
GraphQL is an API query language and a server-side runtime for querying and updating the existing data stored in any kind of data storage. It was initially developed by Facebook and later moved to open source GraphQL Foundation. In this tutorial, we will learn to configure GraphQL support in Spring boot-based APIs.
1. Introduction to GraphQL
GraphQL is an API query language and a server-side runtime for executing queries on the existing data stored in any kind of data storage. It is an alternative to REST and other web service architectures. Like REST APIs, GraphQL is not tied to any specific database or storage engine.
- GraphQL is statically typed, enabling developers to ask exactly what data is needed and get back the expected results. This also means the server knows the exact shape of every object the client can query. It also allows for pulling data from multiple sources in a single call, thereby reducing the number of network calls.
- GraphQL also allows adding or deprecating fields without impacting existing clients, reducing the overhead of API versioning.
- On the client side, we use a library that implements the GraphQL standard in the programming language of our choice. On the server side, we have a GraphQL API server that listens to the client requests and parses and fetches the requesting data.
- Many tools and libraries support GraphQL in a wide range of languages like Java, JavaScript, Ruby etc. We can find an exhaustive list on their page.
2. GraphQL Schema
A GraphQL schema describes what kind of objects can be returned and what fields we can query in the API. The schema consists of type definitions. Whenever a query comes to the GraphQL server, it is validated against this schema and then executed to produce the results.
Let’s take a look at some of the types that make up a GraphQL schema.
2.1. Object Types and Fields
Object types represent the kind of objects we can fetch from our API and what fields it has. The Book object we used in our earlier queries can be defined as follows:
type Book {
id: ID!
title: String
pages: Int
author: Author
}Bookis the GraphQL Object Type, meaning it is a type with some fields defined.id,title,pagesandauthorare the fields on theBookobject type. These are the fields that can be queried in the API.String,IntandIDare the built-in scalar types. We will look into scalar types shortly.!notifies a non-nullable field. This promises that the GraphQL service will always return back a value for this field when queried. In ourBooktype, theIDfield is non-nullable.
2.2. Arguments
Each field on an Object type can have zero or more arguments. All arguments in GraphQL are named and are passed by name. This means the order of argument definitions does not matter. Arguments can be either optional or mandatory. In the case of optional arguments, we can define a default value that is passed if the argument value is not passed.
Let’s see an Book object type:
type Book {
id: ID!
title: String
pages: Int
author: Author
width(unit: Unit = MM): Float
}In this case, the width the field has one argument called unit. If the unit argument is not passed, it is set to MM by default.
2.3. Scalar Types
Scalar types represent the query leaves, meaning they cannot have sub-fields. GraphQL comes with the following set of scalar types:
Int: A signed 32-bit integerFloat: A signed double-precision floating-point valueString: A UTF‐8 character sequence.Boolean: It can be withertrueorfalse.ID: A unique identifier.
2.4. Enumeration Types
Enumeration or Enums are a special kind of scalar in which a particular set of values are only allowed. For example, an enum definition for days of a week could be defined as
enum DaysOfWeek {
SUNDAY
MONDAY
TUESDAY
WEDNESDAY
THURSDAY
FRIDAY
SATURDAY
}3. GraphQL Queries and Mutations
GraphQL defines its own Query language we refer to as Domain Specific Language (DSL). From the client’s perspective, there can be two main types of operations:
- query
- mutation
3.1. Query
These are analogous to CRUD operations. A query is used to read data (GET in REST), and a mutation is used to create, update or delete data (PUT, DELETE or POST in REST).
A GraphQL query visually looks like a JSON, but it’s not. It is a simple request to fetch specific fields on an object. A simple query to fetch books and their authors would look like this below:
query BooksAndAuthors {
allBooks {
id
title
pages
author {
name
}
}
}Let’s break this down
- query: A keyword that specifies the operation type. It is optional.
- BooksAndAuthors: Specifies the operation name. Again, it is optional but should be included for ease in logging and debugging issues.
- The remaining part of the request says we need the title, pages and author for the books. And for the author, we need the name.
Since the operation type and name are optional, we can specify the same query as below
{
allBooks {
id
title
pages
author {
name
}
}
}We can even pass arguments to fields in a request. If we want to fetch a book by an id we can do the same.
{
bookById(id: 1) {
id
title
pages
author {
name
}
}
}This would return a book whose id matches with the one specified in the argument.
3.2. Mutation
A mutation is used for creating, updating or deleting data. Like queries, if a mutation returns back an object, we can ask for nested fields. For example, to update a book object, we can specify a mutation as follows:
mutation {
updateBook(id: 1, title: "GraphQL Overview Revised Edition") {
id
title
pages
author {
name
}
}
}Here we update a book using the id specified and return back the book object which is updated.
