
Learn to use Spring batch partitioning to use multiple threads to process a range of data sets in a spring boot application.
1. Parallel Processing and Step Partitioning
1.1. Parallel Processing
Mostly batch processing problems can be solved using a single-threaded, but a few complex scenarios like single-threaded processing taking a long time to perform tasks, where parallel processing is needed, can be achieved using multi-threaded models.
At a very high level, there are two modes of parallel processing:
- Single-process, multi-threaded
- Multi-process
These break down into categories as well, as follows:
- Multi-threaded
Step(single process) - Parallel
Steps (single process) - Remote Chunking of
Step(multi-process) - Partitioning a
Step(single or multi-process)
1.2. Partitioning in Spring batch
Spring Batch is single-threaded by default. In order to make the parallel processing, we need to partition the steps of the batch job.
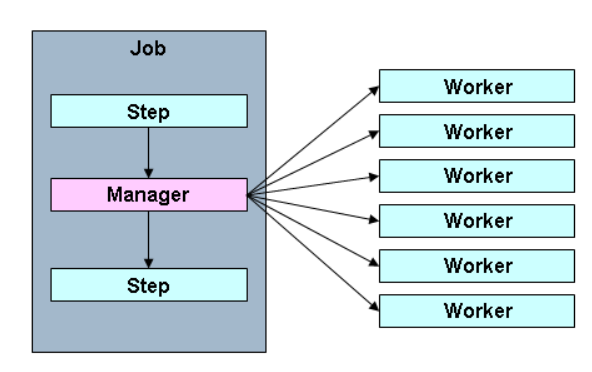
In the above image, Manager is a Step that has been partitioned into multiple Worker steps that are also instances of Step. Workers can be some remote services, locally executing threads or any other independent tasks.
Spring batch allows passing the input data from Manager to Worker steps so each worker knows exactly what to do. The JobRepository ensures that every worker is executed only once in a single execution of the Job.
Partitioning uses multiple threads to process a range of data sets. The range of data sets can be defined programmatically. It’s on the usecase how many threads we want to create to be used in a partition(s). The number of threads is purely based on the need/requirement.
Partitioning is useful when we have millions of records to read from source systems, and we can’t just rely on a single thread to process all records, which can be time-consuming. We want to use multiple threads to read and process data to use system resources effectively.
2. Spring Batch Partitioning Example
In this tutorial, we will read some data from a database table and write it into another table. We can create millions of records into DB in order to experience how long the process would be if using Single thread batch processing. I have created a few programs to understand how the program/concept works here.
2.1. Maven
We used the latest version of Spring Boot, and adding spring-boot-starter-batch dependency will transitively pull the latest versions of the required dependencies.
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<optional>true</optional>
</dependency>
</dependencies>2.2. Step Partitioner
Partitioner is the central strategy interface for creating input parameters for a partitioned step in the form of ExecutionContext instances. The usual aim is to create a set of distinct input values, e.g. a set of non-overlapping primary key ranges or unique filenames.
In this example, we are querying the table to get the MAX and MIN id values (assuming they are sequential), and based on that we’re creating partitions between all records.
For the partitioner, we have used gridSize = number of threads. Use your own custom value based on your requirements.
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import org.springframework.batch.core.partition.support.Partitioner;
import org.springframework.batch.item.ExecutionContext;
import org.springframework.jdbc.core.JdbcOperations;
import org.springframework.jdbc.core.JdbcTemplate;
public class ColumnRangePartitioner implements Partitioner
{
private JdbcOperations jdbcTemplate;
private String table;
private String column;
public void setTable(String table) {
this.table = table;
}
public void setColumn(String column) {
this.column = column;
}
public void setDataSource(DataSource dataSource) {
jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public Map<String, ExecutionContext> partition(int gridSize)
{
int min = jdbcTemplate.queryForObject("SELECT MIN(" + column + ") FROM " + table, Integer.class);
int max = jdbcTemplate.queryForObject("SELECT MAX(" + column + ") FROM " + table, Integer.class);
int targetSize = (max - min) / gridSize + 1;
Map<String, ExecutionContext> result = new HashMap<>();
int number = 0;
int start = min;
int end = start + targetSize - 1;
while (start <= max)
{
ExecutionContext value = new ExecutionContext();
result.put("partition" + number, value);
if(end >= max) {
end = max;
}
value.putInt("minValue", start);
value.putInt("maxValue", end);
start += targetSize;
end += targetSize;
number++;
}
return result;
}
}2.3. Job Configuration
This is the job configuration class where we are creating the necessary beans to perform the job. In this example, we used SimpleAsyncTaskExecutor which is the simplest multi-threaded implementation of the TaskExecutor interface.
