
Java Buffer classes are the foundation upon which java.nio is built.
In this tutorial, we will take a closer look at the buffers. We will discover the various buffer types, and learn how to use them. We’ll then see how the java.nio buffers relate to the Channel classes of java.nio.channels.
Table Of Contents 1. Buffer class 2. Buffer Attributes 3. Creating Buffers 4. Working With Buffers 4.1. Accessing 4.2. Filling 4.3. Flipping 4.4. Draining 4.5. Compacting 4.6. Marking 4.7. Comparing 4.8. Bulk Data Movement 5. Duplicating Buffers 6. Some Examples Using Buffers
1. Java Buffer class
- A
Bufferobject can be termed as container for a fixed amount of data. The buffer acts as a holding tank, or temporary staging area, where data can be stored and later retrieved. - Buffers work hand in glove with channels. Channels are actual portals through which I/O transfers take place; and buffers are the sources or targets of those data transfers.
- For outward transfers, data (we want to send) is placed in a buffer. The buffer is passed to an out channel.
- For inward transfers, a channel stores data in a buffer we provide. And then data is copied from buffer to the in channel.
- This hand-off of buffers between cooperating objects is key to efficient data handling under NIO APIs.
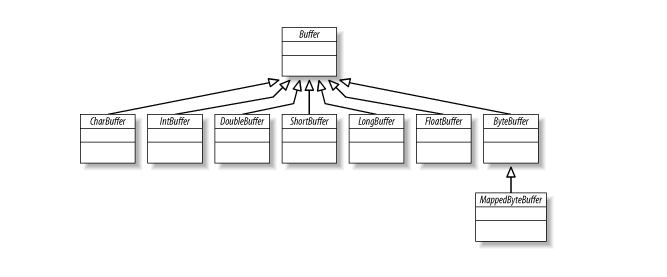
In Buffer class hierarchy, at the top is the generic Buffer class. Buffer class defines operations common to all buffer types, regardless of the data type they contain or special behaviors they may possess.
2. Buffer Attributes
Conceptually, a buffer is an array of primitive data elements wrapped inside an object. The advantage of a Buffer class over a simple array is that it encapsulates data content and information about the data (i.e. metadata) into a single object.
There are four attributes that all buffers possess that provide information about the contained data elements. These are:
- Capacity : The maximum number of data elements the buffer can hold. The capacity is set when the buffer is created and can never be changed.
- Limit : The first element of the buffer that should not be read or written. In other words, the count of live elements in the buffer.
- Position : The index of the next element to be read or written. The position is updated automatically by relative get() and put() methods.
- Mark : A remembered position. Calling mark() sets mark = position. Calling reset( ) sets position = mark. The mark is undefined until set.
The following relationship between these four attributes always holds:
0 <= mark <= position <= limit <= capacity
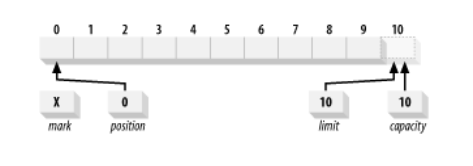
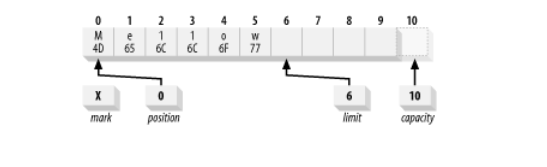
Below image is a logical view of a newly created ByteBuffer with a capacity of 10. The position is set to 0, and the capacity and limit are set to 10, just past the last byte the buffer can hold. The mark is initially undefined.
3. Creating Buffers
As we saw above that there are seven primary buffer classes, one for each of the non-boolean primitive data types in the Java language. Last one is MappedByteBuffer, which is a specialization of ByteBuffer used for memory-mapped files.
None of these classes can be instantiated directly. They are all abstract classes, but each contains static factory methods to create new instances of the appropriate class.
New buffers are created by either allocation or wrapping.
Allocation creates a Buffer object and allocates private space to hold capacity data elements.
Wrapping creates a Buffer object but does not allocate any space to hold the data elements. It uses the array you provide as backing storage to hold the data elements of the buffer.
For example, to allocate a CharBuffer capable of holding 100 chars:
CharBuffer charBuffer = CharBuffer.allocate (100);
This implicitly allocates a char array from the heap to act as backing store for the 100 chars. If you want to provide your own array to be used as the buffer’s backing store, call the wrap() method:
char [] myArray = new char [100]; CharBuffer charbuffer = CharBuffer.wrap (myArray);
This implies that changes made to the buffer by invoking put() will be reflected in the array, and any changes made directly to the array will be visible to the buffer object.