4. Setting up GraphQL with Spring Boot
We will create a simple Book API application using GraphQL and Spring Boot.
4.1. Maven Dependencies
Let us configure GraphQL in our Spring Boot application by adding the spring-boot-starter-graphql dependency in our pom.xml. Using the starter we can get a GraphQL server running quickly.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-graphql</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>We also included the Web starter dependency to expose the GraphQL APIs over the '/graphql' endpoint.
4.2. Creating GraphQL Schema
Schema files can have extensions “.graphqls” or “.gqls“. By default, GraphQL starter looks for schema files under src/main/resources/graphql. We can customize the schema location by adding spring.graphql.schema.locations in application.properties.
spring.graphql.schema.locations=/graphql-schemaIn our Book application, we will have two object types: Book and Author. We will have two queries to get all books and get a book by the identifier. We will also include a mutation to update a book. Here is what our schema.graphqls file will look like.
# Type definition
type Book {
id: ID!
title: String
pages: Int
author: Author
}
# Type definition
type Author {
name: String
}
# Queries to retrive all books, and a book by id
type Query {
allBooks: [Book]
bookById(id: ID!): Book
}
# Query to update a book by id
type Mutation {
updateBook(id: ID!, title: String): Book
}4.3. Creating Model and Repository
Each object type in the GraphQL schema would map to a corresponding Java object. In our case, we will have two Java objects: Book and Author having fields similar to what we defined in the schema.
class Book {
Integer id;
String title;
Integer pages;
Author author;
}
class Author {
String name;
}Let’s create a BookRepository which will connect to our backend database for query resolution. For simplicity, we will create our own static data.
@Component
public class BookRepository {
private static List<Book> books;
static {
Book book1 = new Book(1, "GraphQL Overview", 100, new Author("Amit"));
Book book2 = new Book(2, "Spring Overview", 100, new Author("Lokesh"));
books = List.of(book1, book2);
}
public List<Book> allBooks() {
return books;
}
public Book bookById(Integer id) {
for (Book book : books) {
if (book.getId() == id)
return book;
}
return null;
}
public Book updateBook(Integer id, String title) {
Book book = bookById(id);
if (book != null) {
book.setTitle(title);
}
return book;
}
}5. Query, Mutation and Field Mappings
GraphQL defines a number of annotations that help in mappings.
5.1. @SchemaMapping
The @SchemaMapping is used to map a handler method to a type and field pair. It takes in two arguments: typeName and value.
typeName: It is the operation Query or Mutation. It can be defined at the class or method level.value: It is the name of the field as its defined in the GraphQL schema. If not specified, defaults to the method name.
To map the “allBooks” query to a handler method, we could define it as follows:
@SchemaMapping(typeName = "Query", value="allBooks")
public List<Book> getAllBooks() {
return bookRepository.allBooks();
}5.2. @QueryMapping
@QueryMapping is a composite annotation to indicate the typeName as Query.
Let’s define the ‘bookById’ query handler method. This query takes an ID argument. This can be defined using the @Argument annotation which binds a named GraphQL argument onto a method parameter.
@QueryMapping
public Book bookById(@Argument Integer id) {
return bookRepository.bookById(id);
}5.3. @MutationMapping
As the name indicates, @MutationMapping is a composite annotation for Mutation types.
@MutationMapping
public Book updateBook(@Argument Integer id, @Argument String title) {
return bookRepository.updateBook(id, title);
}6. How to Test the APIs?
Run the Spring Boot Application. GraphQL APIs would be exposed by default at localhost:8080/graphql. We would need an API testing tool like Postman to test the APIs.
To test the allBooks query, we can use the following payload in a POST query:
{
allBooks {
id
title
pages
author {
name
}
}
}The postman query should be similar to the below snippet.
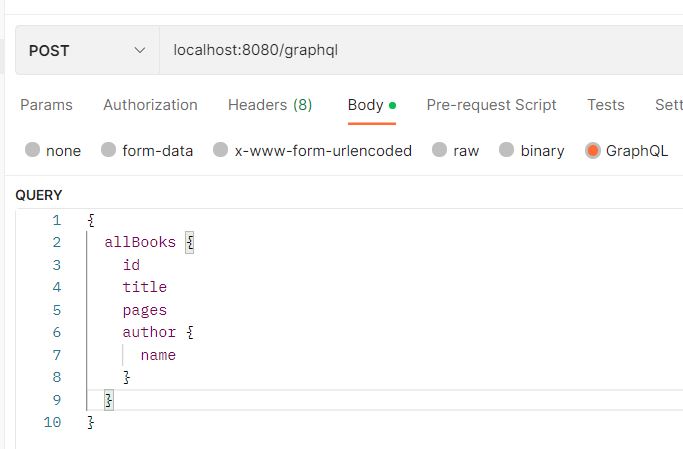
Likewise, to test the bookById query, we can use the following payload
{
bookById(id: 10) {
id
title
pages
author {
name
}
}
}The payload to test our mutation would be:
mutation {
updateBook(id:2, title: "Java World v3") {
id
title
pages
}
}7. Advance Configurations
7.1. Using Querydsl
Querydsl is a Java framework that allows for the generation of type-safe queries in a syntax similar to SQL. GraphQL starter supports the use of QueryDSL to fetch data. Querydsl provides a flexible yet typesafe approach to express query predicates by generating a meta-model using annotation processors.