We’ve used partitioner in the Step to create a partition step builder for a remote (or local) step. Using these Step for each chunk of data ‘reading, processing and writing’, happens altogether in different threads. Hence, the processed records may not be in the same sequential order as fed into it.
Below are the things to look for:
- A throttle limit is imposed on the task executor when it is backed by some thread pool. This limit defaults to 4 but can be configured differently.
- Concurrency limits might come on the resource used in the
Step, say the DataSource used. - ColumnRangePartitioner – Central strategy interface for creating input parameters for a partitioned step in the form of
ExecutionContextinstances. - JdbcPagingItemReader – This bean reads data using Pagination and accepts minValue and maxValue to be accepted based on range to get those data only. Here we setFetchSize to 1000 however you can use any value and make it configurable from the properties file.
- JdbcBatchItemWriter – This bean will write the data into another table.
- Step – This is the step configured in the batch job. This is reading data and writing it into XML and JSON format.
- Job – Batch domain object representing a job.
import com.howtodoinjava.batch.mapper.CustomerRowMapper;
import com.howtodoinjava.batch.model.Customer;
import com.howtodoinjava.batch.partitioner.ColumnRangePartitioner;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.JdbcPagingItemReader;
import org.springframework.batch.item.database.Order;
import org.springframework.batch.item.database.support.MySqlPagingQueryProvider;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.SimpleAsyncTaskExecutor;
import org.springframework.transaction.PlatformTransactionManager;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class JobConfiguration {
@Autowired
private JobRepository jobRepository;
@Autowired
private PlatformTransactionManager transactionManager;
@Autowired
private DataSource dataSource;
@Bean
public ColumnRangePartitioner partitioner() {
ColumnRangePartitioner columnRangePartitioner = new ColumnRangePartitioner();
columnRangePartitioner.setColumn("id");
columnRangePartitioner.setDataSource(dataSource);
columnRangePartitioner.setTable("customer");
return columnRangePartitioner;
}
@Bean
@StepScope
public JdbcPagingItemReader<Customer> pagingItemReader(
@Value("#{stepExecutionContext['minValue']}") Long minValue,
@Value("#{stepExecutionContext['maxValue']}") Long maxValue) {
System.out.println("reading " + minValue + " to " + maxValue);
Map<String, Order> sortKeys = new HashMap<>();
sortKeys.put("id", Order.ASCENDING);
MySqlPagingQueryProvider queryProvider = new MySqlPagingQueryProvider();
queryProvider.setSelectClause("id, firstName, lastName, birthdate");
queryProvider.setFromClause("from customer");
queryProvider.setWhereClause("where id >= " + minValue + " and id < " + maxValue);
queryProvider.setSortKeys(sortKeys);
JdbcPagingItemReader<Customer> reader = new JdbcPagingItemReader<>();
reader.setDataSource(this.dataSource);
reader.setFetchSize(1000);
reader.setRowMapper(new CustomerRowMapper());
reader.setQueryProvider(queryProvider);
return reader;
}
@Bean
@StepScope
public JdbcBatchItemWriter<Customer> customerItemWriter() {
JdbcBatchItemWriter<Customer> itemWriter = new JdbcBatchItemWriter<>();
itemWriter.setDataSource(dataSource);
itemWriter.setSql("INSERT INTO NEW_CUSTOMER VALUES (:id, :firstName, :lastName, :birthdate)");
itemWriter.setItemSqlParameterSourceProvider
(new BeanPropertyItemSqlParameterSourceProvider<>());
itemWriter.afterPropertiesSet();
return itemWriter;
}
// Master
@Bean
public Step step1() {
return new StepBuilder("step1", jobRepository)
.partitioner(slaveStep().getName(), partitioner())
.step(slaveStep())
.gridSize(4)
.taskExecutor(new SimpleAsyncTaskExecutor())
.build();
}
// slave step
@Bean
public Step slaveStep() {
return new StepBuilder("slaveStep", jobRepository)
.<Customer, Customer>chunk(1000, transactionManager)
.reader(pagingItemReader(null, null))
.writer(customerItemWriter())
.build();
}
@Bean
public Job job() {
return new JobBuilder("job", jobRepository)
.start(step1())
.build();
}
}2.4 Entity and Mapper
Customer is a business model class.