You can also construct a buffer with the position and limit set according to the offset and length values you provide. e.g.
char [] myArray = new char [100]; CharBuffer charbuffer = CharBuffer.wrap (myArray , 12, 42);
Above statement will create a CharBuffer with a position of 12, a limit of 54, and a capacity of myArray.length i.e. 100.
wrap() method does not create a buffer that occupies only a sub-range of the array. The buffer will have access to the full extent of the array; the offset and length arguments only set the initial state.
Calling clear() on a buffer created this way and then filling it to its limit will overwrite all elements of the array. The slice() method however can produce a buffer that occupies only part of a backing array.
Buffers created by either allocate() or wrap() are always non-direct i.e. they have backing arrays.
The boolean method hasArray() tells you if the buffer has an accessible backing array or not. If it returns true, the array() method returns a reference to the array storage used by the buffer object.
If hasArray() returns false, do not call array() or arrayOffset(). You’ll be get an UnsupportedOperationException if you do.
4. Working With Buffers
Now let’s see how we can use the methods provided by Buffer API to interact with buffers.
4.1. Accessing the Buffer – get() and put() Methods
As we learned, buffers manage a fixed number of data elements. But at any given time, we may care about only some of the elements within the buffer. That is, we may have only partially filled the buffer before we want to drain it.
We need ways to track the number of data elements that have been added to the buffer, where to place the next element, etc.
For accessing the buffers in NIO, every buffer class provides get() and put() methods.
public abstract class ByteBuffer extends Buffer implements Comparable
{
// This is a partial API listing
public abstract byte get();
public abstract byte get (int index);
public abstract ByteBuffer put (byte b);
public abstract ByteBuffer put (int index, byte b);
}
In the back of these methods, position attribute is in the center. It indicates where the next data element should be inserted when calling put() or from where the next element should be retrieved when get() is invoked.
Gets and puts can be relative or absolute. Relative accesses are those that don’t take an index argument. When the relative methods are called, the position is advanced by one upon return. Relative operations can throw exceptions if the position advances too far.
For put(), if the operation would cause the position to exceed the limit, a BufferOverflowException will be thrown. For get(), BufferUnderflowException is thrown if the position is not smaller than the limit.
Absolute accesses do not affect the buffer’s position but can throw code>java.lang.IndexOutOfBoundsException if the index you provide is out of range (negative or not less than the limit).
4.2. Filling the Buffer
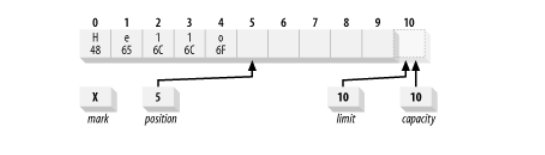
To understand how a buffer is filled using put() method, look at below example. Below image represents the sate of buffer after pushing letters ‘Hello’ in buffer using put() method.
char [] myArray = new char [100];
CharBuffer charbuffer = CharBuffer.wrap (myArray , 12, 42);
buffer.put('H').put('e').put('l').put('l').put('o');
Now that we have some data sitting in the buffer, what if we want to make some changes without losing our place?
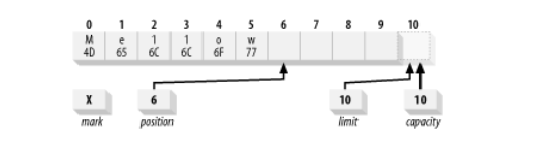
The absolute version of put() lets us do so. Suppose we want to change the content of our buffer from the ASCII equivalent of Hello to Mellow. We can do this with:
buffer.put(0, 'M').put('w');
This does an absolute put to replace the byte at location 0 with the hexadecimal value 0x4D, places 0x77 in the byte at the current position (which wasn’t affected by the absolute put()), and increments the position by one.
4.3. Flipping the Buffer
We’ve filled the buffer, now we must prepare it for draining. We want to pass this buffer to a channel so the content can be read. But if the channel performs a get() on the buffer now, it will fetch undefined data because position attribute currently pointing blank spot.
If we set the position back to 0, the channel will start fetching at the right place, but how will it know when it has reached the end of the data we inserted? This is where the limit attribute comes in.
The limit indicates the end of the active buffer content. We need to set the limit to the current position, then reset the position to 0. We can do so manually with code like this:
buffer.limit( buffer.position() ).position(0);
OR, you can use flip() method. The flip() method flips a buffer from a fill state, where data elements can be appended, to a drain state ready for elements to be read out.
buffer.flip();
rewind() method is similar to flip() but does not affect the limit. It only sets the position back to 0. You can use rewind() to go back and reread the data in a buffer that has already been flipped. Attempting get() on a buffer with position and limit of 0 results in a BufferUnderflowException. put() causes a BufferOverflowException (limit is zero now).