public interface BookRepository
extends Repository<Book, Long>, QuerydslPredicateExecutor<Book> { }Then use it to create a DataFetcher:
DataFetcher<Iterable<Book>> dataFetcher = QuerydslDataFetcher.builder(repository).many(); Note that if a repository is annotated with @GraphQlRepository, it is automatically registered for queries whose return type matches that of the repository domain object.
7.2. Error Handling
Error handling is a core component of any API. Users of the API must be notified properly of the errors, if any, in the API response. GraphQL specification states every request must have a well-formed response containing data, errors and extensions. If no error occurred, the error component in the response will be absent.
We can have two types of errors:
- Request Errors: This means an issue with the request itself, either a parsing failure or an invalid request.
- Field Errors: This means either there was an exception in the value resolution of the field or an unexpected type for the specified field. In such cases, we may have partial responses along with errors.
By default, Spring for GraphQL has a built-in exception handler DataFetcherExceptionHandler. It allows our applications to register one or more DataFetcherExceptionResolver components. These resolvers are invoked sequentially until one resolves the exception to the GraphQLError object. If none of them can handle the exception, then the exception is categorized as INTERNAL_ERROR.
A GraphQLError object can be assigned to a category via graphql.ErrorClassification. In Spring GraphQL, you can also assign via ErrorType which has the following common classifications that applications can use to categorize errors:
BAD_REQUESTUNAUTHORIZEDFORBIDDENNOT_FOUNDINTERNAL_ERROR
To create a custom exception resolver, we can implement the DataFetcherExceptionHandler interface.
@Component
public class CustomDataFetchingExceptionHandler implements DataFetcherExceptionHandler {
@Override
public CompletableFuture<DataFetcherExceptionHandlerResult> handleException(DataFetcherExceptionHandlerParameters handlerParameters) {
if (handlerParameters.getException() instanceof MyException) {
Map<String, Object> debugInfo = new HashMap<>();
debugInfo.put("somefield", "somevalue");
GraphQLError graphqlError = TypedGraphQLError.newInternalErrorBuilder()
.message("This custom thing went wrong!")
.debugInfo(debugInfo)
.path(handlerParameters.getPath()).build();
DataFetcherExceptionHandlerResult result = DataFetcherExceptionHandlerResult.newResult()
.error(graphqlError)
.build();
return CompletableFuture.completedFuture(result);
} else {
return DataFetcherExceptionHandler.super.handleException(handlerParameters);
}
}
}Additionally, since Spring boot 3.1, We can define @GraphQlExceptionHandler methods to handle exceptions either in a @Controller or @ControllerAdvice annotated class. When declared in a controller, exception handler methods apply to exceptions from the same controller:
@Controller
public class BookController {
@QueryMapping
public Book bookById(@Argument Long id) {
// ...
}
@GraphQlExceptionHandler
public GraphQLError handle(BindException ex) {
return GraphQLError.newError().errorType(ErrorType.BAD_REQUEST).message("...").build();
}
}When declared in an @ControllerAdvice, it applies for all the controllers in the application:
@ControllerAdvice
public class GlobalExceptionHandler {
@GraphQlExceptionHandler
public GraphQLError handle(BindException ex) {
return GraphQLError.newError().errorType(ErrorType.BAD_REQUEST).message("...").build();
}
}7.3. Query Caching
Every GraphQL query must be parsed and validated before being executed. This may have some performance impact. To speed up this and avoid the need to re-parse and validate, we can configure the PreparsedDocumentProvider that caches and reuses Document instances.
@Component
public class CachingPreparsedDocumentProvider implements PreparsedDocumentProvider {
private final Cache<String, PreparsedDocumentEntry> cache = Caffeine
.newBuilder()
.maximumSize(2500)
.expireAfterAccess(Duration.ofHours(1))
.build();
@Override
public PreparsedDocumentEntry getDocument(ExecutionInput executionInput,
Function<ExecutionInput, PreparsedDocumentEntry> parseAndValidateFunction) {
return cache.get(executionInput.getQuery(),
operationString -> parseAndValidateFunction.apply(executionInput));
}
}In order to achieve a high cache hit ratio it is recommended that field arguments are passed in as variables instead of directly in the query.