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@Builder
@NoArgsConstructor
public class Customer
{
private Long id;
private String firstName;
private String lastName;
private String birthdate;
}CustomerRowMapper class is used to map the resultset into the Customer domain object.
import java.sql.ResultSet;
import java.sql.SQLException;
import org.springframework.jdbc.core.RowMapper;
import com.howtodoinjava.batch.decorator.model.Customer;
public class CustomerRowMapper implements RowMapper<Customer> {
@Override
public Customer mapRow(ResultSet rs, int rowNum) throws SQLException {
return Customer.builder()
.id(rs.getLong("id"))
.firstName(rs.getString("firstName"))
.lastName(rs.getString("lastName"))
.birthdate(rs.getString("birthdate"))
.build();
}
}2.5. application.properties
Configuration to create DB connection with MySQL DB.
spring.datasource.url=jdbc:h2:mem:test
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
#Prevents running the job during application context creation
spring.batch.job.enabled=false2.6. JDBC Config and Schema Files
These are schema and SQL data files.
CREATE TABLE customer (
id INT PRIMARY KEY,
firstName VARCHAR(255) NULL,
lastName VARCHAR(255) NULL,
birthdate VARCHAR(255) NULL
);
CREATE TABLE new_customer (
id INT PRIMARY KEY,
firstName VARCHAR(255) NULL,
lastName VARCHAR(255) NULL,
birthdate VARCHAR(255) NULL
);INSERT INTO customer VALUES ('1', 'John', 'Doe', '10-10-1952 10:10:10');
INSERT INTO customer VALUES ('2', 'Amy', 'Eugene', '05-07-1985 17:10:00');
INSERT INTO customer VALUES ('3', 'Laverne', 'Mann', '11-12-1988 10:10:10');
INSERT INTO customer VALUES ('4', 'Janice', 'Preston', '19-02-1960 10:10:10');
INSERT INTO customer VALUES ('5', 'Pauline', 'Rios', '29-08-1977 10:10:10');
INSERT INTO customer VALUES ('6', 'Perry', 'Burnside', '10-03-1981 10:10:10');
INSERT INTO customer VALUES ('7', 'Todd', 'Kinsey', '14-12-1998 10:10:10');
INSERT INTO customer VALUES ('8', 'Jacqueline', 'Hyde', '20-03-1983 10:10:10');
INSERT INTO customer VALUES ('9', 'Rico', 'Hale', '10-10-2000 10:10:10');
INSERT INTO customer VALUES ('10', 'Samuel', 'Lamm', '11-11-1999 10:10:10');
INSERT INTO customer VALUES ('11', 'Robert', 'Coster', '10-10-1972 10:10:10');
INSERT INTO customer VALUES ('12', 'Tamara', 'Soler', '02-01-1978 10:10:10');
INSERT INTO customer VALUES ('13', 'Justin', 'Kramer', '19-11-1951 10:10:10');
INSERT INTO customer VALUES ('14', 'Andrea', 'Law', '14-10-1959 10:10:10');
INSERT INTO customer VALUES ('15', 'Laura', 'Porter', '12-12-2010 10:10:10');
INSERT INTO customer VALUES ('16', 'Michael', 'Cantu', '11-04-1999 10:10:10');
INSERT INTO customer VALUES ('17', 'Andrew', 'Thomas', '04-05-1967 10:10:10');
INSERT INTO customer VALUES ('18', 'Jose', 'Hannah', '16-09-1950 10:10:10');
INSERT INTO customer VALUES ('19', 'Valerie', 'Hilbert', '13-06-1966 10:10:10');
INSERT INTO customer VALUES ('20', 'Patrick', 'Durham', '12-10-1978 10:10:10');3. Demo
Run the application as a Spring boot application.
