instances, step executions, and job executions for enabling features like restartability, resilience, and monitoring.
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>2.2. Enabling Batch Processing
When ‘spring-boot-starter-batch‘ is added, Spring boot automatically configures the Spring Batch related beans using BatchAutoConfiguration.java.
The use of @EnableBatchProcessing is discouraged by Spring Batch if we are using Spring Boot 3 because it disables the auto-configuration for Spring Batch.
2.3. Configuring Batch DataSource
2.3.1. The application has a Single DataSource
Spring batch relies on a database to store the job execution details. Spring Batch will use the default DataSource available for initializing its schema, if there is only one datasource available in the application.
2.3.2. The application has Multiple DataSources
If there are multiple datasources, we can annotate the bean method with @BatchDataSource to explicitly define the datasource used by batch processes. Do not forget to mark one datasource bean @Primary to avoid runtime errors.
@Bean(name = "batchDataSource")
@BatchDataSource
public DataSource h2Datasource() {
EmbeddedDatabaseBuilder builder = new EmbeddedDatabaseBuilder();
EmbeddedDatabase embeddedDatabase = builder
.addScript("classpath:org/springframework/batch/core/schema-drop h2.sql")
.addScript("classpath:org/springframework/batch/core/schema-h2.sql")
.setType(EmbeddedDatabaseType.H2)
.build();
return embeddedDatabase;
}
@Bean
@Primary
@ConfigurationProperties("spring.datasource")
public DataSourceProperties oracleDatasourceProperties() {
return new DataSourceProperties();
}
@Bean
@Primary
@ConfigurationProperties("spring.datasource.hikari")
public DataSource datasource() {
return oracleDatasourceProperties()
.initializeDataSourceBuilder()
.type(HikariDataSource.class)
.build();
}2.4. Default Schema Initialization
When using Spring Batch with Spring Boot, schema initialization is done automatically. Spring Boot can detect your database type and execute those scripts on startup. If you use an embedded database, database initialization happens by default.
We can control the default initialization using the following property:
spring.batch.jdbc.initialize-schema=always2.5. Custom Schema Initialization
We can also switch off the default schema initialization (and maintain it yourself) by setting spring.batch.jdbc.initialize-schema to ‘never‘.
spring.batch.jdbc.initialize-schema=neverAnd then explicitly initialize the database using a DataSourceInitializer. For our demo, we will use the DDL for H2: schema-h2.sql.
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
@Configuration
public class BatchConfig {
DataSource dataSource;
public BatchConfig(DataSource dataSource) {
this.dataSource = dataSource;
}
@Bean
public DataSourceTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public DataSourceInitializer databasePopulator() {
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("org/springframework/batch/core/schema-h2.sql")); //use custom schema
populator.addScript(new ClassPathResource("sql/batch-schema.sql"));
populator.setContinueOnError(false);
populator.setIgnoreFailedDrops(false);
DataSourceInitializer dataSourceInitializer = new DataSourceInitializer();
dataSourceInitializer.setDataSource(dataSource);
dataSourceInitializer.setDatabasePopulator(populator);
return dataSourceInitializer;
}
}Additionally, we can include the requirement-specific custom schema files that are necessary to run the batch jobs. In the following configuration, we are adding the ‘batch-schema.sql‘ file which contains the SQL for custom tables needed to complete the job.
DROP TABLE IF EXISTS person;
CREATE TABLE person (
person_id BIGINT AUTO_INCREMENT NOT NULL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
age INTEGER,
is_active BOOLEAN
);3. Demo Setup
For demo purposes, let us create a batch Job that reads the person’s information from a CSV file and saves it into a database. The CSV file looks like this:
Lokesh,Gupta,41,true
Brian,Schultz,42,false
John,Cena,43,true
Albert,Pinto,44,falseTo read a person’s record in Java and process it, we need to create a simple POJO.