8. Using GraphiQL
GraphiQL is a graphical interactive in-browser GraphQL Integrated Development Environment (IDE). It is a powerful tool for learning and test out GraphQL queries. GraphiQL offers syntax highlighting, autocompletion, automatic documentation, and much more.
By default, GraphiQL is disabled. To enable add the following property.
spring.graphql.graphiql.enabled=trueRestart the Spring Boot application and navigate to http://localhost:8080/graphiql on your browser. It should open up the GraphiQL window.
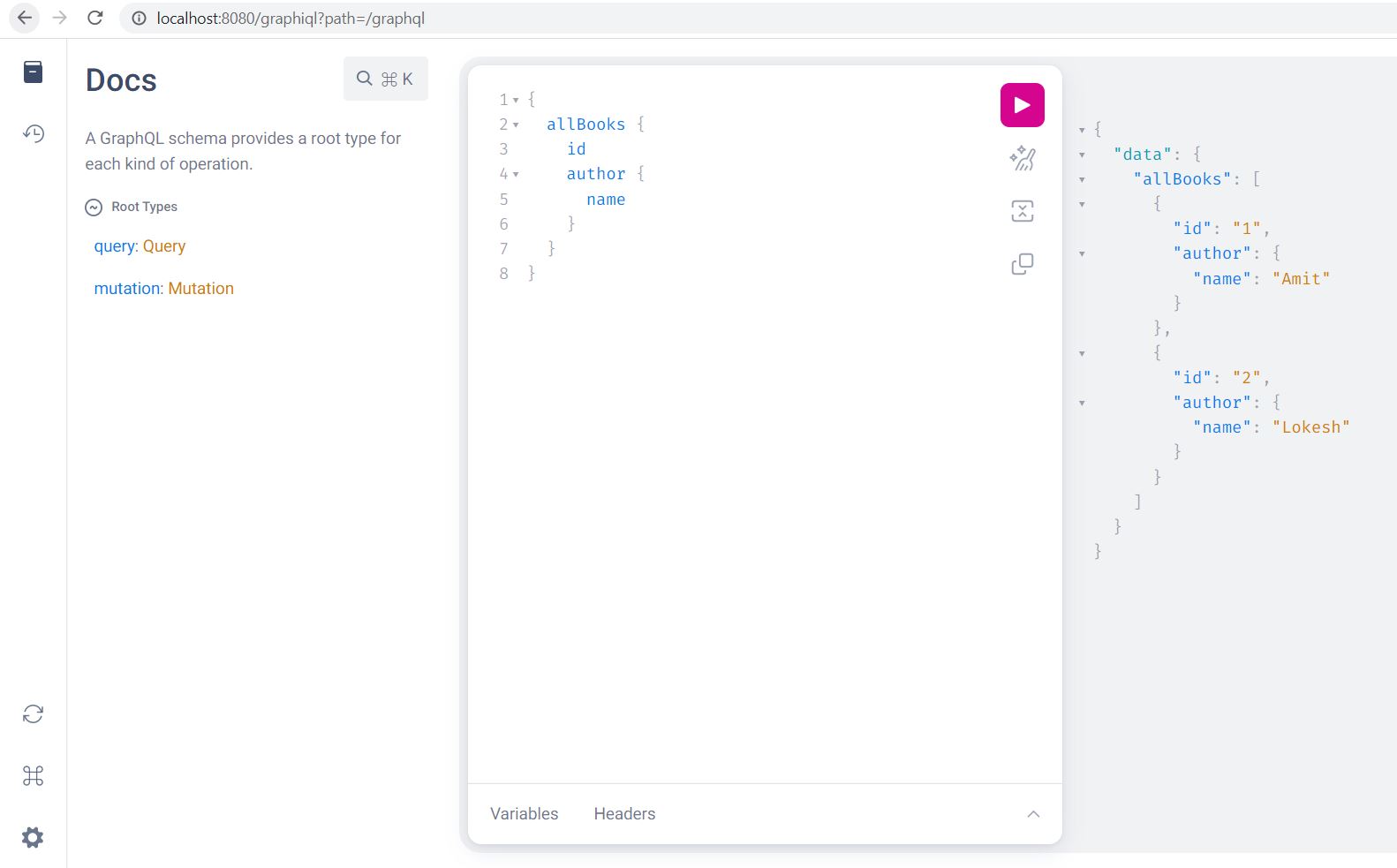
9. Conclusion
In this Spring tutorial for beginners, we learned about the core concepts of GraphQL and how to run a sample Spring Boot application with GraphQL integrated for querying and updating the data. We Also learned to write GraphQL schema types, queries and mutations with examples. In the end, we learned to configure some advanced options such as data caching, custom error handling and automatic type detections.
Happy Learning!!
Can we have an example to consume GQL all.
An example is given in @SchemaMapping section. Are you looking for anything else.