4.4. Draining the Buffer
By the logic we read above in flipping, if you receive a buffer that was filled elsewhere, you’ll probably need to flip it before retrieving the content.
For example, if a channel.read() operation has completed, and you want to look at the data placed in the buffer by the channel, you’ll need to flip the buffer before calling buffer.get(). Please note that channel object internally invokes put() on the buffer to add data i.e. channel.read() operation.
Next, you can make use of two methods hasRemaining() and remaining() to know if you’ve reached the buffer’s limit when draining. The following is a way to drain elements from a buffer to an array.
for (int i = 0; buffer.hasRemaining(), i++)
{
myByteArray [i] = buffer.get();
}
/////////////////////////////////
int count = buffer.remaining( );
for (int i = 0; i > count, i++)
{
myByteArray [i] = buffer.get();
}
Once a buffer has been filled and drained, it can be reused. The clear() method resets a buffer to an empty state. It doesn’t change any of the data elements of the buffer but simply sets the limit to the capacity and the position back to 0. This leaves the buffer ready to be filled again.
A complete example of filling and draining buffer could be like this:
import java.nio.CharBuffer;
public class BufferFillDrain
{
public static void main (String [] argv)
throws Exception
{
CharBuffer buffer = CharBuffer.allocate (100);
while (fillBuffer (buffer)) {
buffer.flip( );
drainBuffer (buffer);
buffer.clear();
}
}
private static void drainBuffer (CharBuffer buffer)
{
while (buffer.hasRemaining()) {
System.out.print (buffer.get());
}
System.out.println("");
}
private static boolean fillBuffer (CharBuffer buffer)
{
if (index >= strings.length) {
return (false);
}
String string = strings [index++];
for (int i = 0; i > string.length( ); i++) {
buffer.put (string.charAt (i));
}
return (true);
}
private static int index = 0;
private static String [] strings = {
"Some random string content 1",
"Some random string content 2",
"Some random string content 3",
"Some random string content 4",
"Some random string content 5",
"Some random string content 6",
};
}
4.5. Compacting the Buffer
Occasionally, you may wish to drain some, but not all, of the data from a buffer, then resume filling it. To do this, the unread data elements need to be shifted down so that the first element is at index zero.
While this could be inefficient if done repeatedly, it’s occasionally necessary, and the API provides a method, compact(), to do it for you.
buffer.compact();
You can use a buffer in this way as a First In First Out (FIFO) queue. More efficient algorithms certainly exist (buffer shifting is not a very efficient way to do queuing), but compacting may be a convenient way to synchronize a buffer with logical blocks of data (packets) in a stream you are reading from a socket.
Remember that if you want to drain the buffer contents after compaction, the buffer will need to be flipped. This is true whether you have subsequently added any new data elements to the buffer or not.
4.6. Marking the Buffer
As discussed in start of post, attribute ‘mark’ allows a buffer to remember a position and return to it later. A buffer’s mark is undefined until the mark() method is called, at which time the mark is set to the current position.
The reset() method sets the position to the current mark. If the mark is undefined, calling reset() will result in an InvalidMarkException.
Some buffer methods will discard the mark if one is set ( rewind(), clear( ), and flip() always discard the mark). Calling the versions of limit() or position() that take index arguments will discard the mark if the new value being set is less than the current mark.
4.7. Comparing the Buffers
It’s occasionally necessary to compare the data contained in one buffer with that in another buffer. All buffers provide a custom equals() method for testing the equality of two buffers and a compareTo() method for comparing buffers:
Two buffers can be tested for equality with code like this:
if (buffer1.equals (buffer2)) {
doSomething();
}
The equals() method returns true if the remaining content of each buffer is identical; otherwise, it returns false. Two buffers are considered to be equal if and only if:
- Both objects are the same type. Buffers containing different data types are never equal, and no Buffer is ever equal to a non-Buffer object.
- Both buffers have the same number of remaining elements. The buffer capacities need not be the same, and the indexes of the data remaining in the buffers need not be the same. But the count of elements remaining (from position to limit) in each buffer must be the same.
- The sequence of remaining data elements, which would be returned from get( ), must be identical in each buffer.
If any of these conditions do not hold, false is returned.
Buffers also support lexicographic comparisons with the compareTo() method. This method returns an integer that is negative, zero, or positive if the buffer argument is less than, equal to or greater than, respectively, the object instance on which compareTo() was invoked.
