In this Java Collections tutorial, we will learn the Java ConcurrentSkipListMap in detail and cover the significant differences between ConcurrentSkipListMap and other Map implementations.
1. Introduction to ConcurrentSkipListMap
The ConcurrentSkipListMap class (present in java.util.concurrent) is an implementation class of ConcurrentNavigableMap interface and has been present since Java version 1.6. It has the following features:
- By default, the elements are sorted based on the natural sorting order of keys. The ordering of keys can be customized using a Comparator provided during the initialization of the map.
- It is thread-safe and can access by multiple threads concurrently.
- It uses a concurrent variation of SkipList data structure providing
log(n)time cost for insertion, removal, update, and access operations. - It is better than ConcurrentHashMap for searching elements.
- It does not allow
NULLkeys and values. - It returns Map views that are snapshots of mappings when they were produced. These views do not support the Entry.setValue() method.
In Java Collections, the class has been declared as follows:
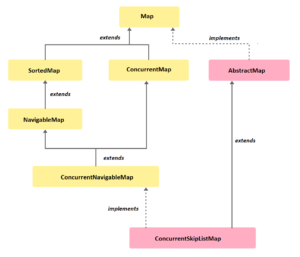
public class ConcurrentSkipListMap<K,V>
extends AbstractMap<K,V>
implements ConcurrentNavigableMap<K,V>, Cloneable, Serializable { ... }The class hierarchy of ConcurrentSkipListMap is as follows:
2. What is a Skip List?
A Skip List is a data structure that allows efficient search, insertion and deletion of elements in a sorted list. This is built using multiple sequences of layers where the lowest layer links all the elements by a LinkedList and the subsequent higher layers skip some elements in between the list.
It means the highest layer contains the least number of elements in the linked sequence. The elements that are skipped in between are chosen probabilistically.
Let’s say we have a LinkedList having some nodes, and if we want to search for a particular element in this list. In the worst-case scenario, we have to traverse all elements starting from the first node and follow all the pointers to the last one where we get the match. This corresponds to O(n) time complexity in the worst-case scenario in a LinkedList.

Let’s suppose we add a pointer two nodes ahead to every other node, starting from the first node, we can skip two nodes at a time, so we won’t have to visit more than n/2 nodes in the worst case before we either find the number we want or to conclude the element is not there in the list.

Similarly, we can give every node a pointer four nodes ahead of it for higher levels. As a result, the number of nodes we have to visit in the worst case would be approximately n/4. In general, if every 2^k-th node has a pointer to the node 2^k nodes ahead of it, we can reduce the number of nodes we have to examine in the worst-case search scenario to O(log n) time complexity.
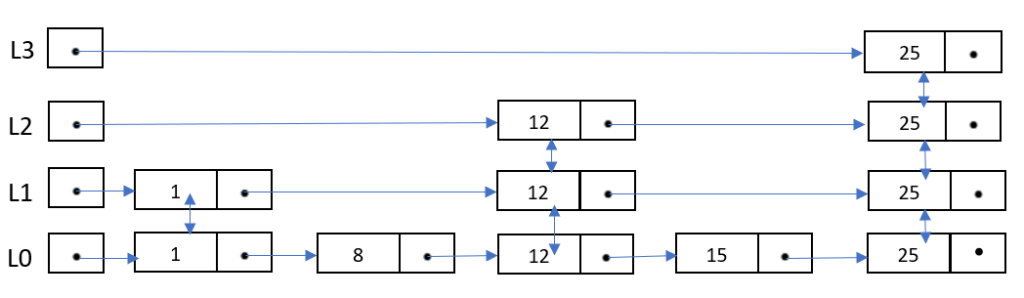
The main idea behind Skip List is to allow quick traversal to the desired element, reducing the average number of steps needed to reach it. Hence it provides log(n) time complexity for the basic operations.
3. Map Initialization
We can create a new instance using one of the following constructors. The default constructor creates a new, empty map, using the natural ordering of its keys. We can customize the order by passing an argument Comparator.
To create an instance with existing Map entries, pass the map to the constructor. It Map supports the sorting behavior, the keys will be sorted as the specified argument map.
