
Amazon Simple Storage Service (S3) is a highly scalable and reliable object storage service provided by Amazon Web Services (AWS). With its easy-to-use API, S3 allows developers to store and retrieve objects seamlessly.
This Spring boot tutorial will explore working with S3 buckets and objects using the Spring Cloud AWS module.
1. Maven
To simplify dependency management, we will use Spring Cloud AWS’s Bill of Materials (BOM). The BOM is a curated list of dependencies and their corresponding versions that are known to work well together in a specific release of Spring Cloud AWS.
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.awspring.cloud</groupId>
<artifactId>spring-cloud-aws-dependencies</artifactId>
<version>3.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Further, we include the latest versions of spring-cloud-aws-starter and spring-cloud-aws-starter-s3 dependencies in a Spring boot application.
<dependency>
<groupId>io.awspring.cloud</groupId>
<artifactId>spring-cloud-aws-starter</artifactId>
</dependency>
<dependency>
<groupId>io.awspring.cloud</groupId>
<artifactId>spring-cloud-aws-starter-s3</artifactId>
</dependency>2. Different ways to Connect to S3
To perform operations on S3 objects using the library, there are the following approaches available:
- S3Client: The
S3Clientprovides a low-level API for interacting with AWS S3 services. It allows us to directly call methods to create buckets, upload objects, download objects, delete objects, list objects, and perform other S3 operations. By using S3Client, you have fine-grained control over the S3 operations. However, it requires more manual handling of the request and response objects. - CrossRegionS3Client: The implementation of S3Client provided in the AWS SDK is specific to a particular region. This means that it can only be used to perform operations on buckets and objects stored in that specific region. To address this limitation, Spring Cloud AWS introduces a CrossRegionS3Client, which solves the problem by maintaining an internal dictionary of S3Client objects for each region.
- S3Template: The third approach is to use S3Template, which is a higher-level abstraction provided by Spring Cloud AWS 3.x. The S3Template builds on top of the
S3Clientand offers a more streamlined and simplified API for working with S3.
3. Using S3Client
Let us begin by configuring S3Client and providing the required parameters, including the region, security credentials, and other necessary configurations.
3.1. S3Client Bean Configuration
Start with adding the aws.accessKeyId, aws.secretKey, and aws.region.static properties.
aws.accessKeyId=${AWS_ACCESS_KEY_ID}
aws.secretKey=${AWS_SECRET_KEY}
aws.region.static=${AWS_REGION}The properties are typically defined in the application.properties file. However, to enhance the security of these sensitive values, it is recommended to use environment variables instead. Using environment variables, we can separate the sensitive information from the application’s codebase and keep it securely stored in an environment where the application is deployed. This approach helps to prevent accidental exposure of credentials and ensures better security practices.
Next, we can inject these properties into the S3Client builder to create a bean that can connect to a specified region using the specified credentials.
@Configuration
public class S3Config {
@Value("${aws.accessKeyId}")
private String accessKey;
@Value("${aws.secretKey}")
private String secretKey;
@Value("${aws.region.static}")
private String region;
@Bean
public S3Client s3Client() {
return S3Client.builder()
.region(Region.of(region))
.credentialsProvider(StaticCredentialsProvider.create(AwsBasicCredentials.create(accessKey, secretKey)))
.build();
}
}
Now we can autowire or inject the S3Client into a service or controller similar to other Spring beans.
@Service
public class S3Service {
@Autowired
S3Client s3Client;
//...
}3.2. Creating a New Bucket
Creating a bucket in S3 is straightforward using the createBucket() method. To do this, we need to provide the bucket’s name in a CreateBucketRequest object. This request is then sent to the S3 service, creating a new bucket with the specified name.
When creating an S3 bucket, it is essential to remember that the bucket name must be unique globally. This means no other user in any AWS region can have a bucket with the same name. It’s crucial to choose a unique bucket name to avoid conflicts.