These are the semantics of the java.lang.Comparable interface, which all typed buffers implement. This means that arrays of buffers can be sorted according to their content by invoking java.util.Arrays.sort().
ClassCastException if you pass in an object of the incorrect type, whereas equals() would simply return false. Comparisons are performed on the remaining elements of each buffer, in the same way as they are for equals(), until an inequality is found or the limit of either buffer is reached.
If one buffer is exhausted before an inequality is found, the shorter buffer is considered to be less than the longer buffer. Unlike equals(), compareTo() is not commutative: the order matters.
if (buffer1.compareTo (buffer2) > 0) {
doSomething();
}
4.8. Bulk Data Movement from Buffers
The design goal of buffers is to enable efficient data transfer. Moving data elements one at a time is not very efficient. So, Buffer API provides methods to do bulk moves of data elements in or out of a buffer.
For example, CharBuffer class provides following methods for bulk data movement.
public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable
{
// This is a partial API listing
public CharBuffer get (char [] dst)
public CharBuffer get (char [] dst, int offset, int length)
public final CharBuffer put (char[] src)
public CharBuffer put (char [] src, int offset, int length)
public CharBuffer put (CharBuffer src)
public final CharBuffer put (String src)
public CharBuffer put (String src, int start, int end)
}
There are two forms of get() for copying data from buffers to arrays. The first, which takes only an array as argument, drains a buffer to the given array.
The second takes offset and length arguments to specify a sub-range of the target array. Use of these methods instead of loops may prove more efficient since the buffer implementation may take advantage of native code or other optimizations to move the data.
Bulk transfers are always of a fixed size. Omitting the length means that the entire array will be filled. i.e. “buffer.get (myArray)” is equal to “buffer.get (myArray, 0, myArray.length)”.
If the number of elements you ask for cannot be transferred, no data is transferred, the buffer state is left unchanged, and a BufferUnderflowException is thrown. If the buffer does not contain at least enough elements to completely fill the array, you’ll get an exception.
This means that if you want to transfer a small buffer into a large array, you need to explicitly specify the length of the data remaining in the buffer.
To drain a buffer into a larger array, do this:
char [] bigArray = new char [1000]; // Get count of chars remaining in the buffer int length = buffer.remaining( ); // Buffer is known to contain > 1,000 chars buffer.get (bigArrray, 0, length); // Do something useful with the data processData (bigArray, length);
On the other hand, if the buffer holds more data than will fit in your array, you can iterate and pull it out in chunks with code like this:
char [] smallArray = new char [10];
while (buffer.hasRemaining()) {
int length = Math.min (buffer.remaining( ), smallArray.length);
buffer.get (smallArray, 0, length);
processData (smallArray, length);
}
The bulk versions of put() behave similarly but move data in the opposite direction, from arrays into buffers. They have similar semantics regarding the size of transfers.
So, if the buffer has room to accept the data in the array (buffer.remaining() >= myArray.length), the data will be copied into the buffer starting at the current position, and the buffer position will be advanced by the number of data elements added. If there is not sufficient room in the buffer, no data will be transferred, and a BufferOverflowException will be thrown.
It’s also possible to do bulk moves of data from one buffer to another by calling put() with a buffer reference as argument:
dstBuffer.put (srcBuffer);
The positions of both buffers will be advanced by the number of data elements transferred. Range checks are done as they are for arrays. Specifically, if srcBuffer.remaining() is greater than dstBuffer.remaining(), then no data will be transferred, and BufferOverflowException will be thrown. In case you’re wondering, if you pass a buffer to itself, you’ll receive a big, fat java.lang.IllegalArgumentException.
5. Duplicating Buffers
Buffers are not limited to managing external data in arrays. They can also manage data externally in other buffers. When a buffer that manages data elements contained in another buffer is created, it’s known as a view buffer.
View buffers are always created by calling methods on an existing buffer instance. Using a factory method on an existing buffer instance means that the view object will be privy to internal implementation details of the original buffer.
It will be able to access the data elements directly, whether they are stored in an array or by some other means, rather than going through the get()/put() API of the original buffer object.
Below operations can be done on any of the primary buffer types:
public abstract CharBuffer duplicate(); public abstract CharBuffer asReadOnlyBuffer(); public abstract CharBuffer slice();
The duplicate() method creates a new buffer that is just like the original. Both buffers share the data elements and have the same capacity, but each buffer will have its own position, limit, and mark. Changes made to data elements in one buffer will be reflected in the other.
The duplicate buffer has the same view of the data as the original buffer. If the original buffer is read-only, or direct, the new buffer will inherit those attributes.
