
Learn to use Spring Batch to read records from CSV files and insert them into the database using JdbcBatchItemWriter in a Spring Boot application. We are using the embedded database H2, and you can replace it with any other database of your choice.
1. Learning Objectives
In this demo application, we will perform the following tasks:
- Configure
H2database, initialize the batch schema and create a PERSON table in the database. - Read records from a CSV file with FlatFileItemReader. Consider using MultiResourceItemReader if there are multiple CSV files to process them in parallel.
- Write person records to the PERSON table with JdbcBatchItemWriter.
- Log items inserted into the database using ItemProcessor.
- Verify inserted records using the H2 console.
2. CSV File and Model
For demo purposes, let us create a batch Job that reads the person’s information from a CSV file and saves it into a database. The CSV file looks like this:
Lokesh,Gupta,41,true
Brian,Schultz,42,false
John,Cena,43,true
Albert,Pinto,44,falseTo read a person’s record in Java and process it, we need to create a simple POJO.
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
String firstName;
String lastName;
Integer age;
Boolean active;
}3. Maven
We need to include the following dependencies for the Spring batch to work in a Spring Boot application. Also, include the H2 database for creating the batch schema, and saving the Job execution data and employee records.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>4. Schema Initialization
Spring batch distribution comes with schema files for all popular databases. We only need to refer it when initializing the DataSource using the DataSourceInitializer bean.
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import javax.sql.DataSource;
@Configuration
@EnableBatchProcessing
public class BatchConfig {
DataSource dataSource;
public BatchConfig(DataSource dataSource) {
this.dataSource = dataSource;
}
@Bean
public DataSourceTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public DataSourceInitializer databasePopulator() {
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("org/springframework/batch/core/schema-h2.sql"));
populator.addScript(new ClassPathResource("sql/batch-schema.sql"));
populator.setContinueOnError(false);
populator.setIgnoreFailedDrops(false);
DataSourceInitializer dataSourceInitializer = new DataSourceInitializer();
dataSourceInitializer.setDataSource(dataSource);
dataSourceInitializer.setDatabasePopulator(populator);
return dataSourceInitializer;
}
}In the above configuration, we have created our custom table PERSON using the batch-schema.sql that will be executed when the application starts.
DROP TABLE IF EXISTS person;
CREATE TABLE person (
person_id BIGINT AUTO_INCREMENT NOT NULL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
age INTEGER,
is_active BOOLEAN
);Finally, add the DataSource connection details in the application.properties file to create the DataSource bean. We are connecting to the in-memory H2 database.
spring.datasource.url=jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1
spring.datasource.username=sa
spring.datasource.password=5. Enabling Batch Processing
Use @EnableBatchProcessing annotation on a @Configuration class to enable the batch processing and execute its autoconfiguration with Spring Boot. This will bootstrap Spring Batch with some sensible defaults.
The default configuration will configure a JobRepository, JobRegistry, and JobLauncher beans.
@Configuration
@EnableBatchProcessing
public class BatchConfig {
//...
}6. CSV Reader and Database Writer Configuration
The following BatchConfig class contains all the necessary bean definitions to make the program work. Let’s understand each one:
- The input CSV file is specified using the @Value annotation on the Resource type.
- The Job and Step beans have been defined. The job consists of a single step (
step1). The step includes a chunk-oriented processing mechanism with a specified reader, writer, and transaction manager. - For reading the flat file, we are using FlatFileItemReader with the standard configuration involving DefaultLineMapper, DelimitedLineTokenizer, and BeanWrapperFieldSetMapper classes.
- For writing the records in the database, we are using the JdbcBatchItemWriter which is the standard writer for executing batch queries in a database for Spring batch jobs.
