
For creating an ETL pipeline for Spring AI data ingestion microservice, Spring cloud functions are an excellent choice. Spring Cloud Function module promotes the implementation of business logic as Java Functions. These functions can be run from any different runtime targets such as a web endpoint, a stream processor, or a task. This is especially useful for deploying your code on serverless providers such as AWS Lambda, Azure Functions, or Google Cloud Functions.
Spring Cloud Function embraces and builds on top of the 3 core functional interfaces:
- Supplier<Out>
- Function<In, Out>
- Consumer<In>
By writing functions of each type, and using function composition to compose several functions into one, we can create an ETL pipeline where the output of a function is input to the next function.
1. Maven
To configure the ETL pipeline using Functions, start adding the necessary dependencies of Spring AI and Spring Cloud Function modules.
<properties>
<spring.cloud.version>2023.0.1</spring.cloud.version>
<spring.functions.catalog.version>5.0.0-SNAPSHOT</spring.functions.catalog.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-context</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud.fn</groupId>
<artifactId>spring-file-supplier</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-chroma-store-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-docker-compose</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring.cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud.fn</groupId>
<artifactId>spring-functions-catalog-bom</artifactId>
<version>${spring.functions.catalog.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement> 2. File Supplier and Document Reader
The spring-file-supplier module provides a fileSupplier that can be reused and composed in other applications. This supplier gives you a reactive stream of files from the provided directory, and Users have to subscribe to this Flux and receive the data.
The location of the input directory and supported file formats, we can configure the corresponding file.supplier.* properties.
file.supplier.directory=c:/temp/ingestion-files
file.supplier.filename-regex=.*\.(pdf|docx|txt|pages|csv)Upon detecting the Maven coordinates and configured properties, Spring will automatically enable a Function that will read the file contents and return the ‘Flux<Message<byte[]>>‘. But, in the Spring AI ETL pipeline, we need a Flux of org.springframework.ai.document.Document objects. So we need to create a new function, let’s say documentReader, that will do this conversion.
@Configuration
public class CloudFunctionConfig {
@Bean
Function<Flux<Message<byte[]>>, Flux<List<Document>>> documentReader() {
return resourceFlux -> resourceFlux
.map(message ->
new TikaDocumentReader(new ByteArrayResource(message.getPayload()))
.get()
.stream()
.peek(document -> {
document.getMetadata()
.put("source", message.getHeaders().get("file_name"));
})
.toList()
);
}
//...
}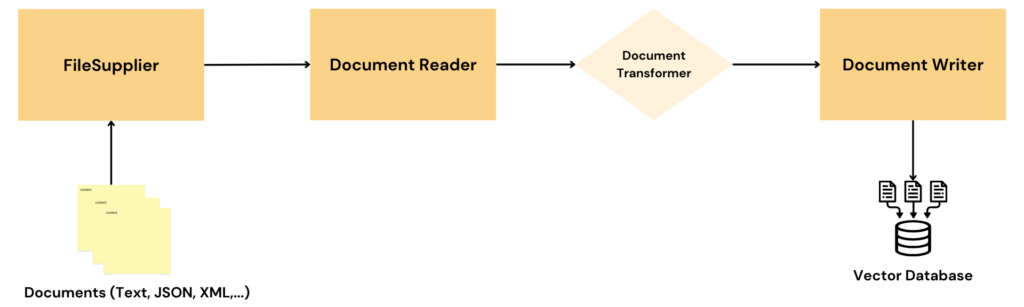
3. Document Transformer
The transformer Function simply splits the read Document into chunk texts using the TokenTextSplitter.
@Configuration
public class CloudFunctionConfig {
@Bean
Function<Flux<List<Document>>, Flux<List<Document>>> documentTransformer() {
return documentListFlux ->
documentListFlux
.map(unsplitList -> new TokenTextSplitter().apply(unsplitList));
}
//...
}4. Document Writer
Finally, the document writer accepts the chunked Document list and stores its text and embeddings in the vector database.
@Configuration
public class CloudFunctionConfig {
private static final Logger LOGGER = LoggerFactory.getLogger(CloudFunctionConfig.class);
@Bean
Consumer<Flux<List<Document>>> documentWriter(VectorStore vectorStore) {
return documentFlux -> documentFlux
.doOnNext(documents -> {
LOGGER.info("Writing {} documents to vector store.", documents.size());
vectorStore.accept(documents);
LOGGER.info("{} documents have been written to vector store.", documents.size());
})
.subscribe();
}
//...
}5. Configuring ETL Pipeline
Once all the beans have been added to the @Configuration class, we can compose the function pipeline in the properties file:
spring.cloud.function.definition=fileSupplier|documentReader|documentTransformer|documentWriter6. Executing the Pipeline
A Function can be executed by finding its instance using the FunctionCatalog.lookup(), and then calling its run() method to execute it.
The catalog.lookup(null) will return the composed function as it is the only function registered in the context. Otherwise, we have to provide the Function name in the lookup() method.
@Service
public class IngestionService {
private final FunctionCatalog catalog;
public IngestionService(FunctionCatalog catalog) {
this.catalog = catalog;
}
public void ingest() {
Runnable composedFunction = catalog.lookup(null);
composedFunction.run();
}
}7. Demo
From this point, we can call the ingest() method from any technique such as REST endpoint, batch scheduled task, or any stream-enabled application.
@RestController
public class IngestionController {
IngestionService ingestionService;
public IngestionController(IngestionService ingestionService){
this.ingestionService = ingestionService;
}
@PostMapping("run-ingestion")
public ResponseEntity<?> run(){
ingestionService.ingest();
return ResponseEntity.accepted().build();
}
}In your local machine, run the application and invoke the ‘/run-ingestion‘ endpoint. It will execute all the functions in sequence and store the file content embeddings in the vector database.
Check the console logs for verification.
Writing 7 documents to vector store.
7 documents have been written to vector store.8. Summary
In this short Spring Cloud Function tutorial, we built a data ingestion ETL pipeline for Spring AI applications. This application uses a built-in Supplier Function that reads multiple documents (different formats) from a specified file-system directory. We wrote additional Function handles for processing the content into chunks and storing the embeddings into the Chroma vector database.
Happy Learning !!
Comments