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
String firstName;
String lastName;
Integer age;
Boolean active;
}4. Creating a Batch Job
The following is the Spring Batch configuration for a job that reads data from a CSV file, processes it, and writes it to a database.
import com.howtodoinjava.demo.batch.jobs.csvToDb.listener.JobCompletionNotificationListener;
import com.howtodoinjava.demo.batch.jobs.csvToDb.model.Person;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.LineMapper;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.item.file.transform.LineTokenizer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.transaction.PlatformTransactionManager;
import javax.sql.DataSource;
@Configuration
public class CsvToDatabaseJob {
public static final Logger logger = LoggerFactory.getLogger(CsvToDatabaseJob.class);
private static final String INSERT_QUERY = """
insert into person (first_name, last_name, age, is_active)
values (:firstName,:lastName,:age,:active)""";
private final JobRepository jobRepository;
public CsvToDatabaseJob(JobRepository jobRepository) {
this.jobRepository = jobRepository;
}
@Value("classpath:csv/inputData.csv")
private Resource inputFeed;
@Bean
public Job insertIntoDbFromCsvJob(Step step1) {
var name = "Persons Import Job";
var builder = new JobBuilder(name, jobRepository);
return builder.start(step1).listener(new JobCompletionNotificationListener()).build();
}
@Bean
public Step step1(ItemReader<Person> reader,
ItemWriter<Person> writer,
ItemProcessor<Person, Person> processor,
PlatformTransactionManager txManager) {
var name = "INSERT CSV RECORDS To DB Step";
var builder = new StepBuilder(name, jobRepository);
return builder
.<Person, Person>chunk(5, txManager)
.reader(reader)
.writer(writer)
.build();
}
@Bean
public FlatFileItemReader<Person> csvFileReader(
LineMapper<Person> lineMapper) {
var itemReader = new FlatFileItemReader<Person>();
itemReader.setLineMapper(lineMapper);
itemReader.setResource(inputFeed);
return itemReader;
}
@Bean
public DefaultLineMapper<Person> lineMapper(LineTokenizer tokenizer,
FieldSetMapper<Person> mapper) {
var lineMapper = new DefaultLineMapper<Person>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(mapper);
return lineMapper;
}
@Bean
public BeanWrapperFieldSetMapper<Person> fieldSetMapper() {
var fieldSetMapper = new BeanWrapperFieldSetMapper<Person>();
fieldSetMapper.setTargetType(Person.class);
return fieldSetMapper;
}
@Bean
public DelimitedLineTokenizer tokenizer() {
var tokenizer = new DelimitedLineTokenizer();
tokenizer.setDelimiter(",");
tokenizer.setNames("firstName", "lastName", "age", "active");
return tokenizer;
}
@Bean
public JdbcBatchItemWriter<Person> jdbcItemWriter(DataSource dataSource) {
var provider = new BeanPropertyItemSqlParameterSourceProvider<Person>();
var itemWriter = new JdbcBatchItemWriter<Person>();
itemWriter.setDataSource(dataSource);
itemWriter.setSql(INSERT_QUERY);
itemWriter.setItemSqlParameterSourceProvider(provider);
return itemWriter;
}
}Let’s break down the code to understand its components and how the Spring Batch job is configured:
- Spring boot’s autoconfiguration configures a default implementation of JobRepository (the default is SimpleJobRepository which stores information in a database) and injects using the constructor injection.
- The input CSV file is specified using the @Value annotation on the Resource type. On runtime, we can refer it to access the CSV file.
- Then we define the Job and Step beans. The job consists of a single step (
step1). The step includes a chunk-oriented processing mechanism with a specified reader, writer, and transaction manager. - A bean for the FlatFileItemReader is defined. It reads lines from the input CSV file, applying the specified ‘lineMapper‘. The lineMapper is a bean of type DefaultLineMapper that sets the line tokenizer and field set mapper for mapping lines to domain objects (Person).
- The DelimitedLineTokenizer specifies the delimiter and column names for tokenizing lines from the CSV file. The column names are firstName, lastName, age, and active.
- Finally, the JdbcBatchItemWriter bean is defined which writes items (Persons) to the database using the specified SQL query ‘INSERT_QUERY‘ and datasource.
The Step is place where the actual work happens, such as reading input, processing records or writing to database. This is also called Tasklet.
We can provide our own Tasklet implementation or simply use a preconfigured Tasklet created for that specific purpose. For example, we are using FlatFileItemReader and JdbcBatchItemWriter tasklets.
After the job has been finished, a notification is sent to JobCompletionNotificationListener class that implements the JobExecutionListener interface.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
public class JobCompletionNotificationListener implements JobExecutionListener {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("JOB FINISHED !!");
}
}
}5. Running the Job
Now our demo job is configured and ready to be executed. We are using the CommandLineRunner interface to execute the job automatically, with JobLauncher, when the application is fully started.