import com.howtodoinjava.demo.batch.jobs.csvToDb.model.Person;
import com.howtodoinjava.demo.batch.jobs.csvToDb.processor.PersonItemProcessor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.job.builder.JobBuilder;
import org.springframework.batch.core.repository.JobRepository;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.BeanPropertyItemSqlParameterSourceProvider;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.file.FlatFileItemReader;
import org.springframework.batch.item.file.LineMapper;
import org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper;
import org.springframework.batch.item.file.mapping.DefaultLineMapper;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.DelimitedLineTokenizer;
import org.springframework.batch.item.file.transform.LineTokenizer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import org.springframework.transaction.PlatformTransactionManager;
import javax.sql.DataSource;
@Configuration
public class CsvToDatabaseJob {
public static final Logger logger = LoggerFactory.getLogger(CsvToDatabaseJob.class);
private static final String INSERT_QUERY = """
insert into person (first_name, last_name, age, is_active)
values (:firstName,:lastName,:age,:active)""";
private final JobRepository jobRepository;
public CsvToDatabaseJob(JobRepository jobRepository) {
this.jobRepository = jobRepository;
}
@Value("classpath:csv/inputData.csv")
private Resource inputFeed;
@Bean(name = "insertIntoDbFromCsvJob")
public Job insertIntoDbFromCsvJob(Step step1, Step step2) {
var name = "Persons Import Job";
var builder = new JobBuilder(name, jobRepository);
return builder.start(step1)
.build();
}
@Bean
public Step step1(ItemReader<Person> reader,
ItemWriter<Person> writer,
ItemProcessor<Person, Person> processor,
PlatformTransactionManager txManager) {
var name = "INSERT CSV RECORDS To DB Step";
var builder = new StepBuilder(name, jobRepository);
return builder
.<Person, Person>chunk(5, txManager)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public FlatFileItemReader<Person> reader(
LineMapper<Person> lineMapper) {
var itemReader = new FlatFileItemReader<Person>();
itemReader.setLineMapper(lineMapper);
itemReader.setResource(inputFeed);
return itemReader;
}
@Bean
public DefaultLineMapper<Person> lineMapper(LineTokenizer tokenizer,
FieldSetMapper<Person> fieldSetMapper) {
var lineMapper = new DefaultLineMapper<Person>();
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(fieldSetMapper);
return lineMapper;
}
@Bean
public BeanWrapperFieldSetMapper<Person> fieldSetMapper() {
var fieldSetMapper = new BeanWrapperFieldSetMapper<Person>();
fieldSetMapper.setTargetType(Person.class);
return fieldSetMapper;
}
@Bean
public DelimitedLineTokenizer tokenizer() {
var tokenizer = new DelimitedLineTokenizer();
tokenizer.setDelimiter(",");
tokenizer.setNames("firstName", "lastName", "age", "active");
return tokenizer;
}
@Bean
public JdbcBatchItemWriter<Person> jdbcItemWriter(DataSource dataSource) {
var provider = new BeanPropertyItemSqlParameterSourceProvider<Person>();
var itemWriter = new JdbcBatchItemWriter<Person>();
itemWriter.setDataSource(dataSource);
itemWriter.setSql(INSERT_QUERY);
itemWriter.setItemSqlParameterSourceProvider(provider);
return itemWriter;
}
@Bean
public PersonItemProcessor personItemProcessor() {
return new PersonItemProcessor();
}
}Also, we are creating PersonItemProcessor which will log the employee records before writing to the database. It’s optional and we are using it for tracking purposes.
import com.howtodoinjava.demo.batch.jobs.csvToDb.model.Person;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ItemProcessListener;
public class PersonItemProcessListener implements ItemProcessListener<Person, Person> {
public static final Logger logger = LoggerFactory.getLogger(PersonItemProcessListener.class);
@Override
public void beforeProcess(Person input) {
logger.info("Person record has been read: " + input);
}
@Override
public void afterProcess(Person input, Person result) {
logger.info("Person record has been processed to : " + result);
}
@Override
public void onProcessError(Person input, Exception e) {
logger.error("Error in reading the person record : " + input);
logger.error("Error in reading the person record : " + e);
}
}7. Demo
Now our demo job is configured and ready to be executed. Start the Spring batch application and launch the batch Job using JobLauncher.
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ApplicationContext;
@SpringBootApplication
public class BatchProcessingApplication implements CommandLineRunner {
private final JobLauncher jobLauncher;
private final ApplicationContext applicationContext;
public BatchProcessingApplication(JobLauncher jobLauncher, ApplicationContext applicationContext) {
this.jobLauncher = jobLauncher;
this.applicationContext = applicationContext;
}
public static void main(String[] args) {
SpringApplication.run(BatchProcessingApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
Job job = (Job) applicationContext.getBean("insertIntoDbFromCsvJob");
JobParameters jobParameters = new JobParametersBuilder()
.addString("JobID", String.valueOf(System.currentTimeMillis()))
.toJobParameters();
var jobExecution = jobLauncher.run(job, jobParameters);
var batchStatus = jobExecution.getStatus();
while (batchStatus.isRunning()) {
System.out.println("Still running...");
Thread.sleep(5000L);
}
}
}Notice the console logs.