CreateBucketRequest createBucketRequest = CreateBucketRequest.builder()
.bucket("howtodoinjava02")
.build();
s3Client.createBucket(createBucketRequest);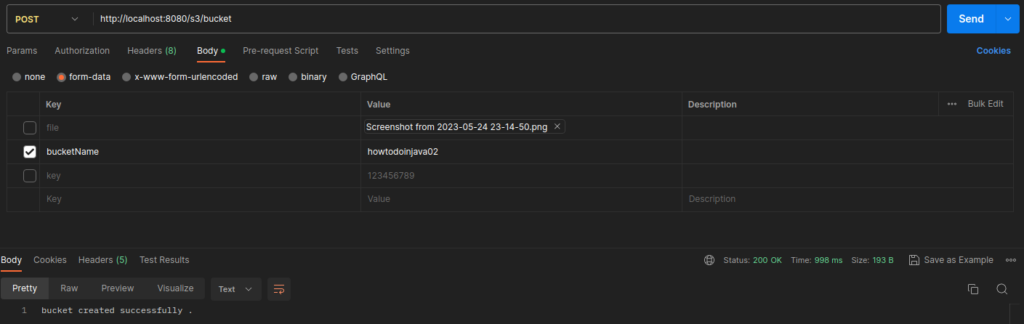
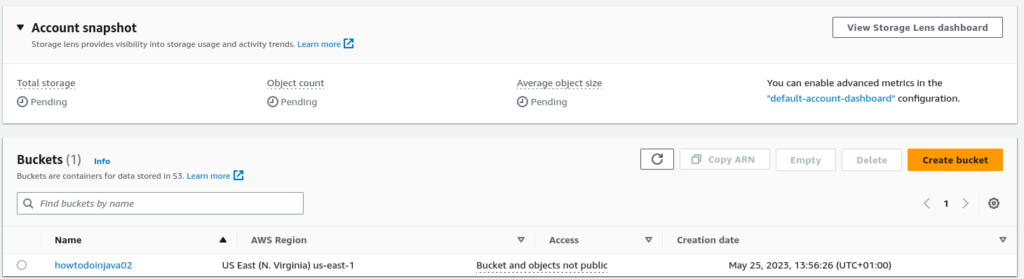
If you visit your AWS console, you will see that your bucket has been successfully created.
3.3. Uploading Objects to S3
Uploading objects to S3 is a seamless process using the putObject() method. To upload an object, we specify the bucket name, the desired key (object name), and the file or input stream representing the object’s data. The PutObjectRequest encapsulates these details and is sent to the S3 service, initiating the upload process.
byte[] bytes = file.getBytes(); //Multipart file uploaded on server
InputStream inputStream = new ByteArrayInputStream(bytes);
PutObjectRequest putObjectRequest = PutObjectRequest.builder()
.bucket("howtodoinjava02")
.key("123456789")
.build();
s3Client.putObject(putObjectRequest, RequestBody.fromInputStream(inputStream, bytes.length));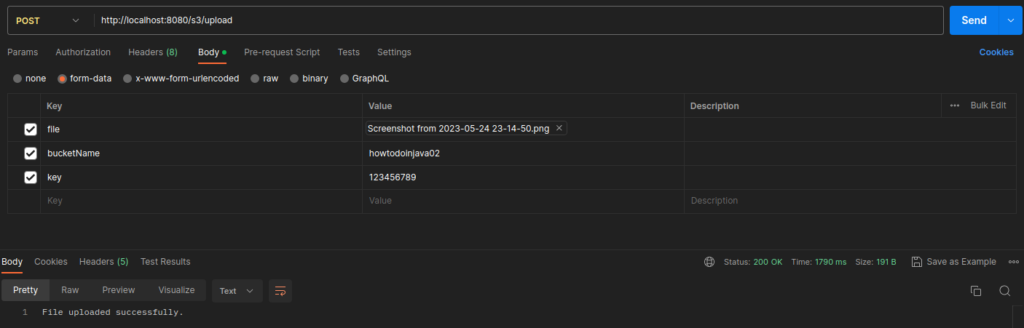
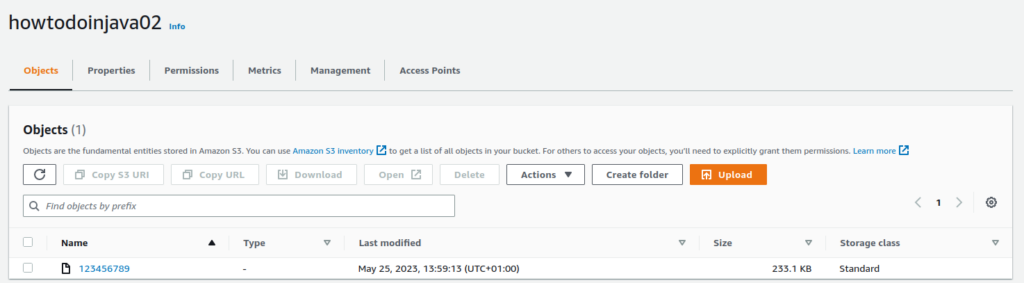
If you visit your AWS console, you will see that your object has been successfully uploaded.
