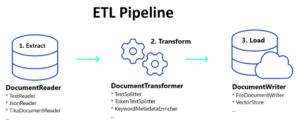
The Extract, Transform, and Load (ETL) pipeline refers to the process of ingesting raw data sources (text, JSON/XML, audio, video, etc.) to a structured vector store. ETL-ingested data is used for similarity searches in RAG-based applications using Spring AI.
See Also: ETL Pipeline using Spring Cloud Function and Spring AI
1. Primary Interfaces
There are three main components of the ETL pipeline implemented using Spring AI:
- DocumentReader: reads documents from a specified source.
- DocumentTransformer: transforms the documents, such as splitting long text into pages or paragraphs.
- DocumentWriter: writes the documents to a storage, such as a file system or vector database.

Spring AI provides many built-in implementations of these interfaces (such as TikaDocumentReader implements DocumentReader) and we can create our custom implementations as well.
After the necessary beans have been created, we can build an ETL pipeline as follows:
TikaDocumentReader documentReader = ...;
TokenTextSplitter documentTransformer = ...;
VectorStore documentWriter = ...;
documentWriter.write(documentTransformer.split(documentReader.read()));2. Building an ETL Pipeline
Let us create an ETL pipeline from the beginning to understand it better. In our case, the requirements are:
- All the content files (text, CSV etc) are stored in a specific directory in the filesystem.
- The program should read all the files, only with specified extensions, present in the directory. All other files should be ignored.
- The transformer process will break the file content into specific chunk sizes.
- The chunked content is stored in a vector database by the document writer.
2.1. Maven
In our demo, we are using the following dependencies:
- spring-ai-tika-document-reader: for reading the input documents in various formats.
- spring-ai-openai-spring-boot-starter: for OpenAiEmbeddingModel used for creating vectors from chunk texts.
- spring-ai-chroma-store-spring-boot-starter: for using Chroma database as vector store.
- spring-boot-docker-compose: to start the Chroma database as a container.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-chroma-store-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-docker-compose</artifactId>
<scope>runtime</scope>
</dependency> 2.2. Document Reader
We are using TikaDocumentReader which leverages Apache Tika to extract text from a variety of document formats, such as PDF, DOC/ DOCX, PPT/ PPTX, and HTML apart from other supported formats. All extracted texts are encapsulated within a Document instance.
As we have to read multiple files outside the project directory, we use JDK’s Files API to list and iterate over all supported files. During iteration, we use Files.readAllBytes() to read the file content and use TikaDocumentReader to convert the bytes to org.springframework.ai.document.Document object.
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.List;
import lombok.SneakyThrows;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.ByteArrayResource;
import org.springframework.stereotype.Component;
@Component
public class CustomDocumentReader implements DocumentReader {
private static final Logger LOGGER = LoggerFactory.getLogger(CustomDocumentReader.class);
@Value("${input.directory}")
private String inputDir;
@Value("${input.filename.regex}")
private String pattern;
@SneakyThrows
@Override
public List<Document> get() {
List<Document> documentList = new ArrayList<>();
TikaDocumentReader tikaDocumentReader;
Files.newDirectoryStream(Path.of(inputDir), pattern).forEach(path -> {
List<Document> documents = null;
try {
documents = new TikaDocumentReader(new ByteArrayResource(Files.readAllBytes(path))).get()
.stream().peek(document -> {
document.getMetadata().put("source", path.getFileName());
LOGGER.info("Reading new document :: {}", path.getFileName());
}).toList();
} catch (IOException e) {
throw new RuntimeException("Error while reading the file : " + path.toUri() + "::" + e);
}
documentList.addAll(documents);
});
return documentList;
}
}The input directory and supported file extensions can be read from a properties file:
input.directory=c:/temp/ingestion-files/
input.filename.regex=*.{pdf,docx,txt,pages,csv}2.3. Document Transformer
We might be reading some large text documents so it is quite logical to break the text into chunks so they can fit into the LLM context window. If larger text is sent, the converted vectors might not produce the expected results during a similarity search.
We are using the TokenTextSplitter with default options. If required, we can configure the different chunk sizes to split the document by passing the values as constructor arguments.
@Configuration
public class AppConfiguration {
@Bean
TextSplitter textSplitter() {
return new TokenTextSplitter();
}
}2.4. Document Writer
When we add the Chroma DB dependency, Spring AI will automatically create a bean of type ChromaVectorStore. The connection properties are picked from docker-compose file automatically.
version: '3.9'
networks:
net:
driver: bridge
services:
server:
image: ghcr.io/chroma-core/chroma:latest
environment:
- IS_PERSISTENT=TRUE
volumes:
- chroma-data:/chroma/chroma/
ports:
- 8000:8000
networks:
- net
volumes:
chroma-data:
driver: localIf you have installed ChromaDB locally, then specify the connection details in the properties file.
Now, we can access the VectorStore bean in any Spring-managed bean:
@Component
public class EtlPipeline {
@Autowired
VectorStore vectorStore;
//...
}2.5. ETL Pipeline
After the reader, transformer, and writer have been created, we can join them to create the pipeline.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.transformer.splitter.TextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Component;
@Component
public class EtlPipeline {
private static final Logger LOGGER = LoggerFactory.getLogger(EtlPipeline.class);
private final CustomDocumentReader documentReader;
private final VectorStore vectorStore;
private final TextSplitter textSplitter;
public EtlPipeline(VectorStore vectorStore,
TextSplitter textSplitter,
CustomDocumentReader documentReader) {
this.vectorStore = vectorStore;
this.textSplitter = textSplitter;
this.documentReader = documentReader;
}
public void runIngestion() {
LOGGER.info("RunIngestion() started");
vectorStore.write(textSplitter.apply(documentReader.get())); // ETL Pipeline
LOGGER.info("RunIngestion() finished");
}
}2.6. Executing ETL Pipeline
There can be many ways we can invoke the document ingestion process as it all depends on the project needs. For example, it can be invoked through a scheduled Job, batch process, or on-demand REST API endpoint.
For this demo, we are invoking it as a REST endpoint.
@RestController
public class IngestionController {
EtlPipeline etlPipeline;
public IngestionController(EtlPipeline etlPipeline){
this.etlPipeline = etlPipeline;
}
@PostMapping("run-ingestion")
public ResponseEntity<?> run(){
etlPipeline.runIngestion();
return ResponseEntity.accepted().build();
}
}3. Demo
After all the components are in place, place some files in the input directory, start the server, and execute the /run-ingestion request from an API client. Observe the server logs in the console. It will print all the files that were processed by the ETL pipeline.
...c.h.ai.demo.EtlPipeline : RunIngestion() started
...c.h.ai.demo.EtlPipeline : Reading new document :: current-affairs.pdf
...c.h.ai.demo.EtlPipeline : Reading new document :: data.txt
...c.h.ai.demo.EtlPipeline : Reading new document :: pan-format-file.csv
...c.h.ai.demo.EtlPipeline : RunIngestion() finished4. Summary
In this short Spring AI ETL pipeline example, we created a data ingestion service that reads multiple documents (different formats) from a specified file-system directory, processes the content into chunks, and stores their embeddings into the Chroma vector database.
Happy Learning !!
Comments