ConcurrentSkipListMap()
ConcurrentSkipListMap(Comparator comparator)
ConcurrentSkipListMap(Map m)
ConcurrentSkipListMap(SortedMap m)The following program creates an instance and puts key-value pairs in random order, but the Map sorts the entries by keys in the natural order.
ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();
map.put(2, "B");
map.put(1, "A");
map.put(3, "C");
System.out.println(map); //{1=A, 2=B, 3=C}4. Useful Operations
4.1. Floor and Ceiling Keys
In addition to supporting the standard Map operations such as get(), put(), remove() etc., ConcurrentSkipListMap supports finding the lower/higher keys and entries. It also supports finding the floor/ceiling keys and entries.
firstKey(): returns the first (least) key currently in the map.lastKey(): returns the last (greatest) key currently in the map.ceilingKey(key): returns the least key greater than or equal to the given key, or null if no such key exists.higherKey(key): returns the least key strictly greater than the specified key.lowerKey(key): returns the greatest key strictly lesser than the specified key.floorKey(key): returns the greatest key lesser than or equal to the given key, or null if no such key exists.
It is worth knowing the difference between these keys. For example, if we pass a key that is not present in the Map then ceilingKey/lowerKey and floorKey/higherKey will return the same values. But if the argument key is present in the Map, floorKey/ceilingKey will return the same key, always, but higherKey/lowerKey will strictly return the next/previous key in order.
ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(4, "D");
map.put(5, "E");
System.out.println(map.ceilingKey(3)); //4
System.out.println(map.higherKey(3)); //4
System.out.println(map.ceilingKey(4)); //4
System.out.println(map.higherKey(4)); //54.2. Head Map and Tail Map
The headMap() and tailMap() methods can be used to return a view of the portion of this Map whose keys are less/greater than the specified argument key.
ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.put(4, "D");
map.put(5, "E");
System.out.println(map.headMap(3)); //{1=A, 2=B}
System.out.println(map.tailMap(3)); //{3=C, 4=D, 5=E}5. Comparison with Other Maps
5.1. Difference between ConcurrentHashMap and ConcurrentSkipListMap
- ConcurrentHashMap is not a NavigableMap nor a SortedMap, but ConcurrentSkipListMap is both a NavigableMap and a SortedMap.
- ConcurrentSkipListMap uses Skip List as its internal data structure, whereas CocurrentHashMap uses HashTable & lock-striping internally.
- ConcurrentHashMap is generally faster for most of its operations, making it suitable for applications requiring high performance and throughput, wherein ConcurrentSkipListMap provides
O(logn)time complexity for most of its operations. - ConcurrentHashMap provides a map that is not sorted, whereas ConcurrentSkipListMap provides a sorted map based on the default natural sorting order of keys or as specified by Comparator.
- ConcurrentHashMap allows modification of the number of threads to tune the concurrency behavior, wherein ConcurrentSkipListMap does not allow to modify of the concurrent thread count.
5.2. Difference between TreeMap and ConcurrentSkipListMap
- TreeMap was introduced in Java version 2.0, whereas ConcurrentSkipListMap was introduced in Java version 6.0.
- TreeMap is not synchronized, whereas ConcurrentSkipListMap is synchronized and can be accessed in a multi-threaded environment.
- Performance-wise TreeMap performs better as compared to ConcurrentSkipListMap, as TreeMap is not synchronized so multiple Threads can operate on a TreeMap which reduces the waiting time of the threads and improves performance.
- The iterator of TreeMap is fail-fast and can raise ConcurrentModificationException, whereas the iterator of ConcurrentSkipListMap is fail-safe and never raises the ConcurrentModificationException.
6. When to Use?
The ConcurrentSkipListMap offer average O(log(n)) performance on a wide variety of operations. So if you are not targeting peak performance in specific scenarios, you can use this class for good average performance for search operations. Also, it may not be useful in cases where too many add/remove operations are being done on the Map.
The special methods available in the class for finding floor/ceiling keys or head/tail maps can prove useful in certain situations where you need to get the submap backed by the original map such that any change will reflect in both maps.
7. Conclusion
This tutorial taught us about the Java ConcurrentSkipListMap class and its internals. We saw how it stores key-value pairs in a sorted manner – either in natural ordering (default) or in some custom ordering of keys (using provided Comparator). We have also covered its use cases and significant differences between ConcurrentSkipListMap and other Maps.
Happy Learning !!