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ApplicationContext;
@SpringBootApplication
public class BatchProcessingApplication implements CommandLineRunner {
private final JobLauncher jobLauncher;
private final ApplicationContext applicationContext;
public BatchProcessingApplication(JobLauncher jobLauncher, ApplicationContext applicationContext) {
this.jobLauncher = jobLauncher;
this.applicationContext = applicationContext;
}
public static void main(String[] args) {
SpringApplication.run(BatchProcessingApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
Job job = (Job) applicationContext.getBean("insertIntoDbFromCsvJob");
JobParameters jobParameters = new JobParametersBuilder()
.addString("JobID", String.valueOf(System.currentTimeMillis()))
.toJobParameters();
var jobExecution = jobLauncher.run(job, jobParameters);
var batchStatus = jobExecution.getStatus();
while (batchStatus.isRunning()) {
System.out.println("Still running...");
Thread.sleep(5000L);
}
}
}Notice the console logs.
1-28T13:38:57.110+05:30 INFO 21288 --- [main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=Persons Import Job]] launched with the following parameters: [{'JobID':'{value=1701158937062, type=class java.lang.String, identifying=true}'}]
2023-11-28T13:38:57.137+05:30 INFO 21288 --- [main] o.s.batch.core.job.SimpleStepHandler : Executing step: [INSERT CSV RECORDS To DB Step]
2023-11-28T13:38:57.169+05:30 INFO 21288 --- [main] o.s.batch.core.step.AbstractStep : Step: [INSERT CSV RECORDS To DB Step] executed in 32ms
2023-11-28T13:38:57.171+05:30 INFO 21288 --- [main] .j.c.l.JobCompletionNotificationListener : JOB FINISHED !!6. Disable Auto-Run of Batch Jobs on the Application Startup
Spring boot also automatically runs the configured batch jobs when the application starts. This may not be desired in most of the applications.
To disable the auto-run of jobs, we need to use ‘spring.batch.job.enabled‘ property in the application.properties file. When it is set to ‘false‘ (default is ‘true‘), Spring Batch jobs won’t be executed automatically, and we must trigger them manually or conditionally based on the application’s requirements.
spring.batch.job.enabled=false7. Implementing Listeners to check the Job Progress
Sometimes we may want to peek into the progress of the job progress. Spring batch allows us to plugin the listeners into the reader and writer steps. For this purpose, we need to create a class and implement one of the following interfaces:
- ItemReadListener
- ItemProcessListener
- ItemWriteListener
The following is an example implementation of the ItemReadListener interface.
import com.howtodoinjava.demo.batch.jobs.csvToDb.model.Person;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ItemReadListener;
public class PersonItemReadListener implements ItemReadListener<Person> {
public static final Logger logger = LoggerFactory.getLogger(PersonItemReadListener.class);
@Override
public void beforeRead() {
logger.info("Reading a new Person Record");
}
@Override
public void afterRead(Person input) {
logger.info("New Person record read : " + input);
}
@Override
public void onReadError(Exception e) {
logger.error("Error in reading the person record : " + e);
}
}We can add the listener in the job step configuration using the listener() method, as follows:
@Bean
public Step step1(ItemReader<Person> reader,
ItemWriter<Person> writer,
ItemProcessor<Person, Person> processor,
PlatformTransactionManager txManager) {
var name = "INSERT CSV RECORDS To DB Step";
var builder = new StepBuilder(name, jobRepository);
return builder
.<Person, Person>chunk(5, txManager)
.reader(reader)
.listener(new PersonItemReadListener()) //Reader listener
.writer(writer)
.build();
}Run the program and see the logs:
2023-11-28T14:48:40.686+05:30 INFO 23976 --- [main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=Persons Import Job]] launched with the following parameters: [{'JobID':'{value=1701163120629, type=class java.lang.String, identifying=true}'}]
2023-11-28T14:48:40.712+05:30 INFO 23976 --- [main] o.s.batch.core.job.SimpleStepHandler : Executing step: [INSERT CSV RECORDS To DB Step]
2023-11-28T14:48:40.726+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : Reading a new Person Record
2023-11-28T14:48:40.735+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : New Person record read : Person(firstName=Lokesh, lastName=Gupta, age=41, active=true)
2023-11-28T14:48:40.737+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : Reading a new Person Record
2023-11-28T14:48:40.738+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : New Person record read : Person(firstName=Brian, lastName=Schultz, age=42, active=false)
2023-11-28T14:48:40.738+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : Reading a new Person Record
2023-11-28T14:48:40.739+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : New Person record read : Person(firstName=John, lastName=Cena, age=43, active=true)
2023-11-28T14:48:40.739+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : Reading a new Person Record
2023-11-28T14:48:40.739+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : New Person record read : Person(firstName=Albert, lastName=Pinto, age=44, active=false)
2023-11-28T14:48:40.739+05:30 INFO 23976 --- [main] c.h.d.b.j.c.l.PersonItemReadListener : Reading a new Person Record
2023-11-28T14:48:40.746+05:30 INFO 23976 --- [main] o.s.batch.core.step.AbstractStep : Step: [INSERT CSV RECORDS To DB Step] executed in 33ms
2023-11-28T14:48:40.748+05:30 INFO 23976 --- [main] .j.c.l.JobCompletionNotificationListener : JOB FINISHED !!