2023-11-29T16:12:12.520+05:30 INFO 17712 --- [main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=Persons Import Job]] launched with the following parameters: [{'JobID':'{value=1701254532458, type=class java.lang.String, identifying=true}'}]
2023-11-29T16:12:12.573+05:30 INFO 17712 --- [main] o.s.batch.core.job.SimpleStepHandler : Executing step: [INSERT CSV RECORDS To DB Step]
2023-11-29T16:12:12.646+05:30 INFO 17712 --- [main] c.h.d.b.j.c.p.PersonItemProcessor : Processed record: Person(firstName=Lokesh, lastName=Gupta, age=41, active=true)
2023-11-29T16:12:12.646+05:30 INFO 17712 --- [main] c.h.d.b.j.c.p.PersonItemProcessor : Processed record: Person(firstName=Brian, lastName=Schultz, age=42, active=false)
2023-11-29T16:12:12.647+05:30 INFO 17712 --- [main] c.h.d.b.j.c.p.PersonItemProcessor : Processed record: Person(firstName=John, lastName=Cena, age=43, active=true)
2023-11-29T16:12:12.647+05:30 INFO 17712 --- [main] c.h.d.b.j.c.p.PersonItemProcessor : Processed record: Person(firstName=Albert, lastName=Pinto, age=44, active=false)
2023-11-29T16:12:12.661+05:30 INFO 17712 --- [main] o.s.batch.core.step.AbstractStep : Step: [INSERT CSV RECORDS To DB Step] executed in 87ms
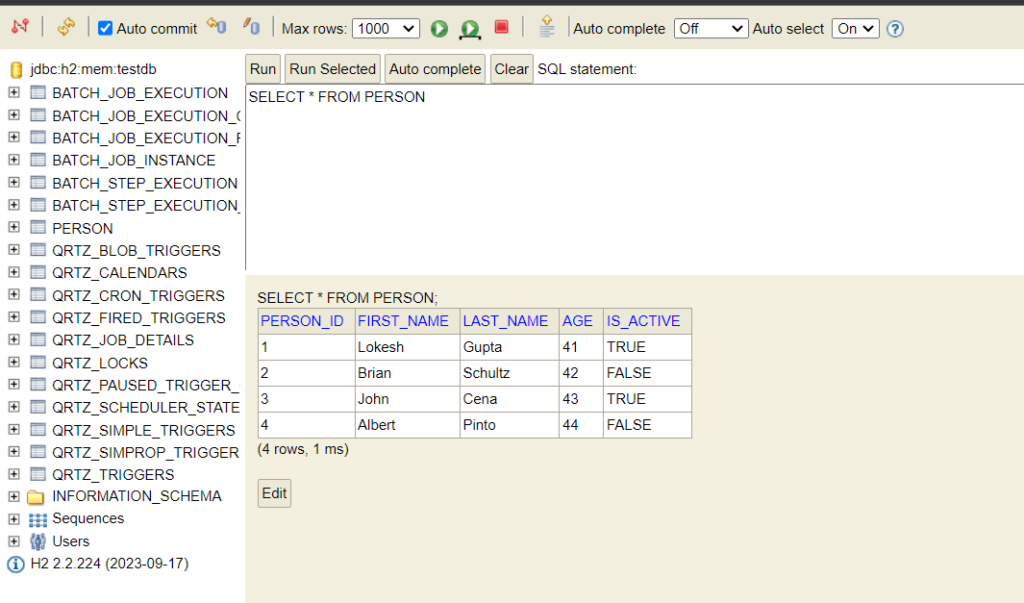
2023-11-29T16:12:12.669+05:30 INFO 17712 --- [main] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=Persons Import Job]] completed with the following parameters: [{'JobID':'{value=1701254532458, type=class java.lang.String, identifying=true}'}] and the following status: [COMPLETED] in 122msLet us also check the H2 console. Notice that the database has the schema created for batch jobs. Also, we have the data written to PERSON table.
Drop me your questions in the comments section.
Happy Learning !!
followed the same example but the records are not being sent to the h2 database. is there anything that is missing
Eshwar, check if you are setting the correct JDBC URL.