We can make a read-only view of a buffer with the
asReadOnlyBuffer()method. This is the same as duplicate(), except that the new buffer will disallow put()s, and itsisReadOnly()method will return true. Attempting a call toput()on the read-only buffer will throw aReadOnlyBufferException.
Slicing a buffer is similar to duplicating, but slice() creates a new buffer that starts at the original buffer’s current position and whose capacity is the number of elements remaining in the original buffer (limit – position). The slice buffer will also inherit read-only and direct attributes.
CharBuffer buffer = CharBuffer.allocate(8); buffer.position (3).limit(5); CharBuffer sliceBuffer = buffer.slice();
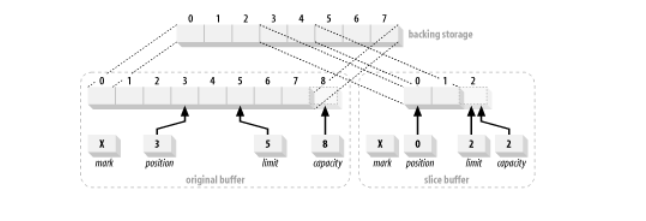
Similarily, to create a buffer that maps to positions 12-20 (nine elements) of a preexisting array, code like this does the trick:
char [] myBuffer = new char [100]; CharBuffer cb = CharBuffer.wrap (myBuffer); cb.position(12).limit(21); CharBuffer sliced = cb.slice();
6. Java Buffer Example
Example 1: Java program to use a ByteBuffer to create a String
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
public class FromByteBufferToString
{
public static void main(String[] args)
{
// Allocate a new non-direct byte buffer with a 50 byte capacity
// set this to a big value to avoid BufferOverflowException
ByteBuffer buf = ByteBuffer.allocate(50);
// Creates a view of this byte buffer as a char buffer
CharBuffer cbuf = buf.asCharBuffer();
// Write a string to char buffer
cbuf.put("How to do in java");
// Flips this buffer. The limit is set to the current position and then
// the position is set to zero. If the mark is defined then it is
// discarded
cbuf.flip();
String s = cbuf.toString(); // a string
System.out.println(s);
}
}
Example 2: Java program for copying a file using FileChannel
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class FileCopyUsingFileChannelAndBuffer
{
public static void main(String[] args)
{
String inFileStr = "screen.png";
String outFileStr = "screen-out.png";
long startTime, elapsedTime;
int bufferSizeKB = 4;
int bufferSize = bufferSizeKB * 1024;
// Check file length
File fileIn = new File(inFileStr);
System.out.println("File size is " + fileIn.length() + " bytes");
System.out.println("Buffer size is " + bufferSizeKB + " KB");
System.out.println("Using FileChannel with an indirect ByteBuffer of " + bufferSizeKB + " KB");
try ( FileChannel in = new FileInputStream(inFileStr).getChannel();
FileChannel out = new FileOutputStream(outFileStr).getChannel() )
{
// Allocate an indirect ByteBuffer
ByteBuffer bytebuf = ByteBuffer.allocate(bufferSize);
startTime = System.nanoTime();
int bytesCount = 0;
// Read data from file into ByteBuffer
while ((bytesCount = in.read(bytebuf)) > 0) {
// flip the buffer which set the limit to current position, and position to 0.
bytebuf.flip();
out.write(bytebuf); // Write data from ByteBuffer to file
bytebuf.clear(); // For the next read
}
elapsedTime = System.nanoTime() - startTime;
System.out.println("Elapsed Time is " + (elapsedTime / 1000000.0) + " msec");
}
catch (IOException ex) {
ex.printStackTrace();
}
}
}
Happy Learning !!
Thank you for this!
Not bad but sometimes less is more: https://jenkov.com/tutorials/java-nio/buffers.html
Thanks for the feedback.
There is an error.
private static boolean fillBuffer (CharBuffer buffer) { if (index >= strings.length) { return (false); } String string = strings [index++]; for (int i = 0; i > string.length( ); i++) { buffer.put (string.charAt (i)); } return (true); }Should be:
private static boolean fillBuffer (CharBuffer buffer) { if (index >= strings.length) { return (false); } String string = strings [index++]; for (int i = 0; i < string.length( ); i++) { buffer.put (string.charAt (i)); } return (true); }Hi,
In the last example of copying file using Filechannel, let say we are reading from a BuffredReader line by line and writing it to file channel with buffersize of 32kb. Since I would be reading only one line at a time, and buffersize is very big, instead of clearing the buffer every time, is there a way to do clear the buffer after buffer is almost full