In Spring AI, the role of a vector database is to store vector embeddings and facilitate similarity searches for these embeddings. A vector store does not generate the embeddings itself. For creating vector embeddings, the EmbeddingModel should be utilized.
1. What is a Vector Database?
A vector (or embedding) is a long array of numbers representing objects such as a word, sentence, file, or audio/video data. In a vector (array of numbers), each number represents a distinct feature or attribute of the data, such as emotional positivity, intensity, context and so on. Vectors help in finding the relatedness between other objects by finding the distance between two vectors. This process is commonly known as semantic search.
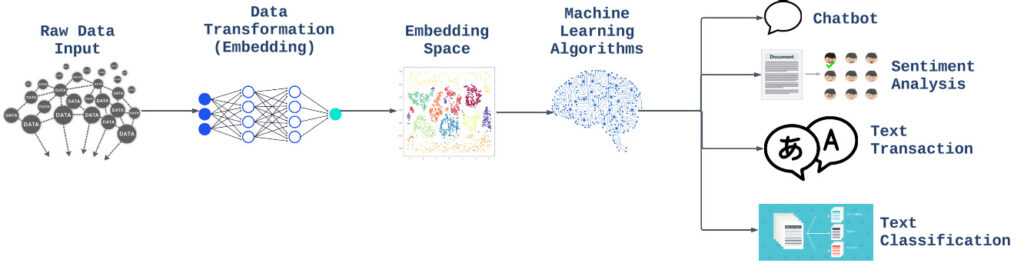
A vector database is a specialized database that stores data as high dimensional vectors at a high scale, low latency, and with security. Here is a high-level overview of how the vector store databases work.
- Data Storage: Raw data such as text, images, or videos is transformed into vectors using AI models and then stored in the vector database.
- Data Retrieval: When a search has to be made, first the search query (text/audio/video) is converted to a vector using the same model that was used for generating the vectors of raw data. Then the query vector is used for finding the vectors that are most similar to the query vector. Vector databases, through semantic searches, help with addressing some of the issues with LLMs such as hallucinations.
- Calculating Similarity: The choice of calculation method depends on the specific application and the nature of the data. Generally, one of the following methods is used for finding the similarity between two vectors:
- Euclidean Distance: distance between two vectors is the straight-line distance in Euclidean space.
- Cosine Similarity: the cosine of the angle between two vectors.
- Manhattan Distance (L1 Distance): the sum of the absolute differences of the vector components.
- Jaccard Similarity: the size of the intersection divided by the size of the union.
There are various vector databases on the market. Some are from startups such as Pinecone, Elasticsearch, and others are open source such as Chroma, Weaviate, and Quadrant.
2. Spring VectorStore Interface
The primary interface in Spring AI for interacting with vector databases is the VectorStore interface. This interface provides methods for storing the Document objects in a vector database and methods for making similarity searches on the stored vectors.
public interface VectorStore {
void add(List<Document> documents);
Optional<Boolean> delete(List<String> idList);
List<Document> similaritySearch(String query);
List<Document> similaritySearch(SearchRequest request);
}Note that the Document object is an encapsulation of raw content, its vector embedding, and related meta-data such as the filename.
public class Document implements Content {
private Map<String, Object> metadata;
private String content;
private List<Double> embedding = new ArrayList<>();
//...
}3. Storing and Querying Documents
A VectorStore type bean is automatically initialized by Spring Boot autoconfiguration when it detects a supported starter module for a vector database. For example, when we add the spring-ai-chroma-store-spring-boot-starter dependency, String boot will trigger the autoconfiguration for configuring the ChromaDB and create a bean of type ChromaVectorStore.
We can access the bean using the generic VectorStore interface type so when we can later switch the ChromaDB with any other vector database then we do not need to make code changes.
@Autowired
VectorStore vectorStore;Once the VectorStore bean is available, we can use it for storing documents in the database:
List<Document> documents = List.of(
new Document("...content..."),
new Document("...content..."),
new Document("...content..."));
vectorStore.add(List.of(document));And for making semantic searches into the database:
List<Document> results = vectorStore.similaritySearch(
SearchRequest.query("...search-terms...").withTopK(5)
);Spring AI supports several vector databases and more support will be added in the future. For the complete list of supported databases and respective configurations, please visit the official docs.
4. SimpleVectorStore
For demo purposes, rather than configuring a complex vector store database implementation, we can make use of SimpleVectorStore. The SimpleVectorStore is a simple implementation of the VectorStore interface that provides methods to save the current state of the vectors to a file and to load vectors from a file. I find it quite similar to H2 in-memory database usage in place of a regular relational database in a development environment.