2023-11-28T14:48:40.750+05:30 INFO 23976 --- [main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=Persons Import Job]] completed with the following parameters: [{'JobID':'{value=1701163120629, type=class java.lang.String, identifying=true}'}] and the following status: [COMPLETED] in 50ms8. Retrying Failed Jobs
Batch processing works mainly in chunks. A chunk may fail for any reason such as networking connectivity etc. You want that it will likely be back up soon, though, and that it should be retried.
Similarly, a database update may fail resulting in org.springframework.dao.DeadlockLoserDataAccessException or CannotAcquireLockException (when the current process was a deadlock loser, and its transaction rolled back) and it might be useful to retry.
To configure the retry in Spring batch, the simplest approach is to specify exception classes, on which to retry the operation, in the configuration of a step. Note that when using Java-based configuration to enable retrying, the step needs to be a fault-tolerant step, which in turn can be used to specify the retry limit and retriable exceptions.
@Bean
public Step step1(ItemReader<Person> reader,
ItemWriter<Person> writer,
PlatformTransactionManager txManager) {
var name = "INSERT CSV RECORDS To DB Step";
var builder = new StepBuilder(name, jobRepository);
return builder
.<Person, Person>chunk(5, txManager)
.faultTolerant()
.retryLimit(3).retry(DeadlockLoserDataAccessException.class)
.reader(reader)
.writer(writer)
.build();
}9. Conclusion
In this Spring batch tutorial, we learned the concepts of batch processing, the batch processing from Spring and how to do reading and writing using the inbuilt classes for specific purposes. We created a demo batch process that reads a flat file and saves the records into the database.
Happy Learning !!
How can we ask spring to create the batch tables in different schema?
java.io.FileNotFoundException: class path resource [org/springframework/batch/core/configuration/annotation/EnableBatchProcessing.class] cannot be opened because it does not exist I am facing this issue when I run the application before it implement in java 8 now we migrate java 17 and spring boot 3.2.4 version now we facing this issue how to resolve it
This is workspace issue. The class is very well part of current distribution.
Hi,
For example if there are two jobs job1 and job2 I want to run job2 or job1 1st like the starting of jobs should be under my control. If iam running job2 1st then job1 shouldn’t be started
Could you please help me with this scenario?
Is creating an API for this purpose an option? If yes, create an API and provide job name and action (start/stop) as the request body or header. The best part is you can create START/STOP buttons in the UI to let admins do on their own. DO NOT forget to secure the API.
How to use Spring Cloud config server using spring batch. I would like my spring batch application to behave as a client and consume the properties defined in server config.
Why are the jobs executed twice? I don’t understand that. Used the same code as in this blog article.
Add
spring.batch.job.enabled=falseinapplication.propertiesfile. The first time jobs are executed while initializing the beans. This property will prevent that first execution.In App class if you leave a blank run method still the steps run with run id of 1.
If you do not add “spring.batch.job.enabled=false” to the application.properties file then the steps run twice.
If you add “spring.batch.job.enabled=false” to the application.properties file then the steps run once.