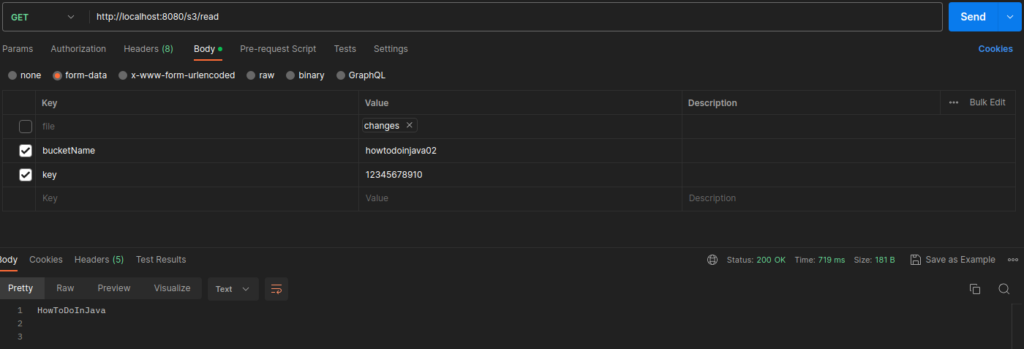
3.4. Reading an Object from S3
To read a file from AWS S3 using the S3Client and GetObjectRequest, you can follow these steps:
- Create an instance of
GetObjectRequestwith the bucket name and the key of the object you want to read. - Invoke the
S3Client.getObject()method with theGetObjectRequestto retrieve the file. - Read the bytes from the returned ResponseInputStream .
GetObjectRequest getObjectRequest = GetObjectRequest.builder()
.bucket("howtodoinjava02")
.key("123456789")
.build();
ResponseInputStream response = s3Client.getObject(getObjectRequest);
return new String(response.readAllBytes());In this example, the readFileFromS3 method takes the bucket name and object key as parameters. It creates a GetObjectRequest and invokes s3Client.getObject() to retrieve the file as a ResponseInputStream. The file content is then read from ResponseInputStream object using readAllBytes() method .
3.5. Deleting Objects from S3
Deleting objects from an S3 bucket is achieved by calling the deleteObject() method. We need to provide the bucket name and the key (object name) of the object to be deleted. The DeleteObjectRequest encapsulates these details and is sent to the S3 service, initiating the deletion process.
DeleteObjectRequest deleteObjectRequest = DeleteObjectRequest.builder()
.bucket("howtodoinjava02")
.key("123456789")
.build();
s3Client.deleteObject(deleteObjectRequest);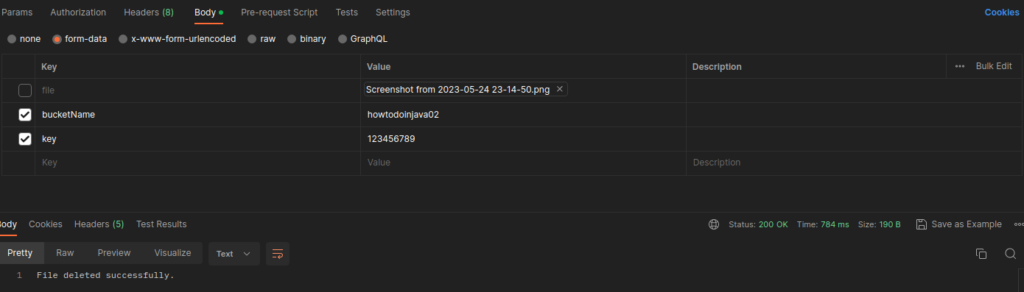
If you visit your AWS console, you will see that your object has been successfully deleted.
Similarly, we can perform other actions on S3 buckets and objects. For a detailed list of supported actions, refer to Java Docs.