Note that it does not save/load the embedding file from the database, rather it provides methods to save the current state of the vectors to a file, and to load vectors from a file.
public class SimpleVectorStore implements VectorStore {
public void add(List<Document> documents) {...}
public List<Document> similaritySearch(SearchRequest request) {...}
public void save(File file) {...}
public void load(File file) {...}
public void load(Resource resource) {...}
//...
}The SimpleVectorStore bean only requires EmbeddingModel bean reference that will be used for generating the vector embeddings from raw data.
@Bean
SimpleVectorStore vectorStore(EmbeddingModel embeddingModel) {
return new SimpleVectorStore(embeddingModel);
}5. Vector Store Demo using ChromaDB
Let us see a quick demo of VectorStore bean in action by configuring Chroma database and using it for storing and querying the embeddings.
5.1. Setup ChromaDB
For setting up the Chroma database, we are using Spring Boot Docker Compose support. We will place the compose file in the project root and let the docker-compose module start the chroma database.
version: '3.9'
networks:
net:
driver: bridge
services:
server:
image: ghcr.io/chroma-core/chroma:latest
environment:
- IS_PERSISTENT=TRUE
volumes:
- chroma-data:/chroma/chroma/
ports:
- 8000:8000
networks:
- net
volumes:
chroma-data:
driver: local5.2. Maven
Next, we add the relevant maven dependencies and let Spring Boot configure the necessary beans such as:
- OpenAiEmbeddingModel: will be used for creating the embedding from raw data.
- ChromaVectorStore: will be used to store and query the generated embeddings.
The spring-boot-docker-compose will scan for the compose file (given in the previous section) and start a database instance as a docker container. It will also read the database connection details automatically, and create a VectorStore bean for us.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-chroma-store-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-docker-compose</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>Optionally, we can add other libraries to assist us with reading, parsing, and tokenizing the documents before sending them to the embedding model.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>5.3. Loading Data into Vector Store
There is no fixed way how to read and create embeddings from raw data. This will vary from project to project. In this demo, we have created a simple VectorStoreLoader class that reads a text file, MD file, and PDF file using the Apache Tika library.
The read data is then added to Document objects and finally added to the vector store. The vector store bean internally invokes the embedding model and stores the generated vectors in the database.
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Component;
@Component
public class VectorStoreLoader implements ApplicationRunner {
@Value("classpath:/CallingRates.pdf")
Resource pdfResource;
@Value("classpath:/story.txt")
Resource txtResource;
@Value("classpath:/story.md")
Resource mdResource;
@Autowired
VectorStore vectorStore;
@Override
public void run(ApplicationArguments args) throws Exception {
List<Document> documents = new ArrayList<>();
TikaDocumentReader reader = new TikaDocumentReader(pdfResource);
documents.addAll(reader.get());
vectorStore.add(documents);
var textReader1 = new TextReader(txtResource);
textReader1.setCharset(Charset.defaultCharset());
documents.addAll(textReader1.get());
var textReader2 = new TextReader(mdResource);
textReader2.setCharset(Charset.defaultCharset());
documents.addAll(textReader2.get());
vectorStore.add(new TokenTextSplitter(300, 300, 5, 1000, true).split(documents));
System.out.println("Added documents to vector store");
}
}5.4. Similarity Search
When needed, we can call the vectorStore.similaritySearch() to find similar documents that match the query term.
List<Document> documents = vectorStore.similaritySearch("investigation");
documents.stream().forEach(System.out::println);Program output:
Document{id='7cec17aa-...', metadata={source=story.md , distance=0.7674138}, content='...', media=[]}
Document{id='42726cdb-...', metadata={source=story.text, distance=0.8732333}, content='...', media=[]}
Document{id='9aad7daa-...', metadata={source=story.pdf , distance=0.8799484}, content='...', media=[]}
...
...
6. Conclusion
In this short Spring API Vector Database example, we learned what is a vector and what is a vector database. Learned how vectors are stored in the database and how similarity search is used for finding the nearest neighbors used in AI applications.
We discussed the Spring AI VectorStore interfaces and how their specific implementations can be created and used using Spring Boot auto-configuration. Finally, we saw the example of setting up the Chroma vector database using Docker Compose and using it to store vector embeddings generated by the OpenAI embedding model.
Happy Learning !!
Comments