import java.util.Date;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@EnableBatchProcessing
public class LocalPartitioningApplication implements CommandLineRunner
{
@Autowired
private JobLauncher jobLauncher;
@Autowired
private Job job;
public static void main(String[] args) {
SpringApplication.run(LocalPartitioningApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
JobParameters jobParameters = new JobParametersBuilder()
.addString("JobId", String.valueOf(System.currentTimeMillis()))
.addDate("date", new Date())
.addLong("time",System.currentTimeMillis()).toJobParameters();
JobExecution execution = jobLauncher.run(job, jobParameters);
System.out.println("STATUS :: "+execution.getStatus());
}
}The application will read the data from one database using partitions that we created and write it into another table.
2019-12-13 15:03:42.408 --- c.example.LocalPartitioningApplication : Started LocalPartitioningApplication
in 3.504 seconds (JVM running for 4.877)
2019-12-13 15:03:42.523 --- o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=job]]
launched with the following parameters: [{JobId=1576229622410, date=1576229622410, time=1576229622410}]
2019-12-13 15:03:42.603 --- o.s.batch.core.job.SimpleStepHandler : Executing step: [step1]
reading 1 to 5
reading 11 to 15
reading 16 to 20
reading 6 to 10
2019-12-13 15:03:42.890 --- [cTaskExecutor-2] o.s.batch.core.step.AbstractStep : Step: [workerStep:partition0] executed in 173ms
2019-12-13 15:03:42.895 --- [cTaskExecutor-1] o.s.batch.core.step.AbstractStep : Step: [workerStep:partition3] executed in 178ms
2019-12-13 15:03:42.895 --- [cTaskExecutor-3] o.s.batch.core.step.AbstractStep : Step: [workerStep:partition1] executed in 177ms
2019-12-13 15:03:42.901 --- [cTaskExecutor-4] o.s.batch.core.step.AbstractStep : Step: [workerStep:partition2] executed in 182ms
2019-12-13 15:03:42.917 --- o.s.batch.core.step.AbstractStep : Step: [step1] executed in 314ms
2019-12-13 15:03:42.942 --- o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=job]] completed
with the following parameters: [{JobId=1576229622410, date=1576229622410, time=1576229622410}]
and the following status: [COMPLETED] in 374ms
STATUS :: COMPLETED4. Conclusion
In this spring batch step partitioner example with database, we learned to use partitioning to process bulk data using multiple threads. It enables the application to utilize the full potential of machine hardware and operating system capabilities.
Happy Learning !!
What about if you create the job dinamycally, as consequently, you don’t have a way to do with predefined beans ?
That can be done using the JobBuilderFactory and StepBuilderFactory directly.
public Job createDynamicPartitionedJob(int numberOfPartitions, String dataSource) {return jobBuilderFactory.get("dynamicJob_" + UUID.randomUUID())
.start(createPartitionedStep(numberOfPartitions, dataSource))
.build();
}
private Step createPartitionedStep(int gridSize, String dataSource) {
return stepBuilderFactory.get("partitionedStep_" + gridSize)
.partitioner("workerStep", new DynamicPartitioner(gridSize, dataSource))
.step(createWorkerStep(dataSource))
.gridSize(gridSize)
.build();
}