4. Using S3Template
The S3Template is a high-level API on top of S3Client and offers a comprehensive set of methods for creating and deleting buckets and objects. It works similarly to other template beans such as JdbcTemplate, RestTemplate, etc.
4.1. S3Template Bean
To start working with S3Template, we need to create a bean based on S3Client and configure some additional settings. In the following configuration, we use the InMemoryBufferingS3OutputStreamProvider and Jackson2JsonS3ObjectConverter.
- The InMemoryBufferingS3OutputStreamProvider is used to provide InMemoryBufferingS3OutputStream that buffers content to an internal ByteArrayOutputStream and streams the content as a MultiPartUpload as the buffer fills up.
- The Jackson2JsonS3ObjectConverter is Jackson-based implementation of S3ObjectConverter. It serializes/deserializes objects to/from JSON.
- The S3Presigner enables signing an S3 SdkRequest so that it can be executed without requiring any additional authentication on the part of the caller.
@Configuration
public class AwsConfig {
@Bean
public S3Client s3Client() {
//...
}
@Bean
public S3Template s3Template() {
return new S3Template(s3Client(),
new InMemoryBufferingS3OutputStreamProvider(s3Client(), null),
new Jackson2JsonS3ObjectConverter(new ObjectMapper()),
S3Presigner.create());
}
}4.2. Supported Operations
The following code lists some frequently used methods to interact with S3 buckets/objects. For the complete list of supported methods, refer to the documentation.
public String createBucket(String bucketName);
public void deleteBucket(String bucketName);
public void deleteObject(String bucketName, String key);
public S3Resource store(String bucketName, String key, Object object);
public <T> T read(String bucketName, String key, Class<T> clazz)
public S3Resource upload(String bucketName, String key, InputStream inputStream,
@Nullable ObjectMetadata objectMetadata) ;4.3. S3Template Example
Let us perform a few operations using the S3Template. We
String bucketName = "howtodoinjava02";
String objectKey = "123456789";
MultiPartFile file = ...; //Uploaded file
// Create a bucket
String createdBucketLocation = s3Template.createBucket(bucketName);
// Store an object
InputStream objectContentStream = new ByteArrayInputStream(file.getBytes());
S3Resource storedResource = s3Template.upload(bucketName, objectKey, objectContentStream, null);
// Delete the object
s3Template.deleteObject(bucketName, objectKey);
// Delete the bucket
s3Template.deleteBucket(bucketName);5. POJO Serialization/Deserialization
The S3Template also allows storing and retrieving serialized Java objects:
- store(String bucketName, String key, Object object): stores an object in the specified
bucketNamewith the givenkey. Theobjectis converted using the S3ObjectConverter and then uploaded to S3 using the S3Client. It returns an S3Resource object representing the stored resource. - read(String bucketName, String key, Class<T> clazz): reads an object from the specified
bucketNamewith the givenkey. The object is retrieved from S3 as an input stream using the S3Client. It is then converted to the specifiedclazzusing the S3ObjectConverter and returned.
String bucketName = "howtodoinjava02";
Student student = new Student("John", "Doe" , 22);
// store
s3Template.store(bucketName, "student.json", student);
// retrieve
Student loadedStudent = s3Template.read(bucketName, "student.json", Student.class);By default, S3Template uses ObjectMapper (from Jackson) to convert from S3 object to Java object and vice versa.
6. S3 Object as Spring Resource
With the integration of S3Resource, developers can leverage the familiar Spring Resource API to interact with S3 objects using S3 URLs. For instance, by using the @Value annotation, we can inject an S3Resource in the application:
@Value("s3://bucket_name/object_key")
Resource resource;The above code creates a Resource object that provides a high-level abstraction for reading, writing, and managing the S3 object. Further, we can read the content of the S3 object by obtaining an input stream from the resource:
@Value("s3://bucket_name/object_key")
private Resource s3Resource;
//Read resource content
public String getResource() throws IOException {
try (InputStream inputStream = s3Resource.getInputStream()) {
return new String(inputStream.readAllBytes());
}
}7. Conclusion
AWS S3 is an exceptionally reliable and scalable cloud storage solution offered by Amazon. It provides secure and durable object storage for several types of data, such as images, videos, documents, and backups. In this article, we have explored the fundamentals of working with S3 buckets and objects using Spring Cloud AWS library and its S3Client and S3Template classes.
